

组合图像检索(Composed Image Retrieval,CIR)旨在基于参考图像与描述期望修改的文本,检索出相关的目标图像。然而,现有的CIR方法通常仅关注检索目标图像,而忽视了其他图像的相关性。这一局限主要源于多数方法采用对比学习范式,即将目标图像视为正样本,而将批中的所有其他图像一概视为负样本,进而可能引入“伪负样本”(false negatives)。这会导致系统检索出不相关图像,即使目标图像被成功检索,也可能降低用户满意度。
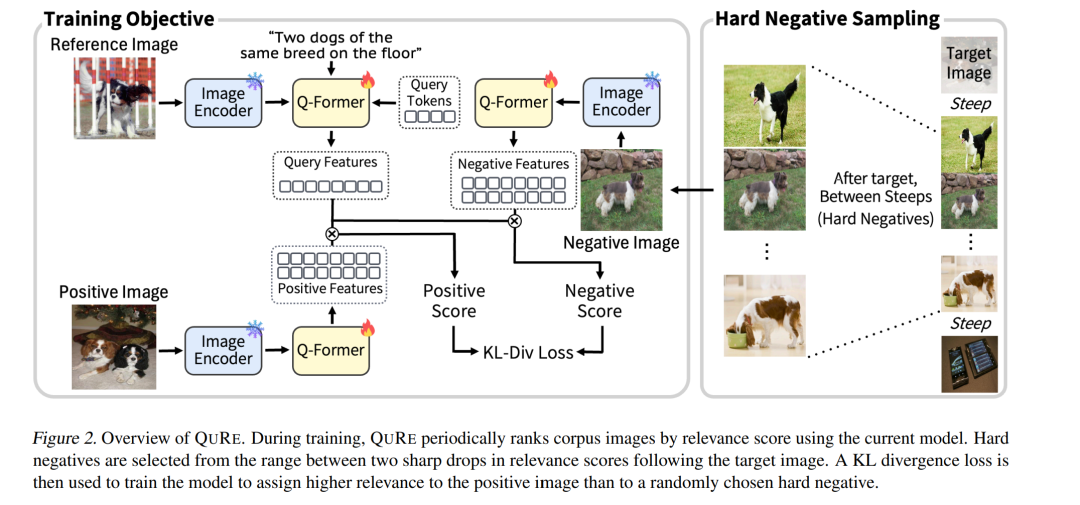
为了解决上述问题,我们提出了一种名为 QURE(Query-Relevant Retrieval through Hard Negative Sampling) 的方法,旨在通过优化奖励模型目标函数来减少伪负样本的干扰。此外,我们设计了一种困难负样本采样策略:该策略选择在目标图像之后、相关性分数出现两次急剧下降之间的图像,作为潜在的困难负样本,从而更有效地过滤伪负样本。
为了评估CIR模型在与用户满意度对齐方面的表现,我们还构建了一个新数据集 —— Human-Preference FashionIQ(HP-FashionIQ),该数据集显式地捕捉了超越目标检索本身的用户偏好信息。大量实验表明,QURE在FashionIQ和CIRR数据集上达到了当前最先进的性能,并且在HP-FashionIQ数据集上展现出与人类偏好最强的一致性。 源代码可在以下地址获取: https://github.com/jackwaky/QuRe
成为VIP会员查看完整内容

相关内容
相关VIP内容
相关资讯
相关论文