Michael Janner,伯克利人工智能研究实验室的一名博士生,导师是Sergey Levine。我得到了公开慈善和国家科学基金会的资助。在伯克利之前,他是麻省理工学院的一名本科生,在那里我与Josh Tenenbaum、Regina Barzilay和Bill Freeman一起工作。

基于深度模型的强化学习方法为决策和控制问题提供了一种概念上简单的方法:利用学习来估计近似的动态模型,并将其余工作交给经典的轨迹优化。然而,这种组合在实践中存在许多实证上的缺陷,限制了基于模型方法的实用性。本论文的双重目的是研究这些缺陷的原因,并为所发现的问题提出解决方案。我们首先将动态模型进行泛化,用一个可以预测概率性潜在视野的模型替代标准的单步形式。通过时间差分学习的生成性重新解释训练出的结果模型,导致了模型基础控制的中心程序的无限视野版本,包括模型推演和基于模型的价值估计。 接下来,我们展示了常用的深度动态模型的预测准确性不佳是有效规划的主要瓶颈,并描述了如何使用高容量的序列模型来克服这个限制。将强化学习视为序列建模简化了一系列设计决策,使我们可以摒弃许多通常是强化学习算法的组成部分。然而,尽管这些序列模型的预测准确性很高,但它们受到其嵌入的搜索算法的限制。因此,我们展示了如何将整个轨迹优化管道折叠到生成模型本身中,使得从模型中采样和用它进行规划变得几乎一样。这项工作的高潮是一种方法,它通过更多的数据和经验提高其规划能力,而不仅仅是预测准确性。在此过程中,我们强调了如何将当代生成模型工具箱中的推理技术,包括束搜索、分类器引导的采样和图像修复,重新解释为强化学习问题的可行规划策略。


这篇论文研究了数据驱动决策和机器人控制问题中最简单的策略之一。这个抽象过程包括两个交错的步骤:1. 使用数据来拟合一个参数模型,该模型用于预测过去的未来。 2. 使用模型预测一组候选动作序列的结果,选择产生最理想结果的动作。这个高层次的描述概述了一种使用“现在的计划”(Kaelbling & Lozano-Pérez, 2011; van Hasselt et al., 2019)的模型预测控制算法,意味着模型被用来在做出决策时预测未来,而不是以其他方式使用模型生成的数据。这还留下许多需要明确的问题:如何选择用于评估的候选动作?模型应该如何构建?什么构成有用的数据? 尽管如此,这个规格已经足够暗示为什么这可能是一个好的方法。第一步相当于监督学习,现在只要有足够的数据和高容量的函数逼近器,如神经网络(Krizhevsky等人,2012;张等人,2017;Kaplan等人,2020),就经常可以可靠地工作。在控制环境中,第二步原则上可以卸载给轨迹优化算法,这些算法已经被大量研究,当已知地面真实动态时,在其原始环境中也同样被很好地理解(Diehl等人,2009;Tassa等人,2012;Kelly,2017)。看起来这种方法结合了两个相当可靠的拼图部分。
此外,模型学习和决策制定之间的分离具有一些吸引人的特性。最明显的是,它允许重复使用学习到的模型,使其可以在相同环境中部署到各种任务。与无模型方法相比,这种重复使用并不那么直接,因为奖励函数不能从学习到的策略或价值函数中编码的隐式动态知识中分离出来。这个属性还允许从没有明确标记奖励的数据中训练模型,这在奖励难以定义但经验丰富的情况下可能很有用。从实证上看,动态模型比价值函数更容易训练,允许学习模型更好的样本效率和泛化(Janner等人,2019);这可以被视为用于训练价值函数与动态模型的算法类型的差异(Kumar等人,2022)或者相对于最优价值函数的动态本身的简单性(Dong等人,2020)的结果。最后,这种分离提供了一种方便的方式来解释学习到的模型:对于规划程序产生的任何决定,人们可以检查导致选择那个决定的模型预期结果。
不幸的是,采用这种策略并不像看起来那么简单,也并非总是能将这些所谓的好处转化为实践。虽然已经有了成功的组合演示(Chua等人,2018;Argenson & Dulac-Arnold,2021),但令人惊讶的是,从这些成功中提取一套设计原则,使得这种方法可以有效地应用到新问题上,而无需进行大量的问题特定调优,是非常困难的。因此,深度模型基础强化学习的当代前沿主要由大量从无模型强化学习工具箱中提取的算法组成。相比之下,用深度神经网络进行现在的常规规划则很少见。这种情况应该让人感到惊讶。接下来章节的双重目的是解释为什么会这样,并提出一种前进的方法。在第2章对问题设置和技术背景的简要描述和回顾之后,我们将进行三个主要的思考:
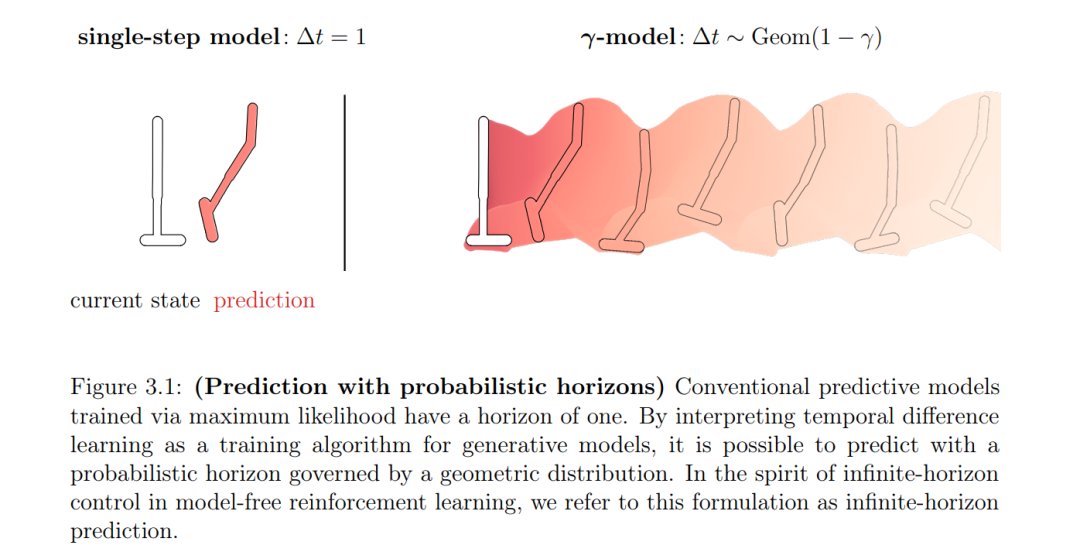
• 在第3章中,我们重新考虑了强化学习中状态空间预测的角色。结果是一个模型,它在训练时分摊预测的工作,就像一个价值函数一样,而不是依赖于基于模型的推演。因此,该模型可以在无限的概率视角下进行预测,而无需序列推演,模糊了基于模型和无模型机制之间的界线。这项调查强调了一个特别的缺点:表示未来轨迹的高维联合分布是一个困难的生成建模问题。
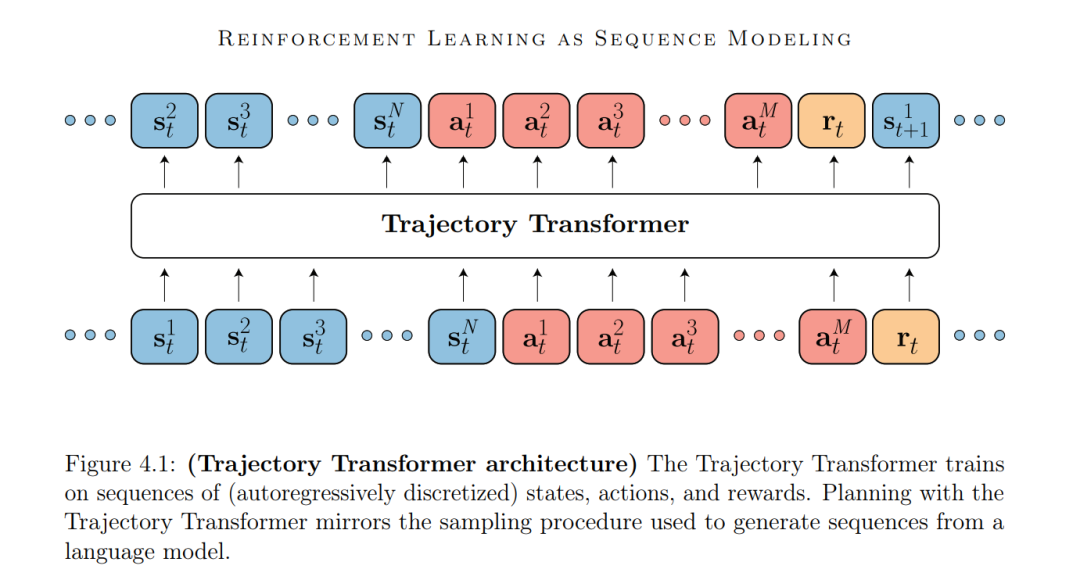
• 在第4章中,我们询问是否预测模型的质量是瓶颈。我们借鉴了生成建模的最近成功,并用长视角Transformer替换了传统的单步动态模型。在此过程中,我们展示了如何将序列建模工具箱中的算法重新解释为可行的规划算法。
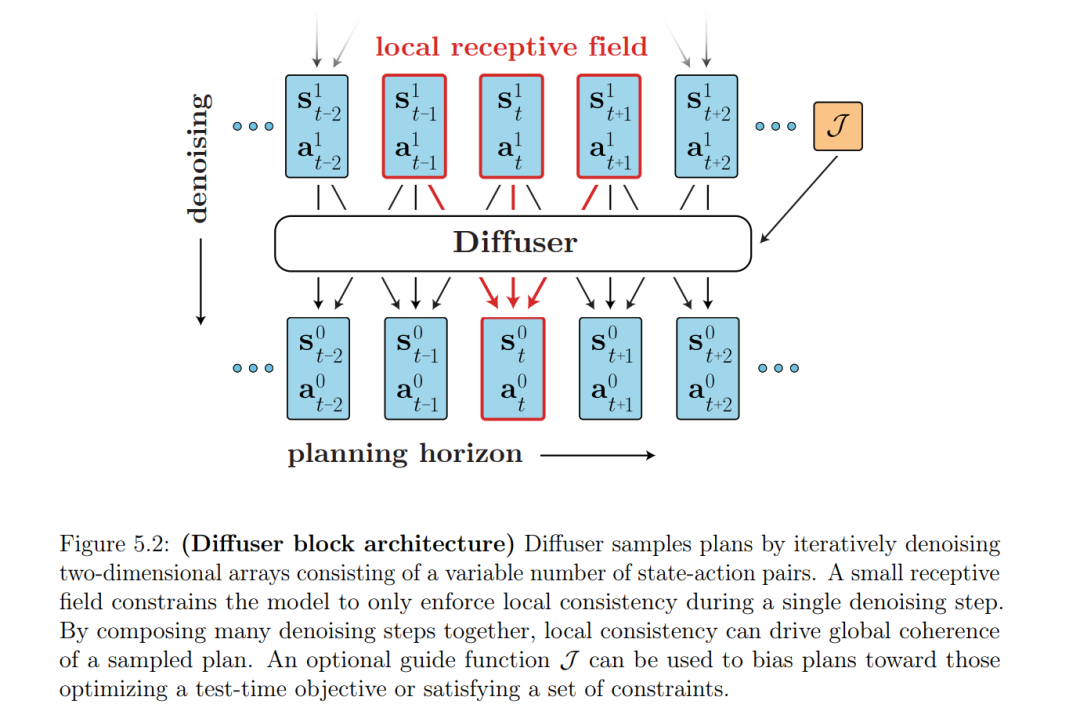
• Transformers在很大程度上解决了预测质量的瓶颈,但仍然受到它们所嵌入的规划程序的质量的限制。在第5章中,我们讨论了一种将预测和规划都整合到生成模型中的方法,使得从模型中抽样和用它进行规划之间的界线变得模糊。最终的结果是一种方法,它通过更多的数据和经验提高其规划能力,而不仅仅是预测的准确性。
我们在第6章中总结讨论了从这些调查中学到的教训及其对未来基于模型的强化学习算法的影响。