

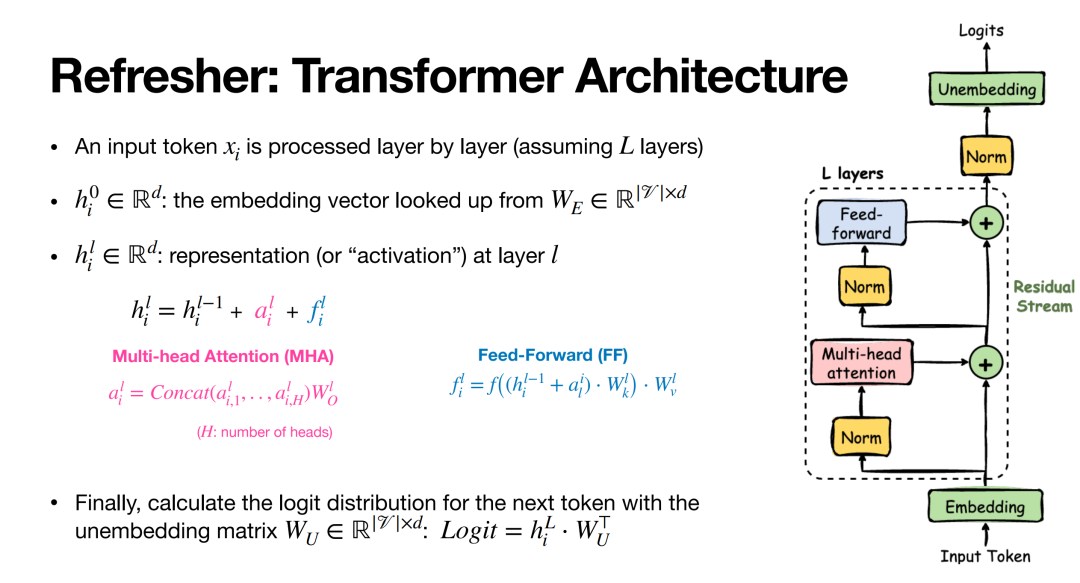
机械可解释性(Mechanistic Interpretability,简称 MI)是可解释性研究中一项新兴的子领域,其目标是通过对神经网络模型内部计算过程的逆向工程,来理解模型的工作机制。近年来,MI 在解释基于 Transformer 的语言模型(Language Models, LMs)方面引起了广泛关注,催生了诸多新颖的研究洞见,但同时也带来了新的挑战。鉴于该主题正迅速吸引机器学习与人工智能社区的高度兴趣,本教程旨在为语言模型的 MI 研究提供一个全面的综述内容,包括其发展背景、具体实现与评估技术、基于 MI 的研究发现与应用,以及未来面临的挑战。 本次教程将特别基于主讲人精心整理的《MI 初学者路线图》(Beginner's Roadmap to MI)展开,旨在帮助刚接触 MI 的研究者快速入门,并在其语言模型应用中有效利用 MI 技术。





成为VIP会员查看完整内容
相关内容
Arxiv
214+阅读 · 2023年4月7日

相关VIP内容
相关资讯
相关论文
Arxiv
214+阅读 · 2023年4月7日