

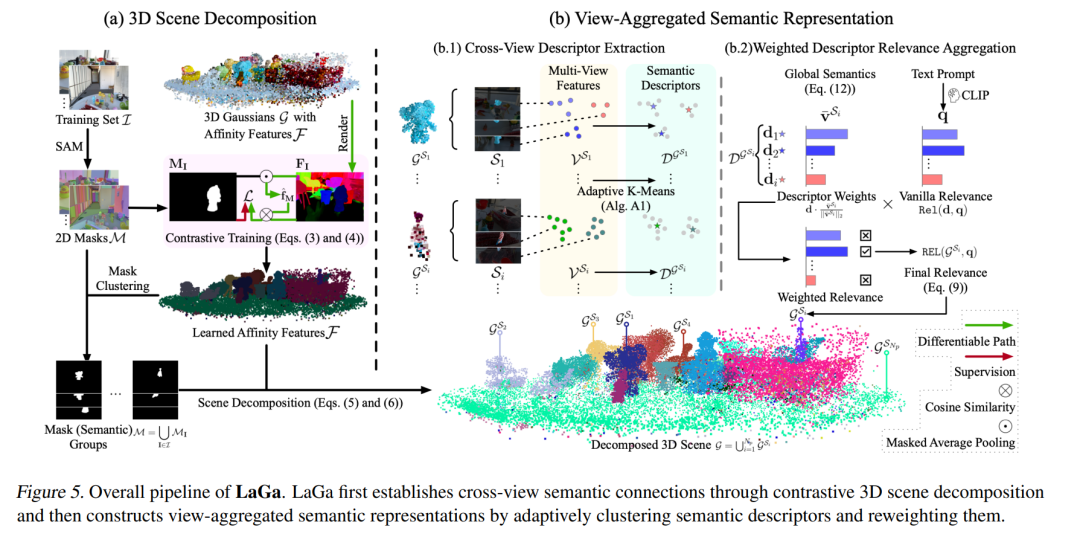
近年来,3D高斯溅射(3D-GS)在从RGB图像中进行高质量的3D场景重建方面取得了显著进展。许多研究扩展了这一范式,应用于语言驱动的开放词汇场景理解。然而,大多数研究仅仅将2D语义特征投影到3D高斯分布上,忽视了2D与3D理解之间的根本差距:3D物体在不同视角下可能呈现出不同的语义特征——这一现象我们称之为视角依赖语义。为了应对这一挑战,我们提出了LaGa(语言高斯),它通过将3D场景分解为物体,建立跨视角的语义关联。接着,它通过对语义描述符进行聚类,并根据多视角语义重新加权,构建视角聚合的语义表示。大量实验表明,LaGa能够有效捕捉视角依赖语义中的关键信息,从而实现对3D场景的更全面理解。值得注意的是,在相同设置下,LaGa在LERF-OVS数据集上相较于之前的SOTA,mIoU显著提升了+18.7%。我们的代码已开放,地址为:https://github.com/https://github.com/SJTU-DeepVisionLab/LaGa。
成为VIP会员查看完整内容
相关内容
Arxiv
40+阅读 · 2023年4月19日
Arxiv
210+阅读 · 2023年4月7日
Arxiv
20+阅读 · 2023年3月21日
相关主题
相关VIP内容
相关资讯
相关论文
Arxiv
40+阅读 · 2023年4月19日
Arxiv
210+阅读 · 2023年4月7日
Arxiv
20+阅读 · 2023年3月21日