

自然语言处理(NLP)领域的进步历来依赖于更优质的数据,而如今,研究者们越来越多地使用“合成数据”——即借助大型语言模型(LLMs)生成的数据——以加快数据集构建流程并降低成本。 然而,大多数合成数据生成方法仍是临时拼凑、各自为战的,常常“重复造轮子”而不是在已有成果的基础上前进。为此,本教程旨在从自然语言处理及相关领域中,系统梳理合成数据生成的最新进展,构建统一的理解框架,并对主流方法、应用场景与尚未解决的问题进行分组归纳与深入描述。
本教程将分为四个主要部分: 第一部分,我们将介绍如何设计高质量合成数据的生成算法; 第二部分,将探讨如何利用合成数据推动语言模型的通用开发与研究; 第三部分,我们将展示如何定制合成数据生成过程以支持特定应用场景; 最后,我们将讨论围绕合成数据的生成与使用仍存在的开放性问题,以及当前亟待解决的局限。 我们的目标是:通过整合这一新兴研究方向中的近期进展,为社区建立一个稳固的研究基础,从而推动合成数据在理论严谨性、应用理解和生成效果等方面的进一步提升。

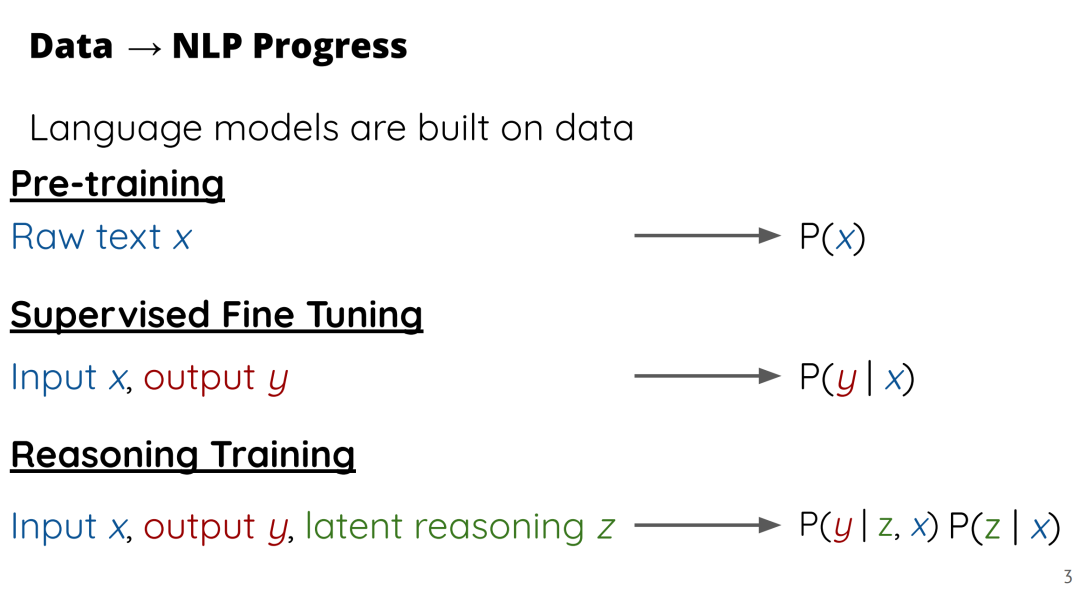

成为VIP会员查看完整内容
相关内容
专知会员服务
72+阅读 · 2022年3月15日
Arxiv
214+阅读 · 2023年4月7日
Arxiv
84+阅读 · 2023年3月21日
相关VIP内容
专知会员服务
72+阅读 · 2022年3月15日
相关资讯
相关论文
Arxiv
214+阅读 · 2023年4月7日
Arxiv
84+阅读 · 2023年3月21日