

大型语言模型(LLM)面试问题汇总
Hao Hoang – LinkedIn: 获取更多AI见解!
2025年5月 通过本指南,深入探索大型语言模型(LLMs)的关键概念、技术和挑战,特别适合正在为面试做准备的AI爱好者和专业人士。 简介
大型语言模型(LLMs)正在彻底改变人工智能,使从聊天机器人到自动化内容创建等应用成为可能。本文档汇总了50个核心面试问题,经过精心筛选,旨在加深您对LLMs的理解。每个问题都配有详细答案,结合了技术见解与实际示例。请与您的网络分享这些知识,激发AI社区中的深度讨论! 1 问题1:什么是分词(tokenization),它为什么对LLM至关重要?
分词是将文本拆分成较小的单元或“词块”,例如单词、子单词或字符。例如,“artificial”可能会拆分为“art”,“ific”和“ial”。这一过程非常重要,因为LLMs处理的是词块的数值表示,而不是原始文本。分词使得模型能够处理多样的语言、管理罕见或未知的单词,并优化词汇表的大小,从而提高计算效率和模型性能。 2 问题2:注意力机制(attention mechanism)在Transformer模型中是如何工作的?
注意力机制使LLMs能够在生成或解释文本时,衡量序列中不同词块的重要性。它通过计算查询(query)、键(key)和值(value)向量之间的相似度分数,使用点积等运算,聚焦于相关的词块。例如,在句子“The cat chased the mouse”中,注意力机制帮助模型将“mouse”与“chased”联系起来。该机制提升了上下文理解,使得Transformer在NLP任务中表现优异。 3 问题3:LLM中的上下文窗口(context window)是什么,它为什么重要?
上下文窗口是指LLM一次性能够处理的词块数量,它定义了模型理解或生成文本时的“记忆”容量。一个更大的窗口,例如32,000个词块,可以让模型考虑更多的上下文,从而在任务如摘要生成中提高连贯性。然而,它也会增加计算成本。平衡窗口大小与效率对于实际部署LLM至关重要。 4 问题4:LoRA与QLoRA在微调LLM时有何区别?
LoRA(低秩适配)是一种微调方法,它通过在模型层中添加低秩矩阵,使得在内存开销最小的情况下高效地进行适应。QLoRA在此基础上应用了量化(例如,4位精度),进一步减少内存使用,同时保持精度。例如,QLoRA可以在单个GPU上对70B参数模型进行微调,适用于资源有限的环境。 5 问题5:与贪婪解码(greedy decoding)相比,束搜索(beam search)如何改善文本生成?
束搜索在文本生成过程中探索多个词序列,每个步骤保留前k个候选序列(束),与贪婪解码不同,后者只选择最可能的词。比如,当k=5时,束搜索通过平衡概率和多样性,确保输出更具连贯性,尤其适用于机器翻译或对话生成等任务。 6 问题6:温度(temperature)在控制LLM输出中起什么作用?
温度是一个超参数,用来调整文本生成中词块选择的随机性。低温(例如0.3)偏向选择高概率词块,产生可预测的输出。高温(例如1.5)通过平滑概率分布来增加多样性。在故事创作等任务中,设置温度为0.8通常能平衡创造性和连贯性。 7 问题7:什么是掩码语言建模(masked language modeling),它如何帮助预训练?
掩码语言建模(MLM)是指在序列中随机隐藏一些词块,并训练模型根据上下文预测这些词块。像BERT这样的模型使用MLM,它促进了对语言的双向理解,使模型能够掌握语义关系。这种预训练方法使LLM能够应对情感分析或问答等任务。 8 问题8:什么是序列到序列(Seq2Seq)模型,它们有哪些应用?
序列到序列(Seq2Seq)模型将输入序列转换为输出序列,输出序列的长度可能与输入不同。它们包括一个编码器来处理输入,一个解码器来生成输出。应用领域包括机器翻译(例如,将英文翻译为西班牙文)、文本摘要和聊天机器人等,常见于输入输出长度可变的情况。 9 问题9:自回归模型(autoregressive models)和掩码模型(masked models)在LLM训练中有何区别?
自回归模型,如GPT,基于先前的词块顺序预测词块,特别适用于生成任务,例如文本补全。掩码模型,如BERT,使用双向上下文预测掩码词块,更适合理解任务,如分类。它们的训练目标决定了它们在生成与理解任务中的优势。 10 问题10:什么是词嵌入(embeddings),它们在LLM中是如何初始化的?
词嵌入是将词块表示为密集的向量,这些向量在连续空间中捕捉语义和句法属性。它们通常是随机初始化的,或者使用像GloVe这样的预训练模型进行初始化,然后在训练过程中进行微调。例如,词嵌入“dog”可能会根据宠物相关任务的上下文进行调整,从而提高模型的准确性。 11 问题11:什么是下一句预测(next sentence prediction),它如何增强LLM的能力?
下一句预测(NSP)训练模型判断两句话是连续的还是无关的。在预训练过程中,像BERT这样的模型学习分类50%是正向(连续的)句子对,50%是负向(随机的)句子对。NSP帮助模型在对话系统或文档摘要等任务中理解句子之间的关系,提升连贯性。 12 问题12:top-k采样与top-p采样在文本生成中有何不同?
top-k采样从k个最可能的词块中随机选择(例如,k=20),确保控制多样性。top-p(核采样)选择那些累计概率超过阈值p(例如0.95)的词块,适应上下文。top-p提供了更大的灵活性,能够在创作写作中生成多样且连贯的输出。 13 问题13:为什么提示工程(prompt engineering)对LLM性能至关重要?
提示工程涉及设计输入,以引导LLM产生预期的输出。明确的提示,如“将这篇文章总结为100个字”,比模糊的指令更能提高输出的相关性。它在零-shot或少-shot场景中尤其有效,能够让LLM完成如翻译或分类等任务,而无需大量微调。 14 问题14:如何防止LLM在微调过程中发生灾难性遗忘(catastrophic forgetting)?
灾难性遗忘发生在微调时,模型丧失了先前的知识。缓解策略包括: * 复习:在训练过程中混合旧数据和新数据。 * 弹性权重整合:优先保留重要权重,以保持知识。 * 模块化架构:添加任务特定的模块,避免重写核心知识。
这些方法确保LLM在多个任务中保持多样性。 15 问题15:什么是模型蒸馏(model distillation),它如何惠及LLM?
模型蒸馏训练一个较小的“学生”模型模仿较大的“教师”模型的输出,使用软概率而非硬标签。这减少了内存和计算需求,使得模型能够在智能手机等设备上部署,同时保持接近教师模型的性能,非常适合实时应用。
16 问题16:LLM如何处理超出词汇表的词(OOV)?
LLMs使用子词分词技术,如字节对编码(Byte-Pair Encoding,BPE),将超出词汇表的词拆分成已知的子词单元。例如,“cryptocurrency”可能会拆分为“crypto”和“currency”。这种方法使LLM能够处理稀有或新词,确保语言理解和生成的健壮性。 17 问题17:Transformer如何改进传统的Seq2Seq模型?
Transformer通过以下方式克服了传统Seq2Seq模型的局限性: * 并行处理:自注意力机制使得模型能够同时处理所有的词块,而不像RNN那样顺序处理。 * 长距离依赖:注意力机制能够捕捉到较远词块之间的关系。 * 位置编码:确保序列中的顺序信息得到保留。
这些特性增强了模型在翻译等任务中的可扩展性和性能。 18 问题18:什么是过拟合(overfitting),如何在LLM中缓解?
过拟合发生在模型记住了训练数据的细节,从而无法有效地泛化。缓解过拟合的策略包括: * 正则化:L1/L2正则化使得模型更加简洁。 * 丢弃法(Dropout):在训练过程中随机禁用神经元。 * 提前停止:当验证集的性能趋于平稳时,停止训练。
这些技术确保了模型能够有效地对未见过的数据进行泛化。 19 问题19:生成模型(generative models)和判别模型(discriminative models)在NLP中的区别是什么?
生成模型,如GPT,建模联合概率来创建新数据,例如文本或图像。判别模型,如BERT,用来建模条件概率,区分不同类别,如情感分析。生成模型擅长创作,而判别模型则专注于准确分类。 20 问题20:GPT-4与GPT-3在特性和应用上有何不同?
GPT-4相较于GPT-3具有以下改进: * 多模态输入:能够处理文本和图像。 * 更大的上下文窗口:支持最多25,000个词块,而GPT-3只能处理4,096个词块。 * 更高的准确性:通过更好的微调减少事实错误。
这些改进使得GPT-4在视觉问答和复杂对话等任务中有更广泛的应用。 21 问题21:什么是位置编码(positional encoding),它为什么要使用?
位置编码为Transformer输入增加了序列的顺序信息,因为自注意力机制本身不具备顺序感知能力。通过使用正弦函数或学习到的向量,位置编码确保像“king”和“crown”这样的词能根据其在句中的位置正确地进行解释,对于翻译等任务至关重要。 22 问题22:什么是多头注意力(multi-head attention),它如何增强LLM的能力?
多头注意力将查询(query)、键(key)和值(value)分成多个子空间,允许模型同时关注输入的不同方面。例如,在一个句子中,一个头可能关注语法,另一个头则关注语义。这提高了模型捕捉复杂模式的能力。 23 问题23:softmax函数在注意力机制中如何应用?
softmax函数将注意力分数转化为概率分布:
在注意力机制中,它将查询-键点积得到的相似度分数转化为权重,从而强调与上下文相关的词块。这确保了模型能够关注输入中最重要的部分。 24 问题24:点积(dot product)如何在自注意力中发挥作用?
在自注意力机制中,查询(Q)与键(K)向量之间的点积计算相似度分数:
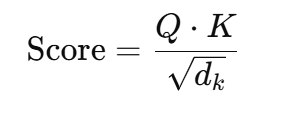
高分表示相关的词块。虽然这种计算方式高效,但由于它的二次复杂度(O(n²)),对于长序列的处理存在挑战,因此目前已经有研究提出稀疏注意力的替代方法。 25 问题25:为什么在语言建模中使用交叉熵损失(cross-entropy loss)?
交叉熵损失衡量预测值与真实标签之间的差异:
它惩罚错误的预测,鼓励模型选择正确的下一个词块。在语言建模中,交叉熵损失确保模型将高概率分配给正确的词块,从而优化性能。
26 问题26:LLM中嵌入(embeddings)的梯度是如何计算的?
在LLM中,嵌入的梯度是通过反向传播中的链式法则计算的:
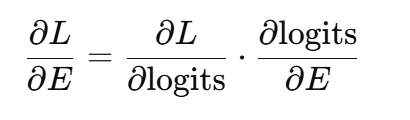
这些梯度调整嵌入向量,以最小化损失,从而优化其语义表示,提高任务表现。 27 问题27:雅可比矩阵(Jacobian matrix)在Transformer反向传播中的作用是什么?
雅可比矩阵捕获输出相对于输入的偏导数。在Transformer中,它有助于计算多维输出的梯度,确保在反向传播过程中,权重和嵌入的更新是准确的,这对优化复杂模型至关重要。 28 问题28:特征值(eigenvalues)和特征向量(eigenvectors)与降维(dimensionality reduction)有何关系?
特征向量定义了数据中的主方向,特征值表示这些方向的方差。在像主成分分析(PCA)这样的技术中,通过选择具有高特征值的特征向量来降低维度,同时保留大部分方差,从而提高LLM输入处理的效率。 29 问题29:KL散度(KL divergence)是什么,它在LLM中如何应用?
KL散度量化了两个概率分布之间的差异:
在LLM中,KL散度用来评估模型预测与真实分布的匹配程度,指导微调过程以提高输出质量和与目标数据的一致性。 30 问题30:ReLU函数的导数是什么,它为何重要?
ReLU函数的定义是 f(x)=max(0,x)f(x) = \max(0, x)f(x)=max(0,x),其导数为:

ReLU函数的稀疏性和非线性防止了梯度消失问题,使得它在LLM训练中计算高效,广泛用于深度学习模型中。 31 问题31:链式法则(chain rule)如何应用于LLM中的梯度下降?
链式法则用于计算复合函数的导数:
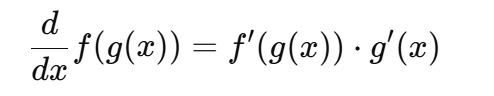
在梯度下降中,链式法则使得反向传播能够逐层计算梯度,从而高效地更新参数,最小化深度LLM架构中的损失。 32 问题32:Transformer中如何计算注意力分数?
注意力分数计算公式为:
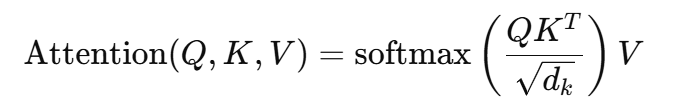
缩放点积计算词块的相关性,softmax函数对分数进行归一化,以集中注意力在关键词块上,这增强了在任务如摘要生成中的上下文感知能力。 33 问题33:Gemini如何优化多模态LLM训练?
Gemini通过以下方式提高效率: * 统一架构:结合文本和图像处理,提高参数效率。 * 先进的注意力机制:改善跨模态学习的稳定性。 * 数据效率:使用自监督技术减少标注数据的需求。
这些特点使得Gemini比像GPT-4这样的模型更稳定、更具可扩展性。 34 问题34:有哪些基础模型(foundation models)?
基础模型包括: * 语言模型:如BERT、GPT-4,用于文本任务。 * 视觉模型:如ResNet,用于图像分类。 * 生成模型:如DALL-E,用于内容创作。 * 多模态模型:如CLIP,用于文本-图像任务。
这些模型利用广泛的预训练,能够应用于各种任务。 35 问题35:PEFT如何缓解灾难性遗忘?
参数高效微调(PEFT)只更新一小部分参数,保持其余部分不变,以保持预训练知识。像LoRA这样的技术确保LLM能够适应新任务,同时不会丧失核心能力,维持在多个领域的表现。 36 问题36:检索增强生成(RAG)有哪些步骤?
RAG的步骤包括: 1. 检索:使用查询嵌入检索相关文档。 1. 排序:按相关性排序文档。 1. 生成:使用检索到的上下文生成准确的响应。
RAG在问答等任务中通过增强事实准确性来提升模型性能。 37 问题37:专家混合(MoE)如何增强LLM的可扩展性?
MoE使用门控函数来根据输入激活特定的专家子网络,从而减少计算负担。例如,模型的参数中只有10%在每次查询中被激活,这使得大规模参数模型能够高效运行,同时保持高性能。 38 问题38:什么是链式思维(CoT)提示,它如何帮助推理?
链式思维提示引导LLM逐步解决问题,模仿人类的推理过程。例如,在数学问题中,它将计算步骤分解成逻辑步骤,从而提高准确性和可解释性,特别适用于逻辑推理或多步骤查询等复杂任务。 39 问题39:判别AI与生成AI有何不同?
判别AI(如情感分类器)根据输入特征预测标签,建模条件概率。生成AI(如GPT)通过建模联合概率来创造新数据,适用于文本或图像生成任务,提供更大的创作灵活性。 40 问题40:知识图谱的集成如何改善LLM?
知识图谱提供结构化的事实数据,通过以下方式增强LLM: * 减少幻觉:通过验证图谱中的事实来减少模型错误。 * 改善推理:利用实体之间的关系进行推理。 * 增强上下文:提供结构化的上下文,使得模型能够生成更好的响应。
这对于问答和实体识别任务非常有价值。 41 问题41:什么是零-shot学习,LLM如何实现零-shot学习?
零-shot学习允许LLM在没有针对特定任务的数据的情况下,利用预训练知识执行任务。例如,提示“将此评论分类为正面或负面”,LLM能够推测情感而无需特定的训练数据,展示了其多样性。 42 问题42:自适应Softmax如何优化LLM?
自适应Softmax将词汇按频率分组,减少对稀有词的计算负担。这降低了处理大词汇表的成本,加速了训练和推理,同时保持了准确性,尤其适用于资源有限的环境。 43 问题43:Transformer如何解决梯度消失问题?
Transformer通过以下方式减轻梯度消失问题: * 自注意力:避免了顺序依赖。 * 残差连接:允许梯度直接流动。 * 层归一化:稳定了更新过程。
这些特性确保了深层模型的有效训练,而不像RNN那样受到限制。 44 问题44:什么是少-shot学习,少-shot学习的优势是什么?
少-shot学习使LLM能够在仅有少量示例的情况下执行任务,利用预训练知识。其优势包括减少数据需求、加速适应以及提高成本效益,特别适用于诸如专门文本分类等细分任务。 45 问题45:如何修复LLM生成偏见或错误输出的问题?
解决偏见或错误输出的步骤包括: 1. 分析模式:识别数据或提示中的偏见源。 1. 增强数据:使用平衡的数据集和去偏技术。 1. 微调:使用精选数据或对抗方法重新训练模型。
这些步骤能够提高模型的公正性和准确性。 46 问题46:在Transformer中,编码器(encoder)和解码器(decoder)有何不同?
编码器将输入序列转换为抽象的表示,捕获上下文信息。解码器生成输出,利用编码器的输出和先前的词块。在翻译中,编码器理解源语言,解码器生成目标语言,使得Seq2Seq任务能够有效完成。 47 问题47:LLM与传统的统计语言模型有何不同?
LLM使用Transformer架构、大规模数据集和无监督预训练,而传统的统计模型(如N-gram)依赖于更简单的监督方法。LLM能够处理长距离依赖、上下文嵌入以及多样化任务,但需要大量计算资源。 48 问题48:什么是超参数(hyperparameter),它为什么重要?
超参数是预设的值,例如学习率或批量大小,用于控制模型的训练过程。它们影响收敛速度和性能;例如,较高的学习率可能导致不稳定。调优超参数能够优化LLM的效率和准确性。 49 问题49:什么定义了大型语言模型(LLM)?
LLM是经过大规模文本语料库训练的AI系统,能够理解和生成类人语言。它们具有数十亿个参数,能够在翻译、摘要生成和问答等任务中表现出色,依靠上下文学习具备广泛的适用性。 50 问题50:LLM在部署过程中面临哪些挑战?
LLM面临的挑战包括: * 资源密集型:计算需求高。 * 偏见:可能会固化训练数据中的偏见。 * 可解释性:复杂模型难以解释。 * 隐私:可能存在数据安全问题。
解决这些问题能确保LLM的道德和有效使用。
