

摘要 —— 深度估计是三维计算机视觉中的一项基础任务,对三维重建、自由视角渲染、机器人技术、自动驾驶以及增强/虚拟现实(AR/VR)等应用至关重要。传统方法依赖于诸如 LiDAR 等硬件传感器,常受制于高昂的成本、低分辨率以及对环境的敏感性,因而在真实场景中的适用性有限。近年来,基于视觉的方法取得了有前景的进展,但由于模型架构容量不足,或过度依赖领域特定且规模较小的数据集,这些方法在泛化能力与稳定性方面仍面临挑战。其他领域中“扩展法则(scaling laws)”与基础模型的发展,启发了“深度基础模型”的提出 —— 这类模型是基于大规模数据集训练的深度神经网络,具备强大的零样本泛化能力。本文系统回顾了单目、双目、多视图以及单目视频等多种设置下的深度估计相关深度学习架构与范式的演进,探讨这些模型在应对现有挑战方面的潜力,并全面整理了可用于支持其发展的大规模数据集。通过识别关键的模型架构与训练策略,我们旨在指明构建鲁棒深度基础模型的路径,并为其未来的研究与应用提供参考。
索引词 —— 深度估计,基础模型,三维计算机视觉
1 引言
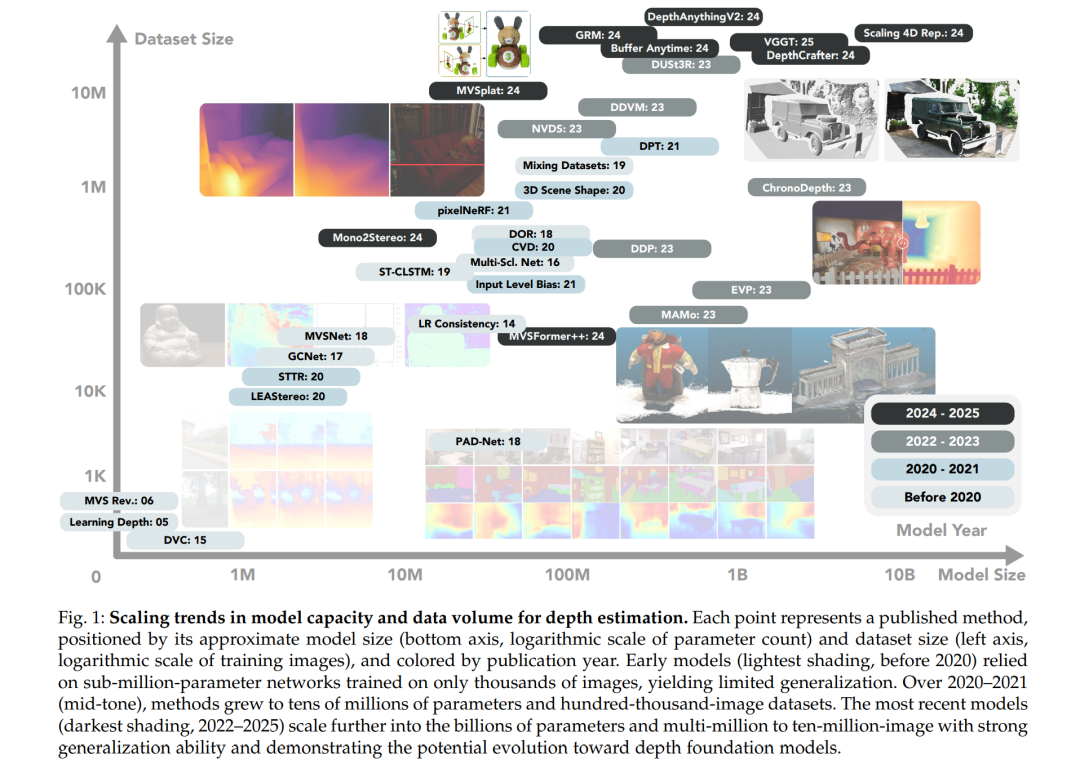
深度估计是三维计算机视觉领域的基石任务,长期以来一直是研究的焦点,其在三维重建、三维生成模型、机器人技术、自动驾驶以及增强/虚拟现实(AR/VR)等应用中发挥着关键作用。然而,现有算法往往难以实现类似人类感知的高质量和一致性的深度恢复。人类感知过程依赖于丰富的先验知识和对场景的世界理解,而传统算法在这方面仍存在显著差距。 传统的深度恢复方法通常依赖主动感知硬件,例如市售的 LiDAR、飞行时间(ToF)传感器以及超声波探测器。这些传感器通过测量光子或声波往返的时间来估计深度。尽管这些方法具有较高的精度,但其高昂的成本限制了广泛应用。此外,主动传感器常常存在分辨率低、噪声干扰严重等问题。例如,iPhone 上的 LiDAR 传感器仅能在有限距离范围内实现较低分辨率的三维重建,且对于极近或较远物体的测量精度较低。更进一步地,这些传感器对环境光线条件较为敏感,在户外强光场景中效果不佳。 近年来,基于视觉的深度估计方法逐渐受到关注。这类方法不依赖于主动深度感知硬件,而是利用日常设备中广泛配备的相机进行深度推理。与主动传感器方法相比,视觉方法成本低、深度范围无限制、不易受环境干扰、并可提供高分辨率。例如,一台标准的 iPhone 相机即可轻松获取 4K 分辨率的 RGB 图像。然而,现有基于视觉的深度估计算法仍面临诸多挑战。尤其是单目深度估计问题本质上是病态的,标准深度学习算法在该任务中难以获得高精度的结果。为了引入约束以减轻问题的病态性,研究人员探索了基于多相机输入或更丰富场景观测的信息进行深度估计的方法,如双目、多视图或视频序列下的深度估计。然而,这些方法往往依赖于小规模的合成数据进行训练,导致其在空间和时间域上的不稳定性,对不同场景与输入类型的泛化能力较差,且难以有效弥合合成数据与真实世界数据之间的域差距。 随着自然语言处理、图像生成与视频生成等领域中“扩展法则(scaling laws)”的验证与兴起,“基础模型(foundation models)”的概念应运而生。基础模型是指在大规模数据集上训练的深度神经网络,在多个领域中展现出突现的零样本泛化能力。为了实现类似的能力,研究者们关注训练数据的规模与多样性,借助其他领域的大规模模型,并巧妙构建自监督学习架构。我们将具备大规模数据吸收能力的可扩展深度估计模型定义为“深度基础模型(depth foundation models)”。这类模型覆盖包括单目、双目、多视图以及单目视频等多种深度估计任务,有潜力解决前述的泛化难题,并为计算机视觉领域的长期挑战提供关键解决方案。 本文旨在综述面向深度基础模型的演进过程,系统回顾在单目、双目、多视图以及单目视频设置下的深度估计范式与模型架构的发展: * 我们梳理了各类任务中深度学习模型架构与学习范式的发展,并识别出具有基础能力或潜力的关键范式; * 为推动深度基础模型的构建,我们还全面调查了各子领域中可用于训练的大规模数据集; * 此外,我们列举了各类任务中基础模型当前所面临的主要挑战,为未来研究提供启示与方向。
