
Text to SQL( 以下简称Text2SQL),是将自然语言文本(Text)转换成结构化查询语言SQL的过程,属于自然语言处理-语义分析(Semantic Parsing)领域中的子任务。在大模型时代怎么做?这篇综述调研了最新进展。

自然语言处理的出现彻底改变了用户与表格数据的交互方式,实现了从传统查询语言和手动绘图到更直观的基于语言的接口的转变。大型语言模型(LLMs),如ChatGPT及其后继者的崛起,进一步推进了这一领域,为自然语言处理技术开辟了新的途径。这份综述为我们提供了关于表格数据的自然语言接口查询与可视化的全面概览,它允许用户使用自然语言查询与数据进行交互。我们介绍了这些接口背后的基本概念和技术,特别强调了语义解析,这是从自然语言到SQL查询或数据可视化命令的关键技术。接下来,我们深入探讨了从数据集、方法、指标和系统设计的角度看Text-to-SQL和Text-to-Vis问题的最新进展。这包括对LLMs的影响的深入分析,强调它们的优势、局限性和未来改进的潜力。通过这份综述,我们希望为那些对在大型语言模型时代的数据交互感兴趣的研究者和从业者提供一个发展与应用自然语言接口的路线图。
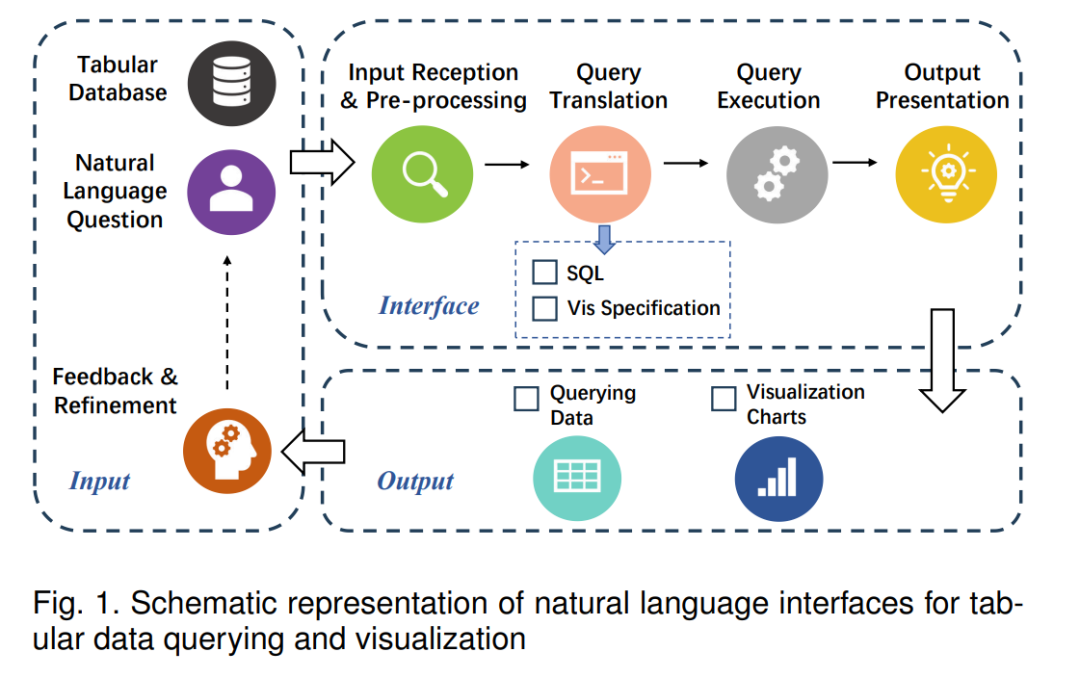
表格数据或结构化数据在今天的数字时代构成了许多领域的基石,包括商业、医疗健康和科学研究[57],[81]。然而,有效且高效地与大量的结构化数据互动以提取有价值的见解仍然是一个关键挑战。传统的交互方法,如使用结构化查询语言进行查询或手动绘制可视化,通常需要相当高的技术专长,从而限制了它们对更广泛用户群的可访问性[2]。
随着自然语言处理技术的出现,我们与结构化数据的交互方式开始发生变化。这些技术促进了自然语言接口的开发,使表格数据查询和可视化变得更加直观和易于访问。通过这些接口,用户可以使用自然语言查询和命令从数据库中提取信息或生成数据的视觉表示[47],[93]。这种转向基于语言的接口的变化标志着简化数据交互的重大进步,使其更加用户友好,对非技术用户更加可访问。
支撑这些基于语言的接口的基础技术根植于语义解析任务,它将自然语言查询转化为为在结构化数据库上执行而定制的正式表示形式[50]。尽管为此目的已经引入了各种正式语言和功能表示,例如Prolog、Datalog和FunQL,但在表格数据交互中,有两种尤为主导:用于数据查询的SQL和用于数据可视化的可视化规范。SQL已经成为查询关系数据库的事实标准,提供了全面的操作来检索和操作数据。可视化规范提供了一种结构化的方式来表示复杂的可视化,使其成为数据可视化过程的一个组成部分。考虑到它们的重要性和广泛的使用,这次综述将主要关注这两种表示,深入探讨将自然语言转化为SQL和可视化规范的任务的挑战和进展。在这种情境下,Text-to-SQL任务[133]充当将用户查询转化为SQL指令的桥梁,而Text-to-Vis任务[71]则促进了从用户可视化请求到可视化规范的转化。
这两个语义解析任务的发展多年来已经发生了显著的演变,受到机器学习和自然语言处理技术的推动。早期的方法通常依赖于基于规则或基于模板[1],[50]的系统和浅层解析技术。然而,这些方法在处理复杂的查询和可视化方面都存在困难,并对用户输入的特定措辞敏感。引入神经网络和深度学习方法带来了性能的重大飞跃。这些方法,通常基于序列到序列的模型[53],能够捕获数据中更复杂的模式,并对输入的变化更加稳健。然而,它们仍然需要大量的训练数据,并且在处理领域外的查询时会遇到困难。像BERT[16]、T5[85]、GPT[79]这样的预训练语言模型(PLMs)的崛起标志着该领域的一个转折点。凭借其在大量文本数据上进行预训练的能力,PLMs在包括Text-to-SQL和Text-to-Vis在内的一系列自然语言处理任务中都取得了显著的成功。最近,像ChatGPT这样的大型语言模型(LLMs)的出现以及提示工程技术的探索为开发更有效且用户友好的自然语言数据交互接口打开了新的途径。
对于表格数据查询和可视化的自然语言界面的跨学科研究融合了多个研究方面,如自然语言处理和数据挖掘,进展经常沿着多样且不同的轨迹进行。尽管其重要性逐渐增加,但尚未有单一的研究全面回顾了查询和可视化任务的语义解析问题的系统和统一方式。随着这个领域的不断发展和增长,有越来越大的需求来组织研究景观,分类当前的工作,并识别知识空白。 虽然之前已经有一些努力总结了这个领域的进展,但它们主要关注了查询和可视化的早期方法以及后续的深度学习发展[1]、[14]、[47]、[53]、[93],但并没有提供这些相互关联领域的综合视图。此外,据我们所知,没有现有的调查涵盖了大型语言模型(LLMs)在这些领域的最近进展。像ChatGPT及其后续版本等LLMs的深远影响在数据查询和可视化的自然语言界面上是一个迅速增长的领域,需要更多的关注和探索。 本次调查旨在通过提供表格数据查询和可视化的自然语言界面的详细概述来填补这些空白。我们从过去二十年的关键期刊和会议中收集参考文献,涵盖了自然语言处理、人机交互、数据挖掘和可视化。我们的搜索受到诸如“自然语言界面”、“可视化”和“文本到SQL”等术语的指引,我们还探讨了被引用的出版物以捕获基础性的贡献。我们旨在解决一系列关键的研究问题,可以指导我们对表格数据和可视化的自然语言界面的理解:
**• 自然语言界面随着时间的推移是如何发展的? **
**• 最近的进展,特别是LLMs,是如何影响这个领域的? **
**• 现有方法的固有优点和缺点是什么? **
通过这次综素,我们希望通过广泛的文献综述和分析为这些问题提供有见地的答案。我们将深入研究功能表示、数据集、评估指标和系统架构,特别强调LLMs的影响。我们的目标是呈现一个关于现有技术状态的清晰简洁的概述,强调现有方法的优点和局限性,同时探索未来增强的可能途径。
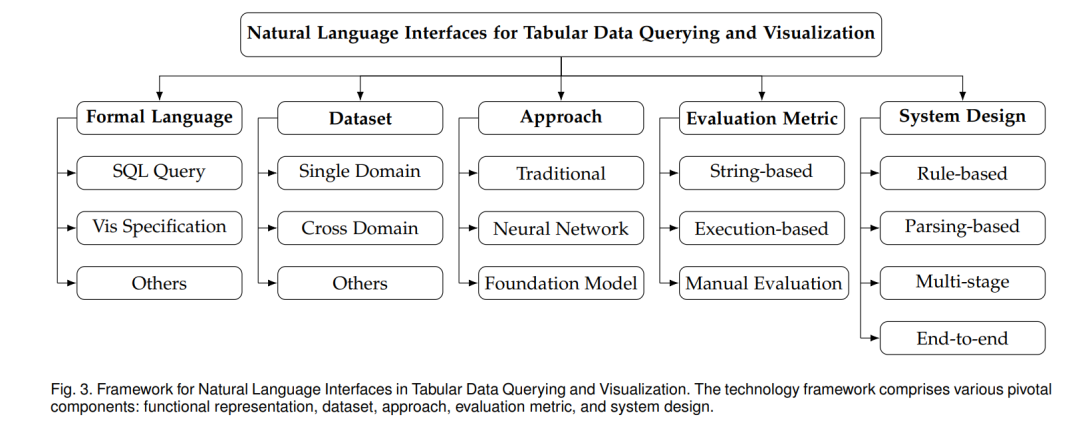
表格数据查询和可视化的自然语言界面包括多种组件,每个组件在技术框架中都起到关键作用,如图3所示。
• 数据集。数据集在训练和评估这些界面的性能中起到至关重要的作用。数据集可以是单轮的,即提出一个没有任何先前上下文的查询,或者是多轮的,其中一系列查询以会话方式提出。还有各种类型的数据集旨在评估系统的不同方面,如处理复杂查询、领域外查询的能力等。 • 方法。构建自然语言界面的方法随着时间的推移而演变。早期的方法是基于规则的,使用预定义的规则将自然语言查询转化为功能表示。随着神经网络的出现,序列到序列模型变得受欢迎,提供了更多的灵活性来处理各种查询。像BERT[16]和GPT[79]这样的预训练语言模型的崛起标志着这个领域的重大进展。最近,像ChatGPT这样的大型语言模型的出现,以及对提示工程技术的探索,为开发更有效的数据交互自然语言界面打开了新的途径。 •** 评估指标**。评估指标用于衡量这些界面的性能。这些可以是基于字符串的,将生成的功能表示与基准真相进行比较,或基于执行的,将在数据库上执行生成的表示的结果与预期结果进行比较。有时也使用手动评估来评估像系统的可用性这样的方面。 • 系统设计。系统架构是自然语言界面的关键组成部分,涉及将用户查询转化为可操作输出的基础机制。从基于规则到端到端的设计范式提供了各种解决方案和权衡,就灵活性、可解释性和准确性而言。 这些组件中的每一个都为表格数据查询和可视化的自然语言界面的有效性和可用性作出贡献。
本综述的后续部分将更详细地深入这些组件,讨论它们的角色,使用的各种方法和技术以及每个领域的最新进展。
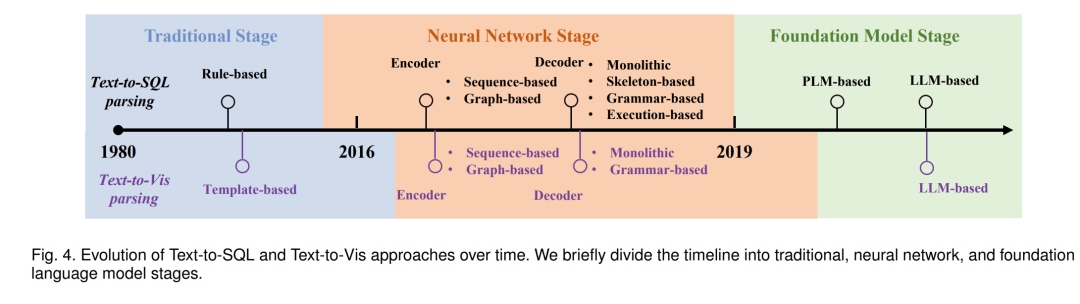
**结论 **
在这次综述中,我们深入探讨了表格数据查询和可视化的自然语言界面,深入了解这一领域的复杂性、其演变和它所解决的挑战。我们从基础问题定义追踪到最新的方法。我们强调了推动这些界面的多样数据集的重要性,并讨论了衡量其效果的指标。通过探索系统架构,我们检查了不同系统设计的差异。最后,我们的目光转向未来,指向大型语言模型时代的有前途的研究方向。随着这个动态领域的演变,我们的探索为其当前的状态、挑战和潜力提供了一个简洁的快照。