

近几十年来,私营公司和政府机构对网络安全的需求都在增长。这种增长是由于各组织发动网络攻击的能力不断增强的结果。作为回应,各组织一直在开发网络防御人工智能(AI),这大大提高了网络安全能力。这不仅需要开发网络攻击、防御和漏洞框架,以模拟现实环境,还需要有训练人工智能的方法。此外,网络的数量和种类需要一个框架,可以快速和低成本地训练人工智能。本文将探讨我们的团队如何努力开发一个高效和全面的框架,在这个框架下,各种人工智能可以被训练以满足网络弹性的需要。
1 引言
网络安全是现代组织和政府的最大考虑之一。在网络威胁情报领域公认的领导者Check Point研究公司所做的一项研究中,他们发现在2020年,试图对企业进行的网络攻击数量增加了50%(Mello, 2022)。鉴于网络攻击的增加及其复杂性,预计2022年仅美国的组织的网络安全支出将高达1720亿美元,这并不奇怪(Pratt, 2021)。其他国家如乌克兰,也经历了类似的攻击数量和其复杂性的急剧增加。在2020年的一篇文章中,作者发现台湾自1999年以来一直遭受网络攻击,这些攻击的复杂性足以危及电力系统,并导致大规模停电,就像在乌克兰前线看到的那样(Huang,2020)。攻击和防御成本预计只会增长,几乎没有期望网络安全防御能力超过攻击能力;这是防御者在当前的网络空间环境中经历的固有劣势的结果。
网络安全专业人员目前没有足够的防御工具来应对网络攻击的必要。网络安全的相对无效性是由于网络防御所面临的劣势造成的。Wendt将防御的劣势归功于有利于攻击者的网络冲突的性质(Wendt, 2019)。他继续说,攻击者识别和利用一个漏洞,而防御者必须识别和缓解每一个漏洞。攻击者可以选择何时发起攻击,而防御者必须首先识别攻击,然后才能做出反应。攻击者可以重复使用类似的攻击来利用类似的漏洞,而防御者必须在许多独特的系统中进行协调,以确定共同的漏洞并制定缓解措施。攻击者如果失败,不会产生巨大的成本,而防御者的网络如果失败,则会受到巨大的损害。如果防御者不能识别攻击并迅速作出反应,攻击者将有更多的时间深入到系统中。这使得攻击者可以破坏网络,并创建后门,用来进一步伤害网络。为了努力提高防御者的响应时间和有效性,网络安全专业人员使用网络兵棋推演的方法进行练习。
网络兵棋推演是对真实攻击的模拟,攻击方试图破坏网络,而防守方则试图阻止这种攻击。网络兵棋推演使网络安全从业者能够发展他们的能力,改善他们的网络,并最终更快、更有效地作出反应。然而,历史上网络安全支出的增加和网络兵棋推演本身并没有被证明是足够的。虽然它提高了响应时间和有效性,但网络兵棋推演并不能使网络安全专业人员对威胁做出足够快的反应。此外,目前的网络安全方法是非常昂贵的。白宫报告说,总统为2023财政年度分配了 "109亿美元的预算授权,用于民用网络安全相关活动"。这比2022年增加了 "11%",显示了发展网络安全的强烈需求(白宫,2022)。
网络防御从业者可以使用强化学习(RL),人工智能的一个子集,来开发满足高效和近乎即时反应的智能体。强化学习的目标是让智能体对各种不同的刺激选择最佳行动,这些刺激是提供强化学习环境刺激。强化学习的功能是使用一组由强化学习环境更新的可能行动。在这组可能的行动中,有最佳行动,这是由环境决定的。智能体通过目标函数的奖励来学习哪些行动是最优和次优的。智能体试图找到对环境刺激的正确反应,使目标函数的奖励最大化。关于人工智能和RL的补充信息可以在Sewak, Sahay, and Rathore (2022)中找到。为了使用RL训练防御智能体,需要环境刺激来提示防御智能体的反应。通过使用网络兵棋推演的方法,RL攻击智能体模拟网络攻击,可以提供刺激,以有效的方式训练防御智能体。
应对许多独特网络中压倒性的和不断增长的网络威胁正变得越来越昂贵,而且很难由人类网络安全从业者来实现。这项研究的重点是开发一个全面的框架,通过它可以训练许多RL防御智能体。这个框架将利用网络兵棋推演的方法来模拟攻击和防御智能体之间的相互作用,允许快速和具有成本效益的网络防御智能体的训练。
2 相关工作
虽然已经有很多关于使用人工智能来补充网络安全的研究,但还没有重要的文献从同样的角度来探讨这个问题。我们的问题主要是利用知识库创建一个通用的RL训练框架,而其他的研究则主要是利用预先建立的训练数据创建一个特定的防御或攻击智能体。在Nguyen和Reddi(2021)中,作者讨论了RL智能体在网络物理系统安全方法中的应用以及在针对网络攻击的防御策略的博弈论模拟中的应用。
为了继续研究RL智能体在网络物理系统安全中的应用,他们使用了一系列现实世界的例子,并试图应用一个强大的模型作为解决方案。在这项研究中,发现尽管他们可以构建一个能够提供有效自主防御的智能体,但有一些攻击技术导致自主系统失败。因此,为了提高他们的智能体的鲁棒性,他们不得不重组和重新训练他们的智能体(Nguyen & Reddi, 2021)。这种将RL应用于网络安全的做法,在防御单个或非常相关的网络,对抗已知的攻击者方面是可行的。然而,使用从许多攻击者那里汇编的不同数据来构建和训练许多独立的智能体提出了一个成本-效益问题。能够使用一个通用的训练框架来训练许多智能体,通过行业标准的知识库,可以为系统提供更大的复原力。
在Nguyen和Reddi(2021)中,作者介绍了一个使用博弈论的RL的网络安全应用,其中多个防御智能体在模拟中被训练以应对不同类型的攻击。在这项研究中,他们讨论了训练智能体来应对干扰攻击、欺骗攻击和恶意软件攻击。与他们将RL智能体应用于网络物理系统一样,通过这种方法训练的智能体看到了合理的成功。然而,在每种情况下,智能体都需要进行重大的微调,以正确应对它所防御的特定类型的攻击。此外,当攻击者的输入是随机的,或者在训练智能体的数据集中没有很好的记录时,智能体就会陷入困境(Nguyen & Reddi, 2021)。在现实世界的场景中,攻击者有许多不同的潜在攻击可以使用。我们的团队提出的训练方法,通过允许快速训练许多智能体,并使用行业内组织不断更新的庞大知识库来解决这一弱点。因此,除非攻击者使用新的攻击方法,否则智能体应该有能力做出反应。下一节将讨论这个训练框架是如何开发的。
3 方法
防御是网兵棋推演的一个重要方面,因为它涉及到保护计算机系统和网络免受对手的攻击。在网络战争中,防御通常是通过预防措施(如防火墙和访问控制)与反应措施(如事件响应和恢复)的结合来实现的。在网络战争中,防御的目标是最大限度地减少攻击的影响,防止对手对系统或网络造成重大损害。为了实现这一目标,防御者必须了解攻击者使用的战术、技术和模式,并制定有效的反措施,以适应不断变化的威胁环境。通过开发攻击人工智能,可以模拟许多攻击场景,从而使防御智能体得到训练。
3.1. 本体
为了更好地理解攻击和防御之间的关系,我们开发了一个本体。本体是概念之间的关系的图形表示,包括直接的和推断的。因为这个项目的重点是开发一个框架,通过这个框架可以使用来自攻击智能体的刺激来训练防御智能体,必须建立两个智能体如何互动的规则来建立网络兵棋推演模拟。复杂的关系网络在本体论中得到了最好的理解,它说明了网络、攻击者和防御者之间的关系。这个本体论可以在图1中看到。网络漏洞(也被称为共同弱点列举,或CWE)是网络中可以被利用的因素。CWE是被对手的攻击模式所利用的。每个攻击模式都被分配了一个编号或共同攻击模式列举和分类(CAPEC)。CAPEC是对一种攻击技术所利用的途径的分类。攻击技术实现了一个更普遍和总体的攻击战术,以实现攻击模式和利用漏洞。
用于本框架并由图1中的本体论告知的概念将保持不变。攻击智能体选择一种攻击技术,使用CAPEC来利用CWE。然后,防御智能体将使用防御技术来抵御攻击技术。每个行动和反应都会更新环境,并提示其他智能体在回合制模拟中采取行动。然而,网络攻击的复杂性是这样的,在他们的最终形式中,攻击或防御智能体都可能有成千上万的可能行动。这个项目的目标是创建一个最小可行的产品,作为一个可以附加的框架。因此,暂时选择一小部分攻击技术和相应的防御技术作为概念验证。所选的攻击技术子集是默认账户、网络会话Cookies和软件部署工具。为防御这些攻击技术而选择的最佳防御技术分别是账户锁定、入站流量过滤和活动目录配置。除了这些技术外,还随机选择了其他几种技术,以便智能体必须探索其选项并选择最佳技术。在确定了智能体在网络兵棋推演模拟中可以使用的技术后,我们继续开发智能体之间的互动性。
从图1中的本体论来看,防御技术是用来防御攻击技术的。防御智能体对攻击智能体所采取的行动作出反应,实施防御战术,打击攻击智能体的相应行动。有几种可能的防御技术,防御智能体可以从中选择。除了提供每种技术和战术的属性外,本体还提供了攻击和防御智能体之间的直接关系。具体来说,本体论告知防御技术是否是防御每种攻击技术的正确选择。防御技术的最佳答案是:默认账户的账户锁定,网络会话Cookies的入站流量过滤,以及软件部署工具的活动目录配置。
在其最终形式中,防御智能体将有更多可能的答案可以选择,并有不同的回报,因为有些选项是次优的。然而,为了建立一个有效的框架,该智能体以最不复杂的方式开发。
这迫使智能体学习这些选项是特定攻击智能体的最佳答案。通过奖励防御智能体选择最佳防御技术,智能体的行为将得到加强,它将训练自己正确对抗攻击智能体。然而,网络兵棋推演的玩法类似于回合制游戏。攻击智能体必须采取行动,然后防御智能体必须作出反应。我们的团队帮助开发了互动框架,智能体可以通过这个框架进行兵棋推演,以训练防御智能体。
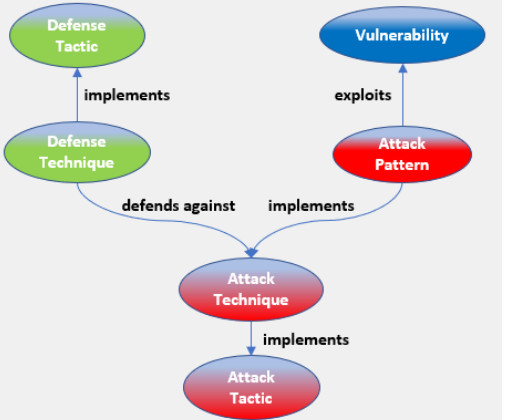
图1:网络兵棋本体。本体是攻击技术和防御技术如何通过攻击模式和漏洞相互作用。这是整个本体的简化版本。
3.2. 创建场景
在图1的本体中,防御和攻击智能体通过防御技术与攻击技术进行互动。我们的团队选择了攻击智能体使用的攻击技术,并通过相应的防御技术进行防御。在建立防御智能体时,在现实的复杂性和必要的简单性之间一直保持着平衡。有数以百计的攻击技术可以,并最终将被添加到攻击智能体中。然而,为了保持故障排除的可控性,我们将攻击技术的数量限制在三种,每种都有相应的防御技术。虽然只有三种可能的攻击技术是不现实的,但它建立了一个可以扩展的框架。同样,一个防御智能体通常在任何时候都会有超过150种可能的防御技术,但在原型开发中只提供了10种可能的反应。同样重要的是要注意,通常情况下,当使用RL训练一个智能体时,最佳选择是未知的。然而,为了建立一个概念验证,我们的团队根据行业标准选择了已知的最佳行动(MITRE ATT&CK企业矩阵,n.d.)
选择的三种攻击技术分别对应于攻击的不同阶段。第一阶段是初始访问,其中默认账户是攻击智能体利用的攻击技术。初始访问是一种由许多攻击技术组成的攻击战术,这些技术的目标是允许攻击者访问网络。具体来说,"默认账户 "是一种攻击技术,其目标是网络上存在的不受监控的账户,以获得访问权。相应的防御技术是账户锁定,它阻止用户以指定的账户访问网络。攻击的下一阶段是攻击者如何通过网络移动以到达目标节点,由横向移动攻击技术进行。在这个阶段,智能体选择利用的攻击技术是Web Session Cookies。网络会话Cookies技术针对的是网络浏览器上当前激活的cookies。这些cookies允许智能体绕过认证,因为认证在网络会话上已经激活。相应的防御技术是入站流量过滤,它可以防止网络会话以这种方式被利用。攻击的最后阶段是在目标节点上运行一个可执行文件,以损害网络或获取敏感信息。这个阶段的攻击策略是执行。所选择的攻击技术是软件部署工具,它是在目标节点上运行的可执行文件,可以以多种方式损害网络。这个文件的执行可以被活动目录配置防御技术所阻止。在选择了攻击和防御技术之后,两个智能体之间的逻辑关系就建立起来了,可以开发两者之间的互动。(MITRE D3FEND, n.d.)
3.3. 机器学习环境
攻击和防御智能体之间的互动框架被捕获在RL环境中。从图2中,我们看到程序在环境和RL智能体之间运行一个循环。这个循环从环境开始,为智能体提供网络信息。环境引用网络知识库来检查每个节点的脆弱性,以便以后在智能体创建行动时使用。给出的信息被编译成一个矩阵,其中包含网络访问状态、网络设备访问状态和软件列表。对于列表中的每一部分,网络访问状态被定义为1或0,代表智能体可以访问网络(1)或智能体不能访问(0)。这与网络设备类似,因为它要么是1,要么是0。 软件列表表示智能体正在攻击的特定节点,因为对于特定的攻击,它需要一个特定的软件,如果节点没有这个软件,攻击者需要另一种方法来获得访问。一旦智能体采取了行动,它将选择一个攻击模式和漏洞进行攻击,以获得对特定节点的访问。在智能体选择行动后,环境将被通知并更新环境,并根据智能体的选择是否正确给智能体以奖励。该程序将重复这个循环,直到智能体获得对目标节点的指挥和控制。对于初始训练,有一个假设,即每个节点只有一个最佳答案。如果没有这个假设,智能体就会学会采取我们不希望它学会的行动,如不采取行动或选择次优行动。
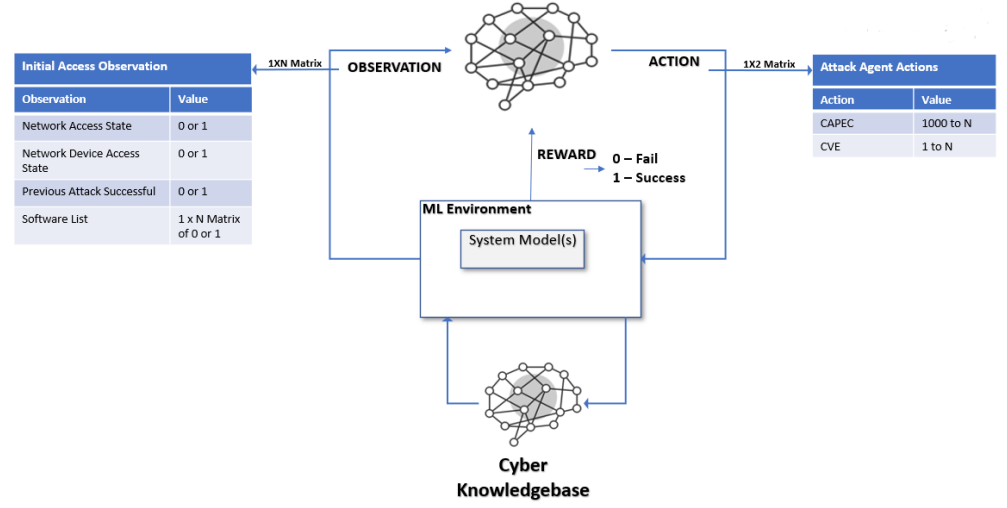
图2:RL环境。上图描述了智能体、环境和网络知识库之间互动的概况。
图2只代表一个智能体在环境中的行动。这个循环的目标是让攻击和防御智能体以模拟真实网络网络攻击和防御的方式相互响应。攻击智能体将攻击网络,在这个模拟中,它改变了环境。环境会通知防御智能体哪个节点受到攻击,从而导致防御智能体做出反应。例如,当攻击智能体试图访问网络时,它将在初始节点上使用默认账户。防御智能体将被通知,在被攻击的节点上,系统内存在异常,并使用他们的反应来尝试防御技术。防御智能体将不知道具体的攻击,但会通过本体中的推断路径知道该节点上存在哪些CWE,因此可以使用哪些攻击技术。如果防御智能体使用最佳防御技术,即账户锁定,将攻击智能体从网络中驱逐出去,它将获得成功。如果它选择不同的防御技术来应对,防御智能体将失败。当选择了最佳防御技术后,防御智能体会得到环境的奖励。这个奖励是该智能体的目标函数试图最大化的数字。通过这个循环的多次迭代,防御智能体根据环境给出的信息,探索每个可能的反应的效果。通过奖励防御智能体选择账户锁定作为对默认账户攻击技术的反应,这种行为得到了加强。智能体会明白,这种选择会增加它的奖励,并会学习适当的反应。环境和智能体之间的反馈回路在网络战争游戏模拟的横向移动和执行阶段的功能类似。通过这个反馈回路,防御智能体可以训练自己,以有效的方式应对网络攻击。
4 结果
该项目建立了一个通用RL网络智能体训练框架的概念验证。使用这个模块化的框架,一个防御性的RL智能体可以以一种具有成本效益的方式快速训练,以防御各种不同的网络。虽然目前的知识库中只有一小部分可能的攻击和防御技术,但这个框架可以在保持相同功能的情况下进行扩展。一旦防御智能体在每一种现有的攻击技术上都得到了训练,剩下的唯一威胁就是来自智能体和新开发的攻击技术偶尔出现的错误。然而,随着横向发展和知识库的扩大,这个训练框架可能会彻底改变网络安全领域。在其他类似的研究中,重点是训练一个防御智能体来防御一个特定的网络。然而,通过关注一个通用的训练方法,可以训练许多不同的防御智能体。因为这个项目的重点是开发一个最小可行的产品,在这个训练框架可行之前,还需要进行重大改进。
5 结论和未来工作
强化学习,经过进一步的发展,可以证明是网络战争游戏领域的一个宝贵工具。通过允许智能体根据他们与模拟环境的互动来学习和适应,它为模拟和分析复杂的安全场景提供了一个强大的框架。凭借其处理不确定性和从经验中学习的能力,强化学习非常适合于对网络威胁的动态和不断发展的性质进行建模。我们的研究结果表明,强化学习算法可以有效地学习抵御网络攻击,随着时间的推移,他们获得更多的经验而不断改进。随着网络安全领域的不断发展和演变,我们相信强化学习在帮助组织理解、预测和应对网络威胁方面将发挥越来越重要的作用。本项目中的一个主要限制是限制了攻击和防御智能体的选择。这样做是为了缩小问题的规模。这个项目的一个限制是防御剂。防御智能体的检测方面是随心所欲的,允许智能体自动检测攻击者,而不是为模拟创造一个检测智能体。这是由于这个项目所分配的时间,以及为了使模拟的重点在攻击智能体和防御智能体之间,而不是依靠偶尔可能没有检测到攻击者的检测智能体。另一个限制是原始项目的范围。在决定将防御作为论文的重点后,研究小组不得不根据原来的攻击智能体缩小项目范围。攻击技术是由团队收到项目时的原始攻击策略决定的。从那以后,就预先确定了这些技术将从哪些攻击战术中选择。未来可能的工作是在一个更复杂的环境中工作,因为它要求两个智能体在相互竞争之前学习网络。然后,攻击智能体可以学习通往决策节点的不同路线,而不是遵循代码操作员设定的预先确定的任务计划。这将导致两个智能体有更大的学习曲线,创造出更先进的智能体,能够在网络中旅行,并能够在不需要任务计划的情况下进行防御或攻击。



