
作者:王寄哲,张伟男,刘挺 机构:哈尔滨工业大学计算学部人工智能学院 社会计算与交互机器人研究中心
本文转载自中国计算学会会刊《计算》2025年第4期专题文章《视觉-语言-动作(VLA)模型的前世今生》 摘要:近年来,视觉-语言-动作模型(vision-language-action model, VLA)迅速成为人工智能领域的热点。自2023年起,随着谷歌RT-2等成果的亮相,VLA因突破性的“多模态感知-决策-执行一体化”能力引发广泛关注。相较于传统模块化方案,VLA凭借对成熟LLM、VLM路线的继承,通过端到端架构实现从文本图像理解到动作生成的直接映射,大幅提升了机器人在动态环境中的泛化能力。随着技术演进,VLA的定义被不断拓展,扩散模型、流匹配的引入使动作生成更加高效,隐动作充当标记达成与VLM原生模态的语义对齐、分层结构形成“快慢脑”进一步冲击复杂任务,技术路线的多元化标志着VLA进入快速发展时期。这种“百家争鸣”的局面既体现了技术潜力,也暴露了局限性——可解释性缺乏、实时性不足、混合架构训练困难。尽管前景广阔,众多问题仍亟待研究者去解决。未来,VLA的进化或将重塑人机协作范式。若突破空间感知与场景探索瓶颈,机器人不仅能完成简单的重复性任务,更能自由探索与世界交互。比如结合群体智能技术,多台VLA驱动的机器人可协作完成救灾、手术等复杂任务。正如计算机视觉曾赋予机器“眼睛”,VLA正在赋予机器“手脚”与“物理知识”——这场始于对“具身“能力追求的变革,终将推动人工智能从虚拟助手向实体伙伴跨越。 关键词:具身智能;视觉语言模型;大语言模型;机器人;生成式人工智能;空间感知;场景探索
引言
视觉-语言-动作模型(vision-language-action model, VLA)在2023年7月谷歌DeepMind发布RT-2模型时首次被正式提出,引发了学术界对多模态感知与机器人动作一体化的广泛关注。随后,斯坦福大学等机构于2024年发布OpenVLA开源框架,进一步促进了社区对VLA研究的热情与VLA的多样化发展。 VLA之所以被认为有前景,主要是因为它将视觉、语言和动作3种模态统一到同一语义空间,使机器人能够通过端到端的方式直接将图像观察和文本指令映射到物理动作,上下文理解和泛化能力显著增强。 如图1所示,传统机器人系统通常采用模块化设计,如分别训练感知、规划和控制模块,这种方法易受单个模块误差影响并难以实现跨任务的泛化。相较之下,VLA端到端框架可以减少模块间传递的累积误差,并凭借预训练大规模视觉语言模型所带来的丰富语义理解,使机器人在未见场景中也能具有零样本或少样本执行能力。此外,VLA模型通过提取大规模互联网数据中的知识,可获得强大的语义推理能力,从而支持开放域指令的理解和执行,比传统机器人只能执行预定义动作的方案更具灵活性。 自RT-2模型发布以来,来自全世界的诸多研究团队陆续提出使用扩散模型生成动作、视频生成模型做主干等多样化的技术路线,形成了百家争鸣的局面,进一步验证了VLA研究方向的活力和潜力。VLA模型通过整合多模态预训练、大规模数据和端到端控制,为具身智能提供了前所未有的感知-认知-执行一体化能力。
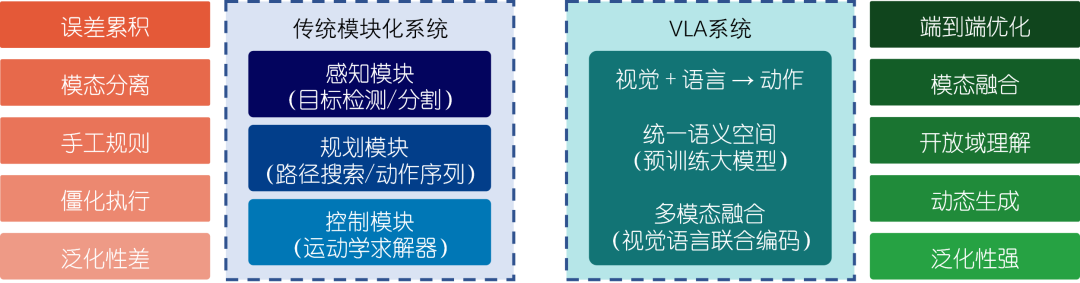
图1 传统模块化系统与VLA系统的对比
VLA的诞生——大模型对机器人操作的赋能
当GPT-4以前10%的成绩通过美国律师执照考试、AlphaFold2预测出2亿种蛋白质结构时,大模型展现的不仅是技术突破,更是一种认知范式的颠覆——它们从海量数据中提取出抽象规律,不断逼近甚至超越掌握领域知识的人类专家。越来越多的案例显示,大模型已具备跨模态关联与隐性知识发现的能力。这种能力的溢出效应正在突破数字世界的边界,向物理世界进军。如果能将大模型的“认知中枢”与机器人的“运动肌肉”相连,具身智能将获得指数级的能力跃迁。 然而,一位先天失明但精通光学理论的科学家,虽能熟练推导出彩虹形成的折射公式,却一生遗憾于无法感知真正的颜色,他对视觉的理解永远停留在数学符号的排列组合——这就是当前大模型与物理世界相割裂的写照。 大语言模型(large language model, LLM)能精确解释“力是物体对物体的相互作用”,却不能感受抓握玻璃杯时指尖压力的起伏;视觉-语言模型(vision-language model, VLM)能识别人类做家务时场景的变化,却无法体会如何作为能动主体改造世界。它们用自己万亿参数的知识储备尝试触摸一个不属于自己的维度,但永远无法突破模态的边界,就像人永远无法想象一个不存在的感官。 2023年,谷歌DeepMind的RT-2模型撕开了这道认知鸿沟。其革命性在于将机器人动作加入到语言模型的输出序列中:图像像素、文本指令与机器人动作被映射到统一语义空间,大模型具备了理解动作的可能性。在提出RT-2模型的原始论文中,VLA被首次提及:这种模型基于已有的视觉语言大模型,将低级动作直接融合到主干模型中,从而获得开放域语言视觉理解+具身控制的统一能力。架构复用、生态沿袭,具身智能搭上了大模型这趟快车。 如果说RT-2点燃了VLA的火种,OpenVLA等开源项目则让星火燎原。2024年发布的OpenVLA框架,首次开源了VLA训练基础设施,开源社区迅速涌现出各类变体:TinyVLA进行增速,凭借更高的数据效率获得更快的推理速度;MiniVLA进行瘦身,将参数量压缩到原来的1/7,但性能几乎不受影响;OpenVLA-OFT进行扩展,集成了更多的动作解码方案、动作表示形式以及学习目标……这些工作共同构建起VLA的“技术基座”,让研究者不必重复造轮子,转而专注于具身智能的本质问题——如何让机器掌握物理规则。
VLA的发展——百家争鸣的技术路线
验证了“视觉-语言-动作”三模态对齐的可行性后,研究者们意识到:RT-2现有的框架只是一个开始,由虚向实的转变还需要极多的尝试和极大的努力才可能实现。要让智能体真正掌握物理世界的运作规律,需要突破传统框架的局限,在推理机制、动作建模、多模态融合等层面展开更深刻的革新。恰如百家争鸣时期多元思想交锋的盛况,VLA技术正在经历范式重构、路线爆发。 一些工作基于RT-2所提出的传统VLA进行增量改进,在保持原有结构不变的情况下扩展新能力。历史信息对提高任务成功率大有益处,ICRT(In-Context Robot Transformer)真正将自回归模式引入VLA,通过拼接文本、图像、动作,模型可以学习到上下文中的信息,持续不断地预测“下一个token”,这让VLA与LLM、VLM的范式更加接近。传统VLA直接从感知输入映射到动作输出,这就像要求人类不假思索地完成复杂操作,ECoT(Embodied Chain-of-Thought)的突破在于,它将语言模型的“思维链”机制引入具身智能,显式的中间表征层可以被看作是机器人的“思维空间”,这种“慢思考”机制,给VLA提供了一种新的决策范式。 还有一些工作突破了RT-2中所提到的“复用视觉语言大模型,无需新增模块”的限制,将扩散模型作为动作生成插件加入VLA中。机器人动作空间具有精细密集性,离散建模极易失真,使用扩散模型直接对连续动作块进行建模,一次预测多个动作,可以减少累积误差并增强时序一致性。π₀引入流匹配模型,在原有的VLM主干上并联一组参数,充当去噪网络生成动作。DexVLA(Diffusion expert for VLA)则直接将扩散动作策略头串联在VLA主干之后,以VLM主干生成的动作标记作为输入,去噪生成动作。事实上,无论是在VLM主干上并联还是串联新的模块,都依旧保留了传统VLA的主体,并没有彻底颠覆其定义。不过与此同时,也有越来越多的学者将VLA这一概念扩大化,所有包含“视觉”、“语言”、“动作”模态的端到端模型,都被认为是广义上的VLA,因此,我们看到Diffusion Policy、Octo、RDT-1B这类直接使用扩散主干、甚至规模较小的模型也被纳入VLA家族。 从“多模态端到端模型”的角度来看,宽泛的定义会将更多的技术路线纳入VLA范畴,例如视频生成模型路线。视频包含丰富的世界动态实例,视频生成模型很好地学习到了其中的知识,将其作为VLA的主干将助力机器人策略学习。GR-2在38M条文本-视频对数据上做自回归视频生成预训练,并在机器人数据集上进行微调,使得一个统一的模型可以同时输出未来帧与机器人动作块,利用“生成视频”做中间监督,大幅增强空间与时序理解。Gen2Act、VidMan(Video Diffusion for Robot Manipulation)、VPP(Video Prediction Policy)等模型也通过串联、层级适配器、潜表示提取等方式添加动作模块。值得一提的是,一个具有物理和空间能力的视频生成模型,也被认为是世界模型的一种。 这场变革正在重塑图灵测试的内涵——真正的智能不仅需要理解世界,更要能优雅地改变世界。
VLA的挑战——现有大模型并非全知全能
当前VLA的繁荣本质上是一场“技术嫁接”——研究者将成熟的视觉语言模型(VLM)、视频生成模型等多模态模型作为基础骨架,通过添加动作输出头构建端到端流水线。这种路径的先天优势显而易见:RT-2复用PaLI-X的55B参数视觉语言骨干,使机器人轻松掌握“易拉罐”与“垃圾回收”之间的的关联;OpenVLA继承了SigLIP和DinoV2视觉编码器的的图文对齐能力,即使训练时只见过红色积木,部署时也可以很好地理解没见过的蓝色积木。然而,这种“站在巨人肩膀上”的策略给VLA带来一波高速发展后,正在逐渐暴露其最大的弱点——再完美的“非具身能力”也无法掩盖脆弱的“具身能力”所带来的短板。 所谓具身能力,是指支撑机器人作为实体与世界交互所需要的能力,VLA的具身能力极度缺乏。多模态大模型的空间感知能力十分薄弱,即使面对最简单的“左右”“远近”问题,大模型也经常会回答错误,模型虽然能识别场景中的物体,却并不掌握对物体之间的空间拓扑关系进行几何建模的能力。多模态大模型几乎没有场景探索能力,如果你向模型提问“冰箱里面有什么”,它更倾向于靠自己的预训练常识去“盲猜”出答案,而不会提出“打开冰箱看看”的交互方案。解决具身能力短板的办法似乎很简单——缺乏空间感知能力是因为模型没有见过3D数据,缺失场景探索能力是因为没有给模型提供调用硬件的示例,只要补足这些数据,就能让VLA变成“完整的”具身智能体。可事情并非如此简单。 想做好某个下游任务,只用相对少量的数据针对单一任务进行训练是远远不够的。哪怕上千万的中英双语对照书籍也很难让模型学会“信达雅”地完成英译中任务,当今的大模型所具备的强大翻译能力,实际上来源于穷尽互联网的文本语料,而并不只来源于双语对照数据。同样,加入3D数据的确能让VLA以更高的正确率回答“远还是近”的问题,但这种指标的提升往往来自于对单一任务的过拟合,严重缺乏泛化性和可迁移性。能够带来“真正的具身智能”的,一定是对具身能力的全方面训练。 大模型是“吃数据长大的巨人”,互联网上的文本、图像、视频数据已经几乎涵盖这个世界的一切语言、视觉信息,遗憾的是,现实世界的交互行为却从未被完整记录,来自实验室的机器人数据也存在众多缺陷。一方面,具身数据集规模极小:图文数据集OmniCorpus中的图文对已达百亿级别,视频字幕数据集Panda-70M中的视频字幕对数量也来到了7000万条,而最大的开源机器人数据集Open X-Embodiment仅包含不到200万条轨迹。另一方面,具身数据集分布单一:当前数据集重点关注桌面操作,其中绝大部分又是拾放任务,在如此狭隘的分布上训练模型,是模型没有在开放环境中表现优异的可能。 在种种客观条件限制下,VLA还远不是一位“巨人”,它对重力惯性的无知、对摩擦力的误判、对空间关系的错觉都告诉我们,VLA距离掌握真正的具身能力还有很长的路要走。针对具身智能的研究已经开展多年,VLA的技术路线也日新月异,然而这场现实物理世界对VLA的考试才刚刚开始。
VLA的未来——具身能力需要突破
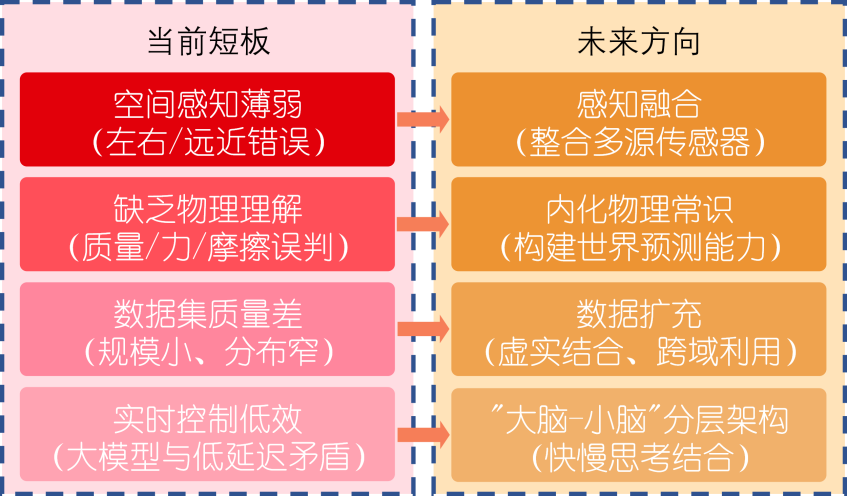
图2 VLA当前短板与未来方向 VLA的核心矛盾在于认知架构与物理世界的脱钩:多模态模型在语言、视觉空间中构建的“动作”概念(如“抓取”“旋转”,甚至是坐标角度等更加低级的表达)无法逃出原有模态的限制,难以对质量、力等物理概念有真正的理解。想要让VLA从实验室走向现实世界,需要在感知、认知、执行三层面重构技术范式。 感知方面,当前VLA对视觉-语言模态的依赖如同只赋予机器人“眼睛”和“耳朵”,却没有赋予它触觉与力觉,突破点在于跨模态传感器的信息融合。如果触觉传感器甚至仿生皮肤能在机器人硬件层面普及,当机器人抓取易形变、易破损物体时,触觉信号就可以实时修正视觉定位误差,避免物体损坏。如果机器人的本体感知得以增强,能够通过硬件的微形变感受力的变化,那在精细操作任务中,通过被操作物体的细微反馈确定物体状态就成为可能。如果多源数据能够被对齐,点云、力矩、声波等物理信息被映射到多模态大模型的统一表示空间,那么具身知识与非具身知识就可以进行跨模态迁移。 认知方面,当前的多模态大模型擅长回答“这是什么”“在哪里”,却难以回答“如果我这样做,会发生什么”,要让VLA理解“轻轻推倒积木塔会导致其缓慢倾斜、顶层积木坠落”,而非笼统地认为“积木塔会倒”,关键在于赋予其内化的物理常识和动态推演能力,从而实现预见性和安全决策。例如基于世界模型预测多步未来状态,反映出不同动作序列的长期结果,从而辅助规划;将物理常识内化入VLA,让经典物理定律、几何约束、材料属性嵌入模型中,让模型对物理现象有切实的理解和精准的计算;借鉴人类认知的“双过程理论”,构建VLA的快慢思考系统,处理复杂任务时进行更深入的分析、规划、验证,面对简单任务则直接依赖直觉反应能力。 执行方面,VLA想要对机器人硬件进行鲁棒、精确、高效地运动控制,既要保留大规模预训练模型所带来的泛化性和通用性,又要兼顾动作策略所必需的细粒度和控制效率。“大脑”与“小脑”要做到既区别又统一:区别在于模型结构,泛化性所需的大参数量与控制效率所需的低延迟具有天然的互斥性,不加以区别使用完全一致的设计很难两全;统一在于语义对齐,借助泛化模型所产生的高信息量表示,将丰富的先验以高度压缩的形式传递给控制策略,达到质量与速度的最佳平衡点。同时,模型轻量化技术、高效推理架构、闭环反馈校准机制也有望助力VLA执行能力的发展。 未来,随着异构传感硬件的普及、虚实联合训练平台的完善以及可解释大模型架构不断成熟,VLA将会突破“只会想象”的局限,真正做到“知行合一”。在此基础上,多机器人协作将成为下一个重要方向,借助群体智能技术,多台VLA驱动的机器人可以共享环境理解和任务策略,共同应对复杂场景中的协同操作需求,如灾后搜救和手术辅助等高风险任务。最终,当VLA具备完整的具身能力后,机器人将不再是被动执行指令的工具,而能像人类伙伴般自由探索、学习和自主协作,由此推动人工智能从虚拟助手向实体伙伴的跨越,进入真正的具身智能时代。
作者介绍

王寄哲 CCF学生会员。哈尔滨工业大学人工智能学院硕士研究生。主要研究方向为具身智能。

张伟男 CCF理事、CCF杰出会员,CCF哈尔滨分部主席,CCF术语审定工作委员会执行委员。哈尔滨工业大学人工智能学院执行院长兼计算学部副主任,教授。主要研究方向为大模型、社交机器人、具身智能。

刘挺 CCF会士,CCF科技成果评价委员会委员。哈尔滨工业大学党委常委,副校长,教授,主要研究方向为人工智能、大模型、社会计算、具身智能。
参考文献
[1] Zitkovich B, Yu T, Xu S, et al. Rt-2: Vision-language-action models transfer web knowledge to robotic control[C]//Conference on Robot Learning. PMLR, 2023: 2165-2183. [2] Kim M J, Pertsch K, Karamcheti S, et al. OpenVLA: An Open-Source Vision-Language-Action Model[C]//Conference on Robot Learning. PMLR, 2025: 2679-2713. [3] Achiam J, Adler S, Agarwal S, et al. Gpt-4 technical report[J]. (2023-03-15) [2025-07-04]. https://arxiv.org/abs/2303.08774. [4] Jumper J, Evans R, Pritzel A, et al. Highly accurate protein structure prediction with AlphaFold[J]. nature, 2021, 596(7873): 583-589. [5] Wen J, Zhu Y, Li J, et al. Tinyvla: Towards fast, data-efficient vision-language-action models for robotic manipulation[J]. IEEE Robotics and Automation Letters, 2025, 10(4): 3988-3995. [6] Belkhale S, Sadigh D. Minivla: A better vla with a smaller footprint, 2024[J]. (2024-06-13) [2025-07-04]. https://github. com/Stanford-ILIAD/openvla-mini. [7] Kim M J, Finn C, Liang P. Fine-tuning vision-language-action models: Optimizing speed and success[J]. (2024-02-27) [2025-07-04]. https://arxiv.org/abs/2502.19645. [8] Fu L, Huang H, Datta G, et al. In-context imitation learning via next-token prediction[J]. (2024-08-28) [2025-07-04]. https://arxiv.org/abs/2408.15980.[9] Zawalski M, Chen W, Pertsch K, et al. Robotic Control via Embodied Chain-of-Thought Reasoning[C]//Conference on Robot Learning. PMLR, 2025: 3157-3181. [10] Black K, Brown N, Driess D, et al. π0: A vision-language-action flow model for general robot control [J]. (2024-10-31) [2025-07-04]. https://arxiv.org/abs/2410.24164. [11] Wen J, Zhu Y, Li J, et al. Dexvla: Vision-language model with plug-in diffusion expert for general robot control[J]. (2025-02-09) [2025-07-04]. https://arxiv.org/abs/2502.05855. [12] Chi C, Xu Z, Feng S, et al. Diffusion Policy: Visuomotor Policy Learning via Action Diffusion[J]. (2023-03-07) [2025-07-04]. https://arxiv.org/abs/2303.04137. [13] Team O M, Ghosh D, Walke H, et al. Octo: An open-source generalist robot policy[J]. (2024-05-20) [2025-07-04]. https://arxiv.org/abs/2405.12213. [14] Liu S, Wu L, Li B, et al. Rdt-1b: a diffusion foundation model for bimanual manipulation[J]. (2024-10-10) [2025-07-04]. https://arxiv.org/abs/2410.07864. [15] Cheang C L, Chen G, Jing Y, et al. Gr-2: A generative video-language-action model with web-scale knowledge for robot manipulation[J]. (2024-10-08) [2025-07-04]. https://arxiv.org/abs/2410.06158. [16] Bharadhwaj H, Dwibedi D, Gupta A, et al. Gen2act: Human video generation in novel scenarios enables generalizable robot manipulation[J]. (2024-09-24) [2025-07-04]. https://arxiv.org/abs/2409.16283 [17] Wen Y, Lin J, Zhu Y, et al. Vidman: Exploiting implicit dynamics from video diffusion model for effective robot manipulation[J]. Advances in Neural Information Processing Systems, 2024, 37: 41051-41075. [18] Hu Y, Guo Y, Wang P, et al. Video prediction policy: A generalist robot policy with predictive visual representations[J]. (2024-12-19) [2025-07-04]. https://arxiv.org/abs/2412.14803.


