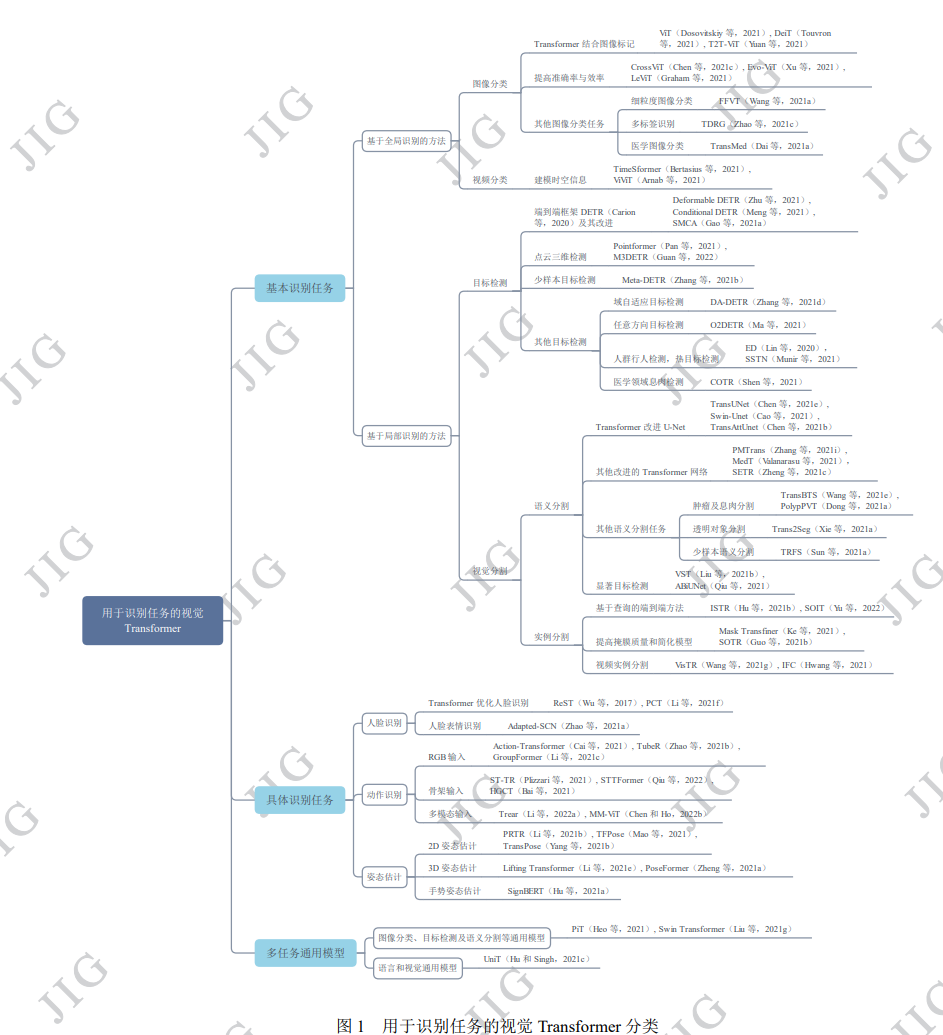
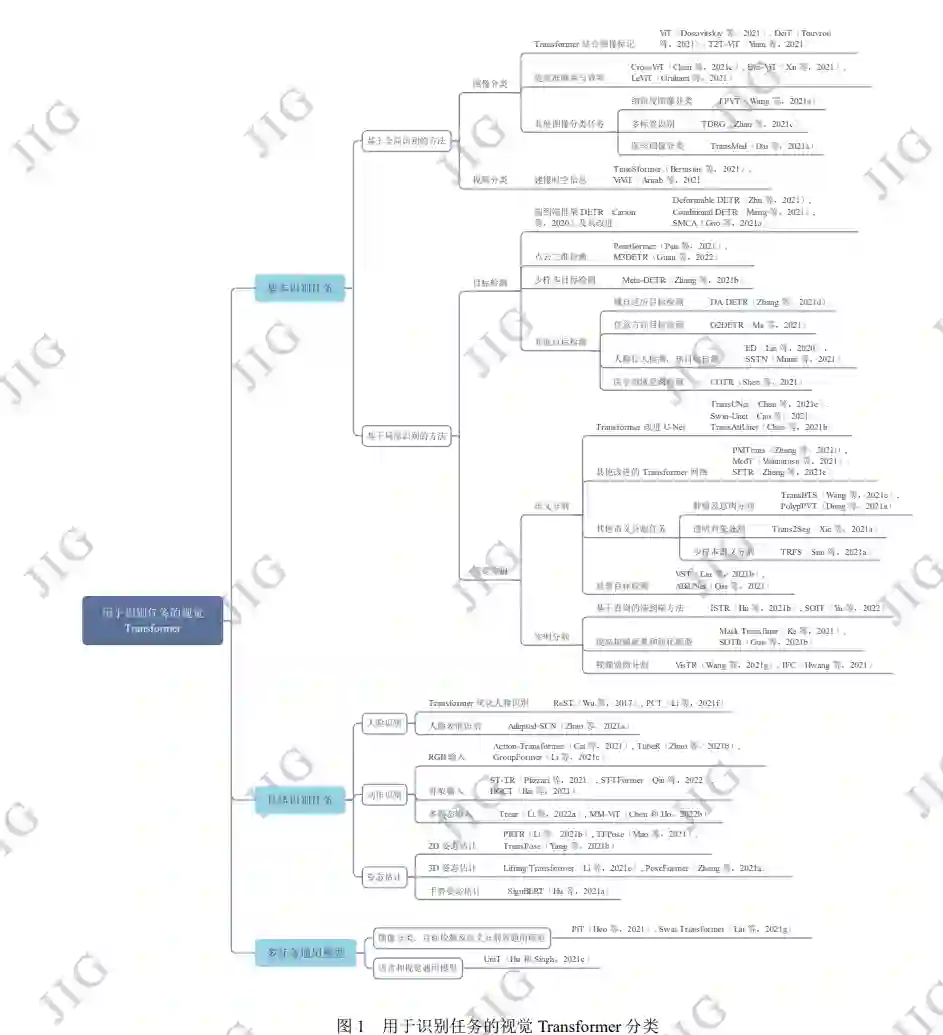
本文总结了视觉 Transformer 处理多种识别任务的百余种代表性方法,并对比分析了不同任务内的模型表 现,在此基础上总结了每类任务模型的优点、不足以及面临的挑战。本文根据识别粒度的不同,分别着眼于诸如图 像分类、视频分类的基于全局识别的方法,以及目标检测、视觉分割的基于局部识别的方法。考虑到现有方法在三 种具体识别任务的广泛流行,本文总结了在人脸识别、动作识别和姿态估计中的方法。同时,也总结了可用于多种 视觉任务或领域无关的通用方法的研究现状。基于 Transformer 的模型实现了许多端到端的方法,并不断追求准确率 与计算成本的平衡。全局识别任务下的 Transformer 模型对补丁序列切分和标记特征表示进行了探索,局部识别任务 下的 Transformer 模型因能够更好地捕获全局信息而取得了较好的表现。在人脸识别和动作识别方面,注意力机制减 少了特征表示的误差,可以处理丰富多样的特征。Transformer 可以解决姿态估计中特征错位的问题,有利于改善基 于回归的方法性能,还减少了三维估计时深度映射所产生的歧义。大量探索表明了视觉 Transformer 在识别任务中的 有效性,并且在特征表示或网络结构等方面的改进有利于提升性能。
http://www.cjig.cn/jig/ch/reader/view_abstract.aspx?edit_id=20230216101300001&flag=2&file_no=202208300000009&journal_id=jig 计算机视觉(Computer Vision, CV)涉及对图像 或视频中有用信息的提取和分析。在所有CV任务中, 识别任务占有很大的比重。随着深度学习技术的引 入,经典的方法是利用卷积神经网络(Convolutional Neural Network, CNN)来解决此类问题。CNN通过局 部感知和参数共享,降低了网络模型的复杂度,并 且可以直接将图像数据作为输入,避免了人工提取 特征的过程。但由于CNN擅长关注局部特征,难以 很好地利用对结果同样十分重要的全局信息,使得 该领域的发展受到了一定的阻碍。 Transformer(Vaswani 等,2017)是一个从序列 到序列(Sequence to Sequence)的模型,最大特点是 抛弃了传统的卷积神经网络和循环神经网络 (Recurrent Neural Network, RNN),采用注意力机制 组成网络,使得模型可以并行化训练,而且能够关 注全局信息。Transformer被提出后在自然语言处理 (Natural Language Processing, NLP)领域大放异彩,例如备受关注的基于Transformer的双向编码器表 示 (Bidirectional Encoder Representations from Transformers, BERT)模型(Devlin 等,2019),以及 生成式预训练Transformer(Generative Pre-Training, GPT) 系列模型 GPT1(Radford 和 Narasimhan , 2018),GPT2(Radford 等,2019),GPT3(Brown 等, 2020)。 这些基于Transformer的模型表现出的强大性 能使NLP研究取得了重大突破,同时吸引住了计算 机视觉研究人员的目光,他们将Transformer移植到 视觉任务中,并发现了其中的巨大潜力。 如首次使 用 纯 Transformer 进行图像识别的方法 Vision Transformer(ViT)(Dosovitskiy 等,2021),以及解决 目标检测问题的Detection Transformer(DETR)模型 (Carion 等,2020)。 随着越来越多的视觉Transformer模型被探索 出来,关于此研究的综述文章也逐渐出现。按照分 类标准的不同,目前的综述文章从不同的角度总结 现有的方法,包括输入数据(Han 等,2020)、网络 结构(Khan 等,2022)、应用场景(Liu 等,2021f, Liu 和 Lu,2021d,Khan 等,2022)。其中,从应 用场景角度进行总结的文章占大多数。Liu 等人 (2021f)分别从计算机视觉领域的三个基础任务(分 类、检测、分割)总结现有的方法。除了这三个基础 任务外,Liu 和 Lu(2021d),Khan 等人(2022)又增 加了在识别、视频处理、图像增强和生成应用场景 下的方法总结。然而,这些不同的应用都是孤立存 在的,不能形成一个系统的各种方法的总结。此外, 现有的综述文章多关注于视觉Transformer模型与 传统的CNN模型结果的比较,对不同Transformer模 型间结果的比较分析较少。 为了解决以上问题,本文从视觉识别的角度出 发,总结比较了视觉Transformer处理多种识别任务 的代表性方法。按照识别粒度的不同,可以分为基 于全局识别的方法和基于局部识别的方法。基于全 局识别的方法,即对视觉数据(图片、视频)整体进行 识别,例如图像分类、视频分类。基于局部识别的 方法,即对视觉数据中的部分进行识别,例如目标 检测等。考虑到现有方法在三种具体识别任务的广 泛流行,本文也总结对比了在人脸识别、动作识别 和姿态估计三种识别任务的方法。在每类任务下, 对不同方法的特点和在公共数据集上的表现进行 了对比分析,并进一步总结了该类方法的优点与不 足,以及不同识别任务面临的问题与挑战。 本文与现有的综述文章对比,具有以下优点: 1)本文从识别的角度分类,可以更系统地将现有方 法联系起来;2)虽然一些综述文章(Liu 和 Lu, 2021d,Khan 等,2022)也对识别任务的方法进行了 总结,但是涉及的内容不全面,而本文不但对基础 识别任务的方法进行了总结,还总结了三种具体识 别任务的方法,并且对于每类任务方法,在对比分 析公共数据集结果的基础上,总结了其发展现状和 不足。 综上所述,近年来 CNN 的局限性以及 Transformer研究的突破性使得视觉Transformer已广 泛应用于CV领域,而关于视觉Transformer的综述文 章还不够丰富,特别是对其应用场景的总结存在着 较为孤立的现象。又因流行的CV应用场景大多能够 以视觉识别的角度分析,所以本文系统地对用于识 别任务的视觉Transformer进行综述具有必要性,同 时,本文通过每类任务对应的基准数据集上的实验 对比分析,反映各类Transformer模型间的区别与联 系也是十分必要的。最后,本综述的出现带来了更 系统的总结和更全面的内容,将为相关领域读者快 速了解和认识Transformer在视觉识别任务中的应 用提供重要帮助。