摘要
近年来,我们见证了通用模型在自然语言处理领域的巨大成功。通用模型是一种以海量数据进行训练的通用框架,能够同时处理多种下游任务。在其卓越性能的激励下,越来越多的研究者开始探索将这类模型应用于计算机视觉任务。然而,视觉任务的输入与输出形式更加多样化,难以将其归纳为统一的表示形式。本文对视觉通用模型进行了全面综述,深入探讨了其在该领域中的特性与能力。我们首先回顾了相关背景,包括数据集、任务类型以及评测基准。随后,我们梳理了现有研究中提出的模型框架设计,并介绍了用于提升模型性能的关键技术。为了帮助研究者更好地理解该领域,我们还简要探讨了相关研究方向,揭示了它们之间的关联性与潜在协同作用。最后,我们列举了一些真实世界的应用场景,深入分析了当前尚存的挑战,并对未来的研究方向提出了有益的见解。
关键词:基础模型 · 计算机视觉 · 多任务学习 · 多模态数据 1 引言
作为一种智能系统,人类大脑能够从不同的输入模态中感知信息,并能同时处理多种任务。类似于人类,在深度学习领域中,通用模型(generalist model)【Bae et al. (2022); Huang et al. (2023b); Jaegle et al. (2021a); Shukor et al. (2023)】是一种能够在无需为特定任务进行定制设计的前提下处理多种任务的通用框架。近年来,得益于大数据的强大驱动,大语言模型(LLMs)【Devlin et al. (2018); Ouyang et al. (2022); Peters et al. (2018)】在自然语言处理(NLP)领域中展现了通用模型的巨大成功。 然而,与 NLP 不同,视觉任务的输出格式更加多样且复杂。例如,传统的分类方法【He et al. (2016a); Russakovsky et al. (2015)】只需输出图像或点云的类别,而目标检测模型则需进一步定位目标,其输出为边界框(bounding boxes)。分割模型则需生成像素级的语义掩码。因此,对于视觉通用模型(Vision Generalist Models, VGM)【Hu and Singh (2021); Zhang et al. (2023c); Zhu et al. (2022c)】而言,设计一个能够适配广泛视觉下游任务的系统至关重要。 与传统神经网络相比,通用模型通常拥有数十亿个参数,并以海量数据进行训练,因而具备传统方法所不具备的诸多优秀特性。具体而言,视觉通用模型具备以下优势: 1)零样本多任务迁移能力(Zero-shot Multi-task Transfer)
传统方法往往为不同任务采用各自的任务特定框架,而多任务学习方法【Sener and Koltun (2018); Yu et al. (2020); Zhang and Yang (2021)】虽能同时处理多个任务,却难以在未经微调的情况下泛化到新的数据集。而通用模型在以任务无关的大规模数据预训练后,能够学习到通用表征,可直接扩展至多种下游任务,并具备零样本迁移能力,无需额外适配器进行微调,从而实现真正的通用感知(general perception)。 2)多模态输入(Multimodality Inputs)
通用模型的一大特性是能够接收来自不同模态的数据作为输入。由于各模态间存在巨大差异,统一编码为特征表示极具挑战。例如,图像为规则的二维矩阵,而点云则是无序的三维向量。这两类数据所使用的编码器也不同:分别为二维卷积与三维稀疏卷积【Graham et al. (2018); Yan et al. (2018)】。除了视觉信号,还需考虑文本、音频等其他模态,这进一步增加了处理难度。得益于 Transformer 架构【Vaswani et al. (2017b)】,部分工作将多模态输入统一为一系列 token 表示。 3)强大的表征能力(Great Representation Ability)
现有的通用模型往往拥有数十亿个参数。尽管计算代价高昂,但庞大的参数规模显著提升了模型的表征能力。多任务和多模态输入之间能够相互促进,进一步增强模型性能。 4)大数据的赋能(Power of Big Data)
大数据为模型训练提供了丰富的知识。例如,ChatGPT【Ouyang et al. (2022)】使用约 45TB 的文本数据进行训练。从不同模态和领域采集的大规模数据提升了样本多样性,从而增强了模型的泛化能力。大规模数据集【Chen et al. (2015); Krizhevsky et al. (2012)】涵盖了众多极端情况,有助于模型在复杂场景中稳定工作。 尽管视觉通用模型优势显著,但仍面临若干挑战: 1)框架设计(Framework Design)
通用模型的核心技术在于如何设计一个能够统一处理多种下游任务的框架。虽然已有一些工作【Hu and Singh (2021); Zhang et al. (2023c); Zhu et al. (2022c)】尝试解决这一问题,但目前尚未形成标准化的流程。因此,建立统一的视觉通用模型范式仍是当前最亟需解决的挑战。 2)数据获取(Data Acquisition)
通用模型的训练依赖于海量数据。在 NLP 领域,大量带标签的文本数据可从网页中获取;而在计算机视觉中,网络上的大多数视觉数据并未标注,获取标签代价高昂且耗时。有些研究【Kirillov et al. (2023b); Ouyang et al. (2022)】提出了针对特定任务的数据自动标注方法,但如何针对不同任务与模态实现自动化标注仍是一个尚未深入探索的问题。 3)伦理风险(Ethical Risks)
与大语言模型类似,视觉通用模型也面临伦理风险。在生成任务中,模型可能产生包含个人或敏感信息的内容,例如深度伪造视频【Güera and Delp (2018); Westerlund (2019)】;在判别任务中,训练数据中的无意识偏见可能会影响模型判断;此外,不当或非法数据的使用还可能引发法律问题。 在过去两年中,我们已见证通用模型在多个深度学习方向中的成功。随着神经网络架构的不断发展,越来越多的研究致力于构建能够实现通用感知的模型。尽管通用模型已引发广泛关注,但尚缺乏一篇系统性综述来全面总结这一热门方向,因此我们撰写了本文。 本综述的主要目的包括: 1. 对相关研究文献进行系统梳理,帮助研究者快速入门; 1. 总结现有方法的局限与挑战,并指出未来可能的研究方向; 1. 理清视觉通用模型与其他相关领域的联系与差异。
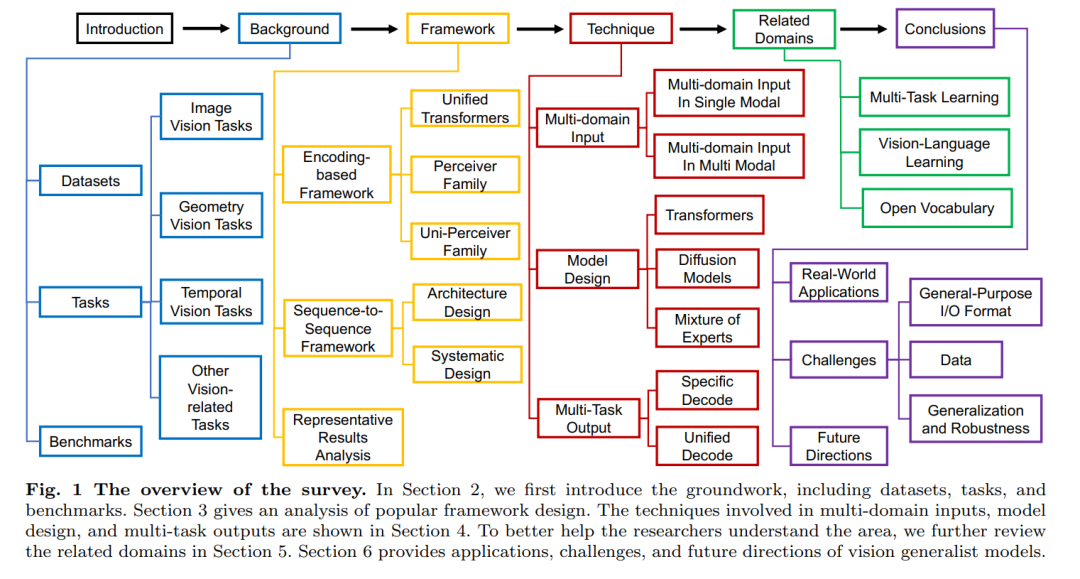
在相关工作方面,Awais 等人(2023)提供了一份关于视觉基础模型的综述。尽管视觉基础模型与通用模型同样是在大规模数据上进行训练,并能接收多模态输入,但通用模型还具备处理多任务的强泛化能力,而基础模型在适应下游任务时通常需要针对特定数据集进行微调,限制了其实用性。因此,我们的综述与 Awais 等人的工作在概念上存在显著差异,我们更加专注于总结通用模态感知与通用任务处理能力。 相比之下,另一篇综述【Li et al. (2023b)】从更宏观的视角出发,探讨了多模态基础模型的分类与演进,包括统一视觉模型、大语言模型及其在多模态智能体中的应用。而本文则更聚焦于视觉通用模型(VGM)这一子领域,深入剖析其框架设计与关键技术。 我们将本文组织为六个部分,以系统梳理视觉通用模型的发展,如图 1 所示: * 第2节:介绍 VGM 常用的任务类型、数据集与评测基准; * 第3节:深入分析 VGM 的框架设计,包括编码器驱动方法与序列到序列框架; * 第4节:总结应对多领域输入、模型设计和多任务输出的关键技术; * 第5节:探讨 VGM 与相关领域的联系,尤其是多任务学习、视觉-语言学习与开放词表学习; * 第6节:展示 VGM 的真实应用场景,并讨论其面临的挑战与未来发展方向。
我们希望本综述能为研究者和从业者提供一份关于视觉通用模型的系统性参考资料,助力其在这一快速发展的研究领域中取得突破。