

尽管 直接偏好优化(Direct Preference Optimization, DPO) 在对齐大语言模型(LLMs)方面取得了良好效果,但 奖励劫持(reward hacking) 仍是一个关键挑战。当 LLM 过度降低被拒绝生成的概率以追求高奖励时,却未真正实现预期目标,从而导致生成结果 冗长、缺乏多样性,并引发 知识灾难性遗忘。
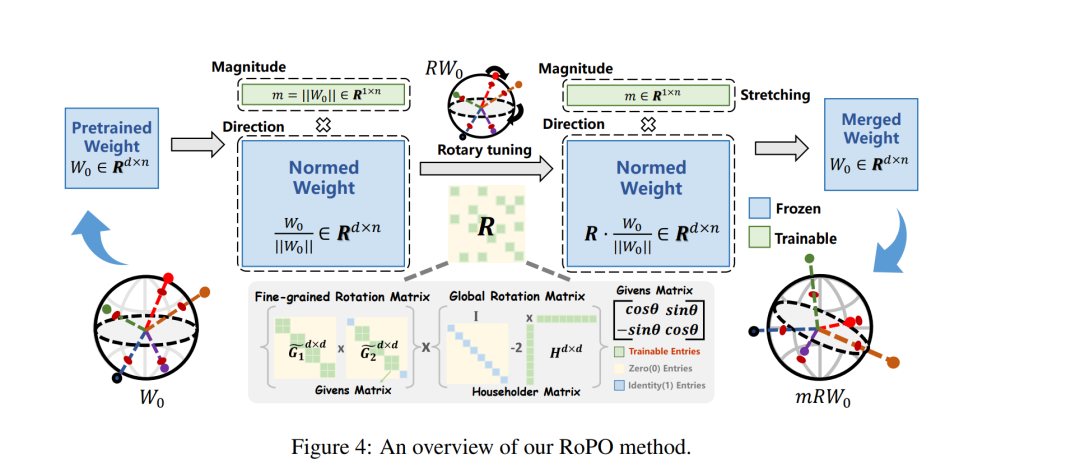
我们将这一问题的根本原因归结为 参数空间中的神经元坍缩(neuron collapse)所导致的表征冗余。为此,我们提出了一种新颖的 权重旋转偏好优化(Weights-Rotated Preference Optimization, RoPO) 算法:其设计在 输出层 延续了 DPO 中的 KL 散度约束,以隐式限制 logits 的偏移;同时在 中间隐含层状态 上引入 多粒度正交矩阵微调 的显式约束。该机制有效防止策略模型过度偏离参考模型,从而保留预训练与监督微调阶段所获得的知识与表达能力。
在实验中,RoPO 在 AlpacaEval 2 上带来了最高 0.5 分 的提升,并在 MT-Bench 上以仅 0.015% 的可训练参数 超越最佳基线 1.9 至 4.0 分,充分验证了其在缓解 DPO 奖励劫持问题上的有效性。
成为VIP会员查看完整内容
相关内容
Arxiv
217+阅读 · 2023年4月7日
Arxiv
20+阅读 · 2023年3月21日
相关主题

相关VIP内容
相关资讯
相关论文
Arxiv
217+阅读 · 2023年4月7日
Arxiv
20+阅读 · 2023年3月21日