摘要—— 作为机器人学和具身智能的关键前沿,机器人操作需要精确的运动控制,以及在动态环境中对视觉与语义线索的综合理解。传统方法依赖预定义的任务规范和僵化的控制策略,往往难以在非结构化、全新场景下扩展或泛化。近年来,基于大规模视觉-语言模型(VLMs)的视觉-语言-动作(VLA)模型逐渐成为一种变革性的范式。这类模型利用大规模 VLMs 在开放世界泛化、层级任务规划、知识增强推理以及多模态融合方面的能力,使机器人能够理解高层指令、识别未知环境并执行复杂的操作任务。本综述首次从系统化、面向分类法的角度,对用于机器人操作的大规模 VLM 驱动 VLA 模型进行全面回顾。我们首先明确界定大规模 VLM 驱动的 VLA 模型,并划分出两类核心体系结构范式:(1)单体式模型,涵盖单系统与双系统设计,二者在集成程度上有所差异;(2)分层式模型,显式地通过可解释的中间表示将规划与执行解耦。在此基础上,我们深入探讨大规模 VLM 驱动的 VLA 模型:(1)其与强化学习、免训练优化、人类视频学习以及世界模型集成等前沿领域的结合;(2)其独特特征的综合,包括体系结构特点、操作优势,以及支撑其发展的数据集和基准;(3)未来的研究方向,包括记忆机制、四维感知、高效适应、多智能体协作以及其他新兴能力。本综述整合了近期进展,旨在弥合现有分类法的不一致性,缓解研究碎片化,并通过系统性地整合大规模 VLM 与机器人操作交叉领域的研究,填补关键空白。我们提供了一个定期更新的项目主页以记录最新进展:https://github.com/JiuTian-VL/Large VLM-based VLA for Robotic Manipulation。 关键词—— 视觉-语言-动作模型,机器人操作,具身智能,大规模视觉-语言模型
1 引言
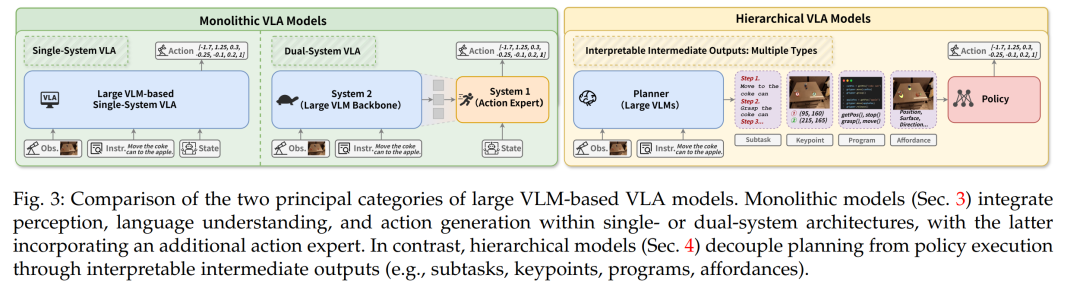
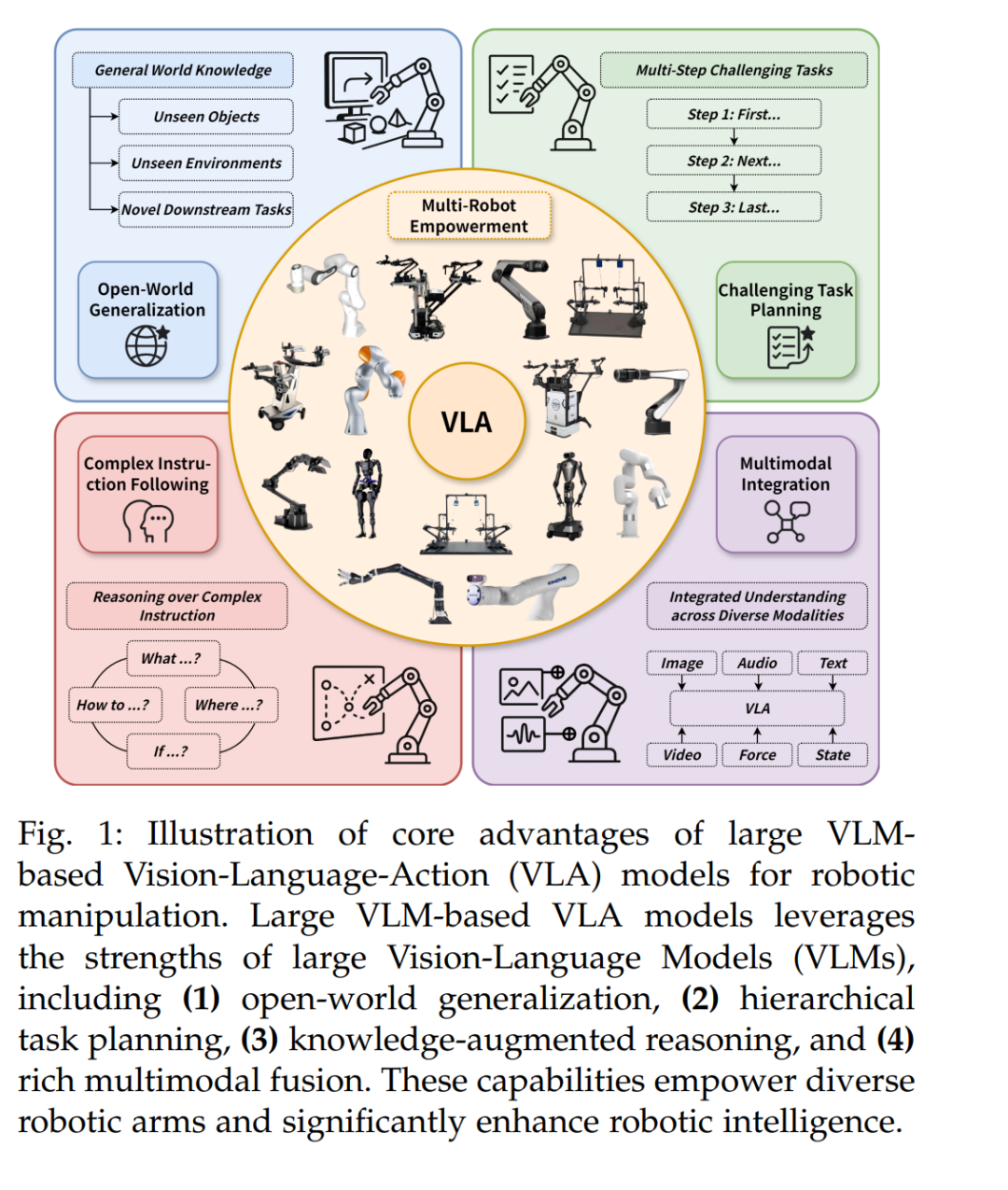
机器人操作(Robotic Manipulation)处于机器人学与具身人工智能交汇处的关键挑战 [1]–[5]。其实现不仅需要精确的运动控制,还需要对复杂动态环境中的多样化视觉与语义线索具备深刻理解。机器人操作在诸多领域展现出广泛应用价值,包括先进制造、高效物流、精准医疗和多样化的家庭服务 [6]–[8]。传统的操作方法 [9]–[16] 主要依赖精心设计的控制策略和严格预定义的任务规范。然而,这些方法在非结构化的真实世界场景中往往表现不佳——尤其是在面对新颖物体、模糊的自然语言指令或此前未见的环境配置时,暴露出其在可扩展性与泛化能力方面的固有限制。 近年来,大规模视觉-语言模型(Vision-Language Models, VLMs)[17]–[25] 崛起为一种变革性范式。基于大规模网页级图文数据集的预训练,大规模 VLM 展现出卓越的能力,能够弥合视觉感知与自然语言理解之间的语义鸿沟。这种创新能力使 VLM 不仅能结合文本描述理解复杂视觉场景,还能超越单纯的目标识别,形成整体的上下文理解。大规模 VLM 与机器人系统的结合催生了一类新模型:基于大规模 VLM 的视觉-语言-动作(Vision-Language-Action, VLA)模型 [26]–[32]。如图 1 所示,这一新兴范式展现出克服传统机器人流水线根本局限的巨大潜力。它使机器人能够理解高层次的人类指令、泛化至未知物体与场景、推理复杂的空间关系,并在动态、非结构化环境中执行复杂的操作任务。例如,一个 VLA 模型可以完成如下指令:“把红色的杯子从笔记本电脑旁边放到最上层的架子上”,这一任务需要视觉定位、空间推理与序列动作规划的复杂融合。 在本研究中,基于对近期工作的广泛回顾 [26]–[37] 及对该领域的深入理解 [38]–[43],我们提出了一个一致性的定义:大规模 VLM 驱动的 VLA 模型是指能够(1)利用大规模 VLM 理解视觉观测和自然语言指令;并且(2)通过推理过程直接或间接地服务于机器人动作生成的模型。我们进一步将其划分为两大类(见图 2 与图 3): * 单体式模型(Monolithic Models)(图 3 左):包括单系统与双系统实现。
单系统模型 [26], [27], [44], [45] 在统一架构中集成了环境理解(包括视觉感知、语言理解与机器人状态感知)与动作生成。 * 双系统模型 [29]–[32] 则采用 VLM 作为场景解释的骨干网络,并由一个动作专家负责动作生成,二者通过潜在表示的传播进行信息交互。 * 分层式模型(Hierarchical Models)(图 3 右)[46]–[50] 明确将规划与策略执行解耦。它们区别于双系统的端到端方法,具有以下特征:
结构化的中间输出:规划模块生成可解释的表示(如关键点检测、可供性图、轨迹提案),随后由策略模块处理以生成可执行的动作。 1. 解耦的训练范式:通过专门的损失函数或 API 驱动的交互,实现对层级模块的独立优化。
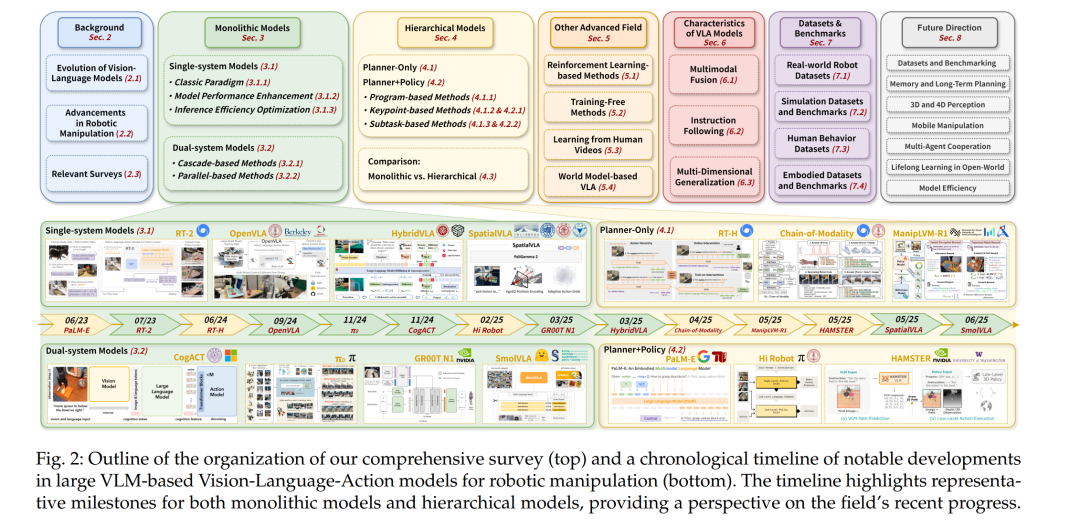
这种分类法凸显了 VLA 模型开发中的关键设计维度,尤其是系统集成的粒度与认知分解的显式程度,同时保持与现代表征学习范式的紧密联系。 在上述定义与分类的框架下,我们的全面综述揭示了新兴 VLA 领域中的若干关键缺口,其整体组织结构如图 2 所示。首先,该领域的术语与建模假设尚不一致,研究工作分散在机器人学、计算机视觉与自然语言处理等学科。其次,已有综述往往仅聚焦于 VLMs [51]–[55] 或机器人操作 [2], [56]–[59],缺乏对二者交叉所带来的独特挑战与进展的综合分析。因此,亟需一份系统性和原则性的综述,以阐明大规模 VLM 驱动 VLA 模型的基础,组织相关方法的空间,并勾勒该融合范式的未来方向。本综述旨在填补这一空白。我们提供了结构化且深入的回顾,以全景视角推动学界更深刻的理解并激发未来的突破。
本文的主要贡献总结如下: * 纵向综述: 我们系统回顾了 VLM 的演化轨迹、操作学习的技术进展,以及大规模 VLM 驱动 VLA 范式的兴起。同时,分析了单体式模型与分层式模型的发展,识别关键挑战并展望未来方向。 * 横向综述: 我们提供了单体式与分层式模型更精细的比较性分类法,从结构与功能两个维度展开分析。进一步探讨了大规模 VLM 驱动 VLA 模型的前沿研究方向,强调其独特特征与支撑发展的数据集。该综述为理解该领域的发展与结构组织提供了概念性路线图。
本文余下部分的组织结构如图 2 所示:第二节介绍 VLM 演化与机器人操作基础知识;第三节分析单体式模型,包括单系统与双系统架构的优劣与权衡;第四节探讨分层式模型,将其分为仅规划器与规划-策略框架,并进一步根据中间表示类型(子任务、关键点、程序等)细分;第五节讨论其他前沿方法,包括基于强化学习的优化、免训练方法、从人类视频学习以及基于世界模型的方法;第六节分析大规模 VLM 驱动 VLA 模型的核心特征,涵盖多模态融合、指令跟随和多维泛化;第七节分类与分析相关数据集与基准,涵盖模拟、真实世界与人类交互数据;第八节探讨关键开放挑战与未来研究方向;第九节给出结论。