地址:https://crad.ict.ac.cn/CN/10.7544/issn1000-1239.202110780
0. 引言
机器学习是一门研究如何设计算法、利用数据 使机器在特定任务上取得更优表现的学科,其中以 深度学习[1] 为代表的相关技术已成为人们研究实现 人工智能方法的重要手段之一.至今机器学习研究已 经取得大量令人瞩目的成就:在图像分类任务上的 识别准确率超过人类水平[2] ;能够生成人类无法轻易 识别的逼真图像[3] 和文本[4] ;在围棋项目中击败人类 顶尖棋手[5] ;蛋白质结构预测结果媲美真实实验结 果 [6] 等.目前机器学习在计算机视觉、自然语言处理、 搜索引擎与推荐系统等领域发挥着不可替代的作用, 相关应用涉及互联网、安防、医疗、交通和金融等众 多行业,对社会发展起到了有力的促进作用. 尽管机器学习研究获得了一系列丰硕的成果, 其自身的问题却随着应用需求的提高而日益凸显.机 器学习模型往往在给出预测结果的同时不会解释其 中的理由,以至于其行为难以被人理解[7] ;同时机器 学习模型还十分脆弱,在输入数据受到扰动时可能 完全改变其预测结果,即使这些扰动在人看来是难以 察觉的[8] ;机器学习模型还容易产生歧视行为,对不 同性别或种族的人群给予不同的预测倾向,即使这 些敏感特征不应当成为决策的原因[9] .这些问题严重 限制了机器学习在实际应用中发挥进一步的作用.造成这一系列问题的一个关键原因是对因果关 系的忽视.因果关系,指的是 2 个事物之间,改变一 者将会影响另一者的关系.然而其与相关关系有所不 同,即使 2 个事物之间存在相关关系,也未必意味着 它们之间存在因果关系.例如图像中草地与牛由于常 在一起出现而存在正相关关系,然而两者之间却没 有必然的因果关系,单纯将草地改为沙地并不会改 变图像中物体为牛的本质.机器学习的问题在于其模 型的训练过程仅仅是在建模输入与输出变量之间的 相关关系,例如一个识别图像中物体类别的机器学 习模型容易将沙地上的牛识别为骆驼,是因为训练 数据中的牛一般出现在草地上而沙地上更常见的是 骆驼.这种具备统计意义上的相关性却不符合客观的 因果规律的情况也被称为伪相关(spurious correlation). 伪相关问题的存在对只考虑相关性的机器学习模型 带来了灾难性的影响:利用伪相关特征进行推断的 过程与人的理解不相符,引发可解释性问题;在伪相 关特征发生变化时模型预测结果会随之改变从而导 致预测错误,引发可迁移性和鲁棒性问题;如果伪相 关特征恰好是性别和肤色等敏感特征,则模型决策 还会受到敏感特征的影响,引发公平性问题.忽视因 果关系导致的这些问题限制了机器学习在高风险领 域及各类社会决策中的应用.图灵奖得主 Bengio 指出, 除非机器学习能够超越模式识别并对因果有更多的 认识,否则无法发挥全部的潜力,也不会带来真正的 人工智能革命.因此,因果关系的建模对机器学习是 必要的,需求也是十分迫切的. **因果理论即是描述、判别和度量因果关系的理 论,由统计学发展而来.长期以来,由于缺乏描述因果 关系的数学语言,因果理论在统计学中的发展十分 缓慢.**直到 20 世纪末因果模型被提出后,相关研究才 开始蓬勃兴起,为自然科学和社会科学领域提供了 重要的数据分析手段,同时也使得在机器学习中应 用因果相关的技术和思想成为可能.图灵奖得 主 Pearl 将这一发展历程称为“因果革命” [10] ,并列举了 因果革命将为机器学习带来的 7 个方面的帮助[11] . 本文将在机器学习中引入因果技术和思想的研究方 向称为因果机器学习(causal machine learning).目前机 器学习领域正处于因果革命的起步阶段,研究者们 逐渐认识到了因果关系建模的必要性和紧迫性,而 因果机器学习的跨领域交叉特点却限制了其自身的 前进步伐.本文希望通过对因果理论和因果机器学习 前沿进展的介绍,为相关研究者扫清障碍,促进因果 机器学习方向的快速发展.目前针对因果本身的研究 已有相关综述文献 [12−14],内容主要涵盖因果发现 和因果效应估计的相关方法,但很少涉及在机器学习任务上的应用.综述文献 [15−16] 详细地介绍了因 果理论对机器学习发展的指导作用,着重阐述现有 机器学习方法的缺陷和因果理论将如何发挥作用, 但缺少对这一方向最前沿工作进展的整理和介绍, 而这正是本文重点介绍的内容.
1 因果理论简介
因果理论发展至今已成为统计学中的一个重要 分支,具有独有的概念、描述语言和方法体系.对于 因果关系的理解也已经不再仅停留在哲学概念的层 面,而是有着明确的数学语言表述和清晰的判定准 则.当前广泛被认可和使用的因果模型有 2 种:潜在 结果框架(potential outcome framework)和结构因果模 型(structural causal model, SCM).Splawa-Neyman 等 人 [17] 和 Rubin[18] 提出的潜在结果框架又被称为鲁宾 因果模型(Rubin causal model, RCM),主要研究 2 个 变量的平均因果效应问题;Pearl[19] 提出的结构因果 模型使用图结构建模一组变量关系,除了效应估计 也会关注结构发现问题.RCM 与 SCM 对因果的理解 一致,均描述为改变一个变量是否能够影响另一个 变量,这也是本文所考虑的因果范畴.两者的主要区 别在于表述方法不同,RCM 更加简洁直白,相关研究 更为丰富;而 SCM 表达能力更强,更擅长描述复杂 的问题.虽然目前依然存在对因果的其他不同理解, 这些理解通常不被视为真正的因果,例如格兰杰因 果(Granger causality) [20] 描述的是引入一个变量是否 对另一个变量的预测有促进作用,本质上仍是一种 相关关系. 本节将对因果相关概念以及 RCM 与 SCM 的相 关理论和技术进行简要介绍.由于本文关注的主要内 容是因果机器学习而不是因果本身,本节将侧重于 介绍机器学习中所使用的因果的概念和思想,而不 会过多关注因果领域自身的前沿研究.
**2 因果机器学习相关工作介绍 **
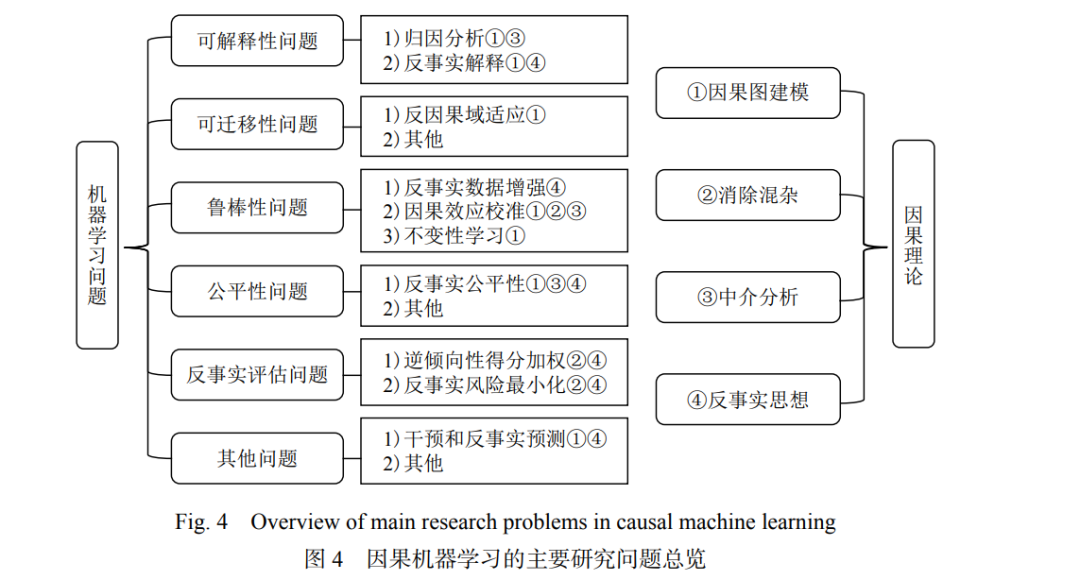
近年来随着因果理论和技术的成熟,机器学习 领域开始借助因果相关技术和思想解决自身的问题, 这一研究方向逐渐受到研究者越来越多的关注.至今,因果问题被认为是机器学习领域亟待解决的重要问 题,已成为当下研究的前沿热点之一.机器学习可以 从因果技术和思想中获得多个方面的益处.首先,因 果理论是一种针对数据中规律的普适分析工具,借 助因果图等语言可以对研究的问题做出细致的分析, 有利于对机器学习模型的目标进行形式化以及对问 题假设的表述.其次,因果推断提供了消除混杂因素 以及进行中介分析的手段,对于机器学习任务中需 要准确评估因果效应及区分直接与间接效应的场景 有十分重要的应用价值.再者,反事实作为因果中的 重要概念,也是人在思考求解问题时的常用手段,对 于机器学习模型的构建和问题的分析求解有一定的 指导意义. 本节将对近年来因果机器学习的相关工作进行 整理介绍,涉及应用领域包括计算机视觉、自然语言 处理、搜索引擎和推荐系统等.按照所解决问题的类 型进行划分,因果机器学习主要包括以下内容:可解 释性问题主要研究如何对已有机器学习模型的运作 机制进行解释;可迁移性问题主要研究如何将模型 在特定训练数据上学到的规律迁移到新的特定环境; 鲁棒性问题主要研究寻找普适存在的规律使模型能 够应对各种未知的环境;公平性问题主要研究公平 性度量指标并设计算法避免歧视;反事实评估问题 主要研究如何在存在数据缺失的场景中进行反事实 学习.这些问题与因果理论的关系如图 4 所示,下面 针对这些问题分别展开介绍.
**2.1 可解释性问题 **
机器学习模型会根据给定输入计算得到对应的 输出,但一般不会给出关于“为什么会得到此输出” 的解释.然而这种解释有助于人们理解模型的运作机 制,合理的解释能够使结果更具有说服力.因此近年 来涌现出许多致力于为现有模型提供解释方法的工 作,为模型的诊断分析提供了有效手段[39] .解释的核 心在于“模型得到此输出,是因为输入具有什么样的 特征”,这本质上是在探讨在此模型参与过程中输入 特征与输出结果之间的因果关系,例如估计特征对 输出变量的因果效应强度. 由于机器学习模型对输入数据的处理过程是一 个独立而完整的过程,输入与输出变量之间一般不 会受到混杂因素的影响,因此即使不使用因果术语 也可以对任务进行描述.这体现为早期的模型解释方 法并不强调因果,少数强调因果的方法也并不一定依赖因果术语.因果理论的引入为可解释性问题领域 带来的贡献主要有 2 个方面:一是在基于归因分析 的解释方法中建模特征内部的因果关系;二是引入 一类新的解释方法即基于反事实的解释.基于归因分 析和基于反事实的解释构成了当前最主要的 2 大类 模型解释方法如表 1 所示,以下分别展开介绍.

2.2 可迁移性问题
机器学习研究通常会在一个给定的训练数据集 上训练模型,然后在同数据分布的验证集或测试集 上进行测试,这种情况下模型的表现称为分布内泛 化(in-distribution generalization).在一般的应用场景中, 机器学习模型会部署在特定数据环境中,并使用该 环境中产生的数据进行模型训练,其性能表现可以用分布内泛化能力来度量.然而在一些场景中,目标 环境中的标注数据难以获取,因此更多的训练数据 只能由相似的替代环境提供.例如训练自动驾驶的智 能体时由于风险过高不能直接在真实道路上行驶收 集数据,而只能以模拟系统中所获取的数据为主进 行训练.这种场景下的机器学习任务又称为域适应 (domain adaptation),属于迁移学习(transfer learning) 的范畴,即将源域(source domain)中所学到知识迁移 至目标域(target domain).这里的域(domain)和环境 (environment)的含义相同,可以由产生数据的不同概 率分布来描述,下文将沿用文献中各自的习惯称呼, 不再对这 2 个概念进行区分. 在可迁移性问题中,因果理论的主要价值在于 提供了清晰的描述语言和分析工具,使研究者能够 更准确地判断可迁移和不可迁移的成分,有助于设 计针对不同场景的解决方案.因果推断中关注的效应 估计问题本质上是在研究改变特定环境作用机制而 保持其他机制不变的影响,这与迁移学习中域的改 变的假设相符,即目标域和源域相比继承了部分不 变的机制可以直接迁移,而剩余部分改变的机制则 需要进行适应.因此在因果理论的指导下,迁移学习 中的关键问题就是建模并识别变与不变的机制.目前 因果迁移学习一般假设输入 与输出 之间有直接 因果关系,重点关注无混杂因素情况下变量的因果 方向和不变机制,如表 2 所示,以下介绍相关工作

2.3 鲁棒性问题
迁移学习允许模型获得目标环境的少量数据以 进行适应学习,然而在一些高风险场景中,可能需要 机器学习模型在完全陌生的环境中也能正常工作, 如医疗、法律、金融及交通等.以自动驾驶为例,即使 有大量的真实道路行驶数据,自动驾驶智能体仍会 面临各种突发情况,这些情况可能无法被预见但仍 需要被正确处理.这类任务无法提供目标环境下的训 练数据 ,此时模型的表现称为分布外泛化(out-ofdistribution generalization).如果模型具有良好的分布 外泛化能力,则称其具有鲁棒性(robustness). X Y P ′ (X, Y) P(X, Y) Y X P ′ (X|Y) = P(X|Y) 这类问题在未引入因果术语的情况下就已经展 开了广泛的研究.如分布鲁棒性研究[79-81] 考虑当数据 分布改变在一定幅度之内时如何学习得到鲁棒的模 型,常见思路是对训练样本做加权处理;对抗鲁棒性 研究[8,82-83] 考虑当样本受到小幅度扰动时模型不应当 改变输出结果,常见思路是将对抗攻击样本加入训 练.这类研究常常忽略变量间的因果结构,面临的主 要问题是很难决定数据分布或者样本的扰动幅度大 小和度量准则,这就使得研究中所做的假设很难符 合真实场景,极大地限制了在实际中的应用.因果理 论的引入为建模变量间的结构提供了可能,同时其 蕴含的“机制不变性”原理为鲁棒性问题提供了更合 理的假设,因为真实数据往往是从遵循物理规律不 变的现实世界中采集获得.例如针对输入为 、输出 为 的预测问题,不考虑结构的分布鲁棒性方法会假 设未知环境 应当与真实环境 的差异较 小,如限制联合分布的 KL 散度小于一定阈值;而考 虑结构的因果方法则通常会假设机制不变,例如当 是 的因时假设 ,在因果关系成立的 情况下后者通常是更合理的. 一些从伪相关特征入手研究鲁棒性问题的工作 虽然未使用因果术语,实际上已经引入了因果结构 的假设.这些工作针对的往往是已知的伪相关特征, 如图像分类任务中的背景、文本同义句判断 SNLI 数 据集中的单条文本[84]、重复问题检测 QuaraQP 数据 集中的样本频率[85] 等.在实际场景中针对这些伪相关 特征进行偏差去除(debias),以避免其分布发生变化 时影响模型表现.这类工作隐含的假设是伪相关特征 与目标预测变量没有因果关系.一种直接的解决方法 是调整训练数据的权重,使得伪相关特征不再与预 测变量相关[85] .还有一类方法会单独训练一个仅使用 伪相关特征预测的模型,然后将其与主模型融合在 一起再次训练,完成后仅保留主模型[86-87] .然而由于实 际应用中通常很难预先确定伪相关特征,这类工作 在解决鲁棒性问题上具有明显的局限性. 因果理论的引入对于解决鲁棒性问题提供了新 的思路,主要的优势在于对变量结构的建模和更合 理的假设.这类方法包括反事实数据增强(counterfactual data augmentation)、因果效应校准和不变性学 习.如表 3 所示 ,反事实数据增强考虑从数据入手消 除伪相关关系,因果效应校准通过调整偏差特征的 作用来减轻偏差,不变性学习通过改变建模方式学 习不变的因果机制,以下分别展开介绍.

2.4 公平性问题
机器学习中的公平性(fairness)指的是,对于特 定的敏感特征如性别、年龄、种族等,不同的取值不 应该影响某些任务中机器学习模型的预测结果,如 贷款发放、法律判决、招生招聘等.公平性对于机器 学习在社会决策中的应用是十分重要的考虑因素, 与因果有密切的关系,直观上体现为敏感特征不应 成为预测结果的因变量.模型中存在的不公平常常由 伪相关特征问题导致,因此公平性也可以视为针对 敏感特征的鲁棒性,但有着自己独有的术语和研究 体系.下面首先介绍一下公平性的基本概念,然后介 绍因果理论在公平性问题中的应用. A X Y f Yˆ = f(A, X) f(A, X) = f(X) 公平性的定义和度量指标目前十分多样化,并 没有完全统一确定,不同的定义所反映的问题也有 所不同,甚至可能是相互不兼容的[139] .为便于表述, 记敏感特征为 ,其他观测特征为 ,真实输出结果 为 ,模型为 ,模型预测结果为 (本节所用 符号与前文无关).早期公平性问题的相关工作并没 有考虑因果,最简单直白的方式是在决策时避免使 用敏感特征[140] ,即 .然而这一方案显然 是不够的,因为其他特征中也可能会包含敏感特征 的信息.因此一般会考虑个体级别的公平性或者群体 级别的公平性的度量,并设计方法实现.个体公平性 (individual fairness)通常会限制相似的个体之间应该 P(Yˆ|A = 0) = P(Yˆ|A = 1) P (Yˆ|A = 0, Y = 1) = P(Yˆ|A = 1, Y = 1) F P(Yˆ|A = 0, F) = P(Yˆ|A = 1, F) 有相似的预测结果[141] ,难点在于相似性指标的设计. 群体公平性(group fairness)会定义不同的群体并设置 度量指标使得各个群体之间差异尽可能小,一种思 路是人群平等(demographic parity) [142] ,希望在不同敏 感特征取值的群体中预测结果的分布一致 ,即 ; 另 一 种 思 路 是 机 会 均 等 (equality of opportunity) [143] ,希望在那些本该有机会 的人群所获得的机会不受敏感特征的影响 ,即 ;还有一种思路是条件 公平(conditional fairness) [144] ,希望在任意公平变量 条 件下不同敏感特征群体的结果一致,即 .这些定义并不考虑特征内部的依赖关系, 对模型的决策机制也没有区分性,在更细致的公平 性分析中难以满足要求.因果理论的引入为公平性研 究起到了极大的推动作用,许多概念必须借助因果 的语言才能表达,如表 4 所示:

2.5 反事实评估问题
反事实评估(counterfactual evaluation)指的是机 器学习模型的优化目标本身是反事实的,这通常出 现在使用有偏差的标注数据训练得到无偏模型的情 景,例如基于点击数据的检索和推荐系统学习任 务.由于任务本身需要反事实术语进行表述,因果理 论对这类问题的建模和研究起到了关键性的作用, 如表 5 所示:

3 总结与展望
本文介绍了因果相关的概念、模型和方法,并着 重对因果机器学习在各类问题上的前沿研究工作展 开详细介绍,包括可解释性问题、可迁移性问题、鲁 棒性问题、公平性问题和反事实评估问题等.从现有 的应用方式来看,因果理论对于机器学习的帮助在 不同的问题上具有不同的表现,包括建模数据内部 结构、表达不变性假设、引入反事实概念和提供效 应估计手段等,这在缺少因果术语和方法的时代是 难以实现的.有了因果理论的帮助,机器学习甚至可 以探讨过去无法讨论的问题,如干预和反事实操作 下的预测问题. 对于可解释性、公平性和反事实评估问题,因果 理论和方法已成为描述和求解问题所不可缺少的一 部分,且应用方式也渐趋成熟.这是由于对特征的重 要程度的估计、对模型公平性的度量和对反事实策 略效用的评估均属于因果效应估计的范畴,问题本 身需要使用因果的术语才能得到清晰且完整的表达, 因果推断的相关方法自然也可以用于问题的求解.可 以预见,未来这些问题将继续作为因果理论和方法 的重要应用场景,伴随因果推断技术的发展,向着更 加准确和高效的目标前进. 对于可迁移性和鲁棒性问题,目前所采用的因 果相关方法大多还处于较浅的层次,有待深入挖掘 探索.在这些问题上,因果推断的相关技术不易直接 得到应用,这是由于这类问题的目标不再是单纯估 计因果效应或者发现因果结构,而是需要识别跨环 境不变的机制.这对于因果而言是一项全新的任务, 需要研究新的方法来求解.在机器学习尤其是深度学 习中,这项任务的主要难点在于数据的高维复杂性. 对于图像和文本等数据而言,其显式特征高度耦合, 难以从中提取出有效的因果变量,阻碍了效应估计 和结构发现等后续分析手段.目前所采用的反因果迁 移、反事实数据增强和因果效应校准等手段大多只 能针对可观测的已知变量进行处理,适用范围受到 很大限制.相对地,不变性学习有能力处理未知的伪 相关特征并识别因果特征,具有良好的发展前景.然 而目前的不变性学习方法也存在局限性,主要在于 对数据做了较强的因果结构假设,一方面数据可能 无法满足假设而又缺少验证假设的手段,另一方面 需要为满足不同假设的数据设计不同的方法而缺乏 通用性.因此,未来在这些方向上都值得开展研究.一 种思路是继续针对具体任务做出不同的因果结构假 设,并设计对应的学习算法,这就需要构建成体系的 解决方案并配备验证假设的手段;另一种思路是从 数据本身出发,推断和发现潜在的因果结构,这就需要研究全新的方法来突破由数据的高维复杂性带来 的障碍. 从因果机器学习的研究进展来看,机器学习领 域的因果革命将大有可为.不可否认,当前正处于因 果革命的起步阶段,由于现实问题存在极高的复杂 性,这一革命的历程也将曲折而艰辛,需要更多的研 究和支持.希望更多的研究者能够加入到因果机器学 习的研究中来,共同创造和见证因果革命的新时代.