

Transformer架构促进了大规模和通用序列模型的发展,这些模型用于自然语言处理和计算机视觉中的预测任务,例如GPT-3和Swin Transformer。虽然最初是为预测问题而设计的,但自然会询问它们是否适用于顺序决策和强化学习问题,这些问题通常受到涉及样本效率、信用分配和部分可观察性的长期问题的困扰。近年来,序列模型,特别是Transformer,在强化学习社区引起了越来越多的关注,催生了众多以显著的有效性和泛化性为特点的方法。本文综述提供了一个全面的概述,介绍了近期致力于使用诸如Transformer之类的序列模型解决顺序决策任务的工作,通过讨论顺序决策与序列建模之间的联系,并根据它们使用Transformer的方式对其进行分类。此外,本文提出了未来研究的各种潜在途径,旨在提高大型序列模型在顺序决策制定中的有效性,包括理论基础、网络架构、算法和高效的训练系统。
1.引言
具有大量参数和自回归数据处理特性的大型序列模型,近期在自然语言处理(NLP)[2]和计算机视觉(CV)[3]的预测任务和(自)监督学习[1]中发挥了重要作用,例如ChatGPT [4] 和Swin Transformer [5]。此外,这些模型,特别是Transformer [6],在过去两年中在强化学习社区引起了极大的关注,催生了众多在第5节中概述的方法。另外,大型序列模型在顺序决策和强化学习(RL)[7]领域也已经出现,其有效性和泛化性显著,如Gato [8]和视频预训练(VPT)[9]所证实。这些方法暗示着构建通用的大型决策模型的可能性,即能够利用大量参数来执行数百个或更多顺序决策任务的大型序列模型,这与大型序列模型在NLP和CV中的应用方式类似。
这份调研关注了大部分利用(大型)序列模型,主要是Transformer,进行顺序决策任务的当前工作,而Sherry等人[10]的报告中可以找到各种其他类型的基础模型在实际决策环境中的应用。我们对序列模型在顺序决策问题中的作用进行了深入的调查,讨论了它们的重要性以及像Transformer这样的序列模型与解决此类问题的关系。在调查当前的工作如何利用序列模型促进顺序决策的同时,我们还分析了目前在模型大小、数据和计算方面对大型决策模型的主要瓶颈,并探讨了未来在算法和训练系统方面进行研究以提高性能的潜在途径。
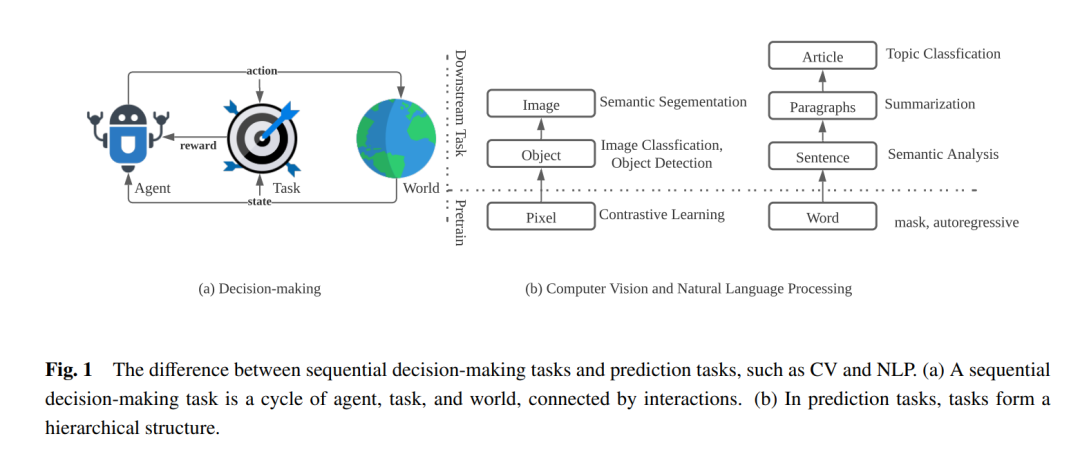
在这份调研的其余部分,第2节介绍了预测和顺序决策问题的构建。第3节将深度强化学习(DRL)介绍为顺序决策任务的经典解决方案,并检查DRL中三个长期存在的挑战:样本效率问题、信用分配问题和部分可观察性问题。第4节建立了序列模型与顺序决策之间的联系,强调了序列建模在第3节提出的三个挑战方面的促进作用。第5节调查了大部分利用Transformer架构进行顺序决策任务的当前工作,并讨论了Transformer如何在不同的设置中增强顺序决策以及构建大型决策模型的潜力。第6节讨论了关于支持训练大型决策模型的系统支持方面的当前进展和潜在挑战。第7节从理论基础、模型架构、算法和训练系统的角度讨论当前的挑战和潜在研究方向。最后,第8节总结了本次调研的结论,并期望对大型决策模型这一新兴主题进行更多的探讨。
2. 基于深度RL的序列决策
作为深度神经网络和强化学习(RL)的结合,深度强化学习(DRL)受到了广泛关注,并成为解决顺序决策任务的热门范式[7]。近年来,通过一系列值得注意的成就,例如AlphaGo [20]和AlphaStar [21]在围棋和星际争霸II游戏中击败人类专家,它的高潜力得到了展示。
3. 序列决策视为序列建模问题
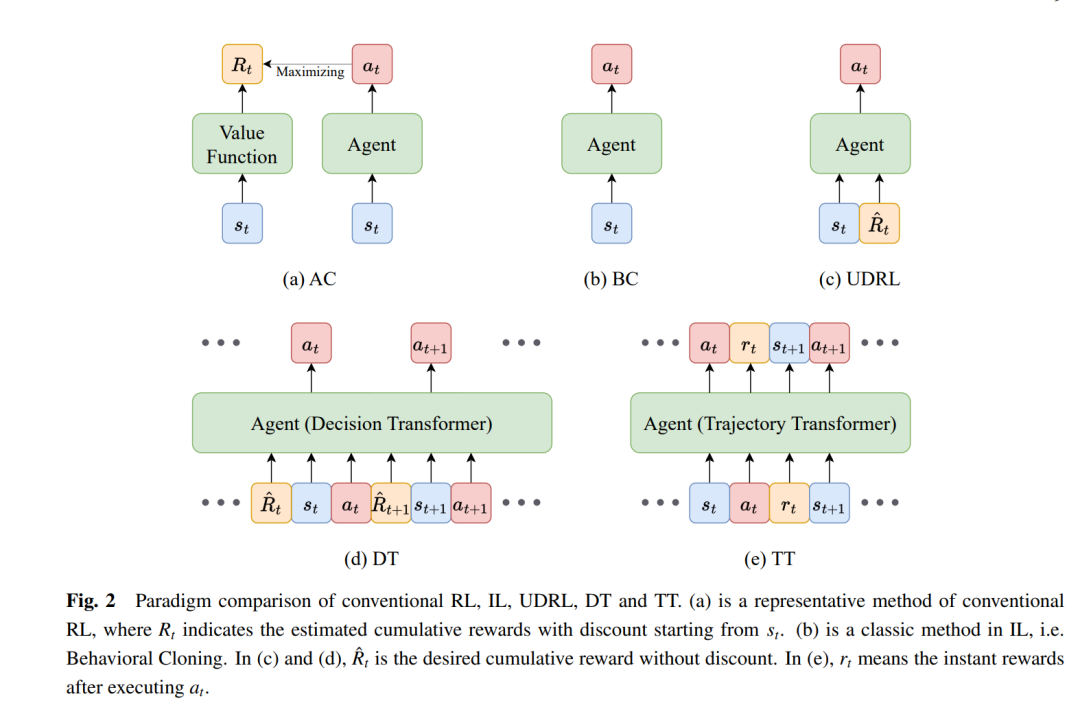
幸运的是,第3节提到的挑战可以通过将顺序决策问题视为序列建模问题来解决,然后由序列模型来解决。为了克服这些挑战,一些研究人员尝试通过将它们转化为监督学习问题,特别是序列建模问题,来简化顺序决策任务。模仿学习(IL),如行为克隆(BC)[38]和生成对抗模仿学习(GAIL)[39],通过专家演示的监督来训练代理,整合了表示学习和转移学习的进步,例如BC-Z [40]或多模态交互代理(MIA)[41]。然而,IL的性能严重依赖于高质量的专家数据,这些数据的获取成本很高,并且随着模型大小的增加,与增加的数据需求相冲突。上下颠倒的强化学习(UDRL)[42]是一种新颖的方法,将传统的强化学习(RL)转化为纯粹的监督学习范式。与基于价值的RL相比,它在学习过程中颠倒了动作和回报的角色。具体来说,它使用未折扣的期望回报作为网络输入,作为指令来指导代理的行为。因此,与传统的基于价值的RL不同,后者学习一个价值模型来评估每个动作的质量并选择最优的动作,UDRL学习寻找一系列满足特定期望回报的动作。通过在所有过去的轨迹上对代理进行纯粹的SL训练,UDRL规避了传统RL中由于函数逼近、自举和离策略训练的结合而产生的敏感折扣因子和致命试验的问题[7,42]。此外,尽管在具有完美马尔可夫性质的环境中,经典方法仍然更有效,但实验结果显示UDRL在非马尔可夫环境中出人意料地超过了诸如DQN和A2C之类的传统基线[42]。这些结果表明,UDRL的一般原则不仅限于马尔可夫环境,表明在更广泛的背景下解决顺序决策问题是一个有前途的方向。
作为一项代表性的工作,决策变换器(Decision Transformer,简称DT)[43]将RL问题构建为序列建模问题,这使其能够利用变换器的简单性和可扩展性。基于UDRL的概念,DT将一系列状态、先前的动作和期望的回报输入到类似GPT的网络中,并推断出达到期望回报的动作,其中变换器用作策略模型。与DT和UDRL不同,轨迹变换器(Trajectory Transformer,简称TT)[44]将转换序列完全映射到平移的转换序列中,包括状态、动作和即时奖励,其中变换器作为捕获环境完整动态的世界模型。尽管DT是一种无模型方法,而TT是一种基于模型的方法,但两种方法都有一个共同的基础:将每个时间轨迹视为转换的连续序列,并使用变换器对其进行建模。基于这个基础,变换器可以用来推断未来的状态、动作和奖励,从而统一了通常需要在IL、基于模型的RL、无模型的RL或目标条件的RL [44]中的许多组件,例如基于模型方法中的预测动力学模型,演员-评论家(AC)算法[25]中的演员和评论家,以及IL中的行为策略近似。图2比较了传统RL、IL、UDRL、DT和TT之间的范式。
**4 结论 **
在这篇综述中,我们探讨了利用序列建模方法解决顺序决策任务的当前进展。通过序列建模来解决顺序决策问题可以是解决传统强化学习方法中一些长期存在的问题的有前景的解决方案,包括样本效率、信用分配和部分可观察性。此外,序列模型可以在数据效率和可转移性方面弥合强化学习和离线自我监督学习之间的差距。我们得出结论,大型决策模型的模型架构应在支持多模态、多任务可转移性和稀疏激活的意识下进行设计,而算法应解决关于数据质量和数量的问题。并且,整体训练效率应通过并行化进行系统优化。在一系列关于理论基础、网络架构、算法设计和训练系统支持的讨论之后,这篇综述提供了构建大型决策模型的潜在研究方向。我们希望这篇综述能激发对这个热门话题的更多研究,并最终赋予更多实际应用更多的能力,如机器人技术、自动驾驶车辆和自动化工业。

