

大型语言模型(LLMs)在理解和生成接近人类交流的文本方面展现出了非凡的能力。然而,它们的一个主要局限性在于训练过程中显著的计算需求,这源于它们广泛的参数化。这一挑战进一步被世界的动态性所加剧,需要频繁更新LLMs以纠正过时的信息或整合新知识,从而确保它们的持续相关性。值得注意的是,许多应用要求在训练后持续调整模型以解决缺陷或不良行为。对于即时模型修改的高效轻量级方法,人们越来越感兴趣。为此,近年来知识编辑技术在LLMs领域蓬勃发展,旨在有效地修改LLMs在特定领域内的行为,同时保持对各种输入的整体性能。在本文中,我们首先定义了知识编辑问题,然后提供了对前沿方法的全面调研。从教育和认知研究理论[1-3]中汲取灵感,我们提出了一个统一的分类标准,将知识编辑方法分为三组:依赖外部知识、将知识融入模型和编辑内在知识。此外,我们引入了一个新的基准测试,KnowEdit,用于对代表性知识编辑方法进行全面的实证评估。另外,我们提供了对知识位置的深入分析,这可以提供对LLMs内在知识结构的更深层次理解。最初作为高效引导LLMs的手段构想,我们希望从知识编辑研究中获得的洞见能够阐明LLMs的底层知识机制。为了促进未来的研究,我们发布了一个开源框架,EasyEdit1,将使从业者能够高效灵活地实施LLMs的知识编辑。最后,我们讨论了知识编辑的几个潜在应用,并概述了其广泛而深远的影响。
知识是人类智能和文明的基本组成部分[4]。其系统结构赋予了我们通过符号手段来表示有形实体或勾画原则,从而提供了促进复杂行为或任务表达的能力[5-7]。在我们的生活中,我们人类不断积累了丰富的知识财富,并学会在不同背景下灵活应用它。对知识的性质以及我们获取、保留和解释它的过程的持续探索,一直吸引着科学家们,这不仅是一项技术追求,还是通向反映人类认知、交流和智能复杂性的旅程[8-12]。 近年来,大型语言模型(LLM)如GPT-4[13]在自然语言处理(NLP)方面展现出了卓越的能力,可以保留大量知识,可能超过了人类能力[14-30]。这一成就可以归因于LLMs处理和压缩大量数据的方式[31-34],潜在地形成了更简洁、连贯和可解释的底层生成过程模型,实质上创建了一种“世界模型”[35-37]。例如,戴等人[38]提出了知识神经元(KN)论,提出语言模型的功能类似于键值记忆。在这里,核心区域的多层感知器(MLP)权重[39]可能在从训练语料库中提取事实方面起到关键作用,暗示了LLMs内部知识存储的更结构化和可检索形式[40, 41]。
更深入的洞察来自LLMs理解和操作复杂战略环境的能力,李等人[42]已经证明,针对象棋等棋盘游戏进行下一个标记预测的Transformer模型发展出了游戏状态的明确表示。帕特尔和帕夫利克[43]揭示了LLMs可以跟踪给定上下文中的主题的布尔状态,并学习反映感知、符号概念的表示[35, 44-46]。这种双重能力表明LLMs可以充当广泛的知识库[47-58],不仅存储大量信息,还以可能反映人类认知过程的方式进行结构化。 然而,LLMs存在一些限制,如事实错误、可能生成有害内容和由于训练截止日期而过时的知识[59-61]。为了解决这个问题,近年来见证了为LLMs专门定制的知识编辑技术的发展潮,这些技术允许对模型进行经济有效的事后修改[67-69]。这项技术侧重于特定领域的调整,而不会影响整体性能,并有助于了解LLMs如何表示和处理信息,这对于确保人工智能(AI)应用的公平性和安全性至关重要[70-74]。
本文首次尝试全面研究LLMs的知识编辑发展和最新进展。我们首先介绍了Transformer的架构、LLMs中的知识存储机制(§2.1)以及相关技术,包括参数有效微调、知识增强、继续学习和机器遗忘(§2.2)。然后,我们介绍了初步内容(§3.1),正式描述了知识编辑问题(§3.2),并提出了一个新的分类法(§3.3),以基于教育和认知研究理论[1-3]提供关于知识编辑方法的统一视角。具体而言,我们将LLMs的知识编辑分类为:使用外部知识(§3.3.1)、将知识融入模型(§3.3.2)和编辑内在知识(§3.3.3)的方法。我们的分类标准总结如下:
• 使用外部知识。这种方法类似于人类认知过程中的识别阶段,需要在相关上下文中暴露给新知识,就像人们首次接触新信息一样。例如,提供说明模型的事实更新的句子,以进行知识的初始识别。
• 将知识融入模型。这种方法密切类似于人类认知过程中的关联阶段,在其中形成了新知识与模型中现有知识之间的联系。方法将输出或中间输出与学到的知识表示组合或替代。
•** 编辑内在知识**。这种知识编辑方法类似于人类认知过程中的掌握阶段。它涉及将知识完全整合到其参数中,通过修改LLMs的权重并可靠地利用它们。
这篇论文随后进行了广泛而全面的实验,涉及了12个自然语言处理(NLP)数据集。这些数据集经过精心设计,用于评估性能(§4)、可用性和底层机制,同时进行了深入的分析(§5),等等其他方面。我们研究的关键见解总结如下:
• 性能。我们构建了一个名为KnowEdit的新基准,并报告了针对LLMs的最新知识编辑方法的实证结果,提供了公平比较,展示了它们在知识插入、修改和删除设置中的整体性能。 • 可用性。我们阐述了知识编辑对一般任务和多任务知识编辑的影响,这意味着当代知识编辑方法在执行事实更新时对模型的认知能力和在不同知识领域之间的适应性几乎没有干扰。 •** 机制**。我们观察到在编辑后的LLMs中,存在一个或多个列的明显关注点在值层中。此外,我们发现知识定位过程(例如,因果分析)倾向于仅针对与所讨论实体相关的区域,而不是整个事实背景,这表明LLMs可能是通过回忆从预训练语料库中记忆的信息或通过多步推理过程来得出答案。此外,我们深入探讨了知识编辑对LLMs可能导致意外后果的可能性,这是一个需要仔细考虑的方面。
最后,我们深入探讨了知识编辑的多方面应用,从各种角度(§6)考察其潜力,包括高效的机器学习、人工智能生成内容(AIGC)、可信人工智能和人机交互(个性化代理)。此外,我们的讨论还涵盖了知识编辑技术的更广泛影响,特别关注能源消耗和可解释性等方面(§7)。这篇论文旨在成为LLMs领域进一步研究的催化剂,强调效率和创新。为了支持和鼓励未来的研究,我们将使我们的工具、代码、数据拆分和训练模型检查点公开可访问。
大模型知识编辑
知识编辑对LLMs的初步内容 通过对各种数据集的大量训练,LLMs积累了丰富的事实和常识信息,使这些模型成为虚拟知识存储库[47, 141]。这个丰富的知识库已经在各种下游任务中得到有效利用,如许多研究所证明的那样[142]。此外,王等人[143]已经展示了LLMs在自主构建高质量知识图的潜力,无需人类监督。尽管LLMs在其当前状态下作为新兴知识库表现出了潜力,但它们也存在一定的局限性。这些不足在实际应用中常表现为输出的不准确或错误。理想的知识库不仅应存储大量信息,还应允许进行高效和有针对性的更新,以纠正这些错误并提高其准确性。认识到这一差距,我们的论文引入了知识编辑的概念,旨在实现对LLMs的快速和精确修改,使它们能够生成更准确和相关的输出。通过实施对LLMs的知识编辑,我们旨在提高LLMs的效用,使它们更接近成为普遍可靠和适应性强的知识存储库的理想目标。这一进展有望解决LLMs目前的缺陷,并释放它们作为动态和准确知识库的全部潜力,以供应用使用。
知识编辑的最初目标是修改LLM中的特定知识k,以提高LLM的一致性和性能,而不需要对整个模型进行精细调整。这种知识可以涉及许多领域和类型,例如事实[77]、常识[144]、情感[145]等等。知识编辑具有挑战性,因为LLMs中的知识具有分布和纠缠的特性。
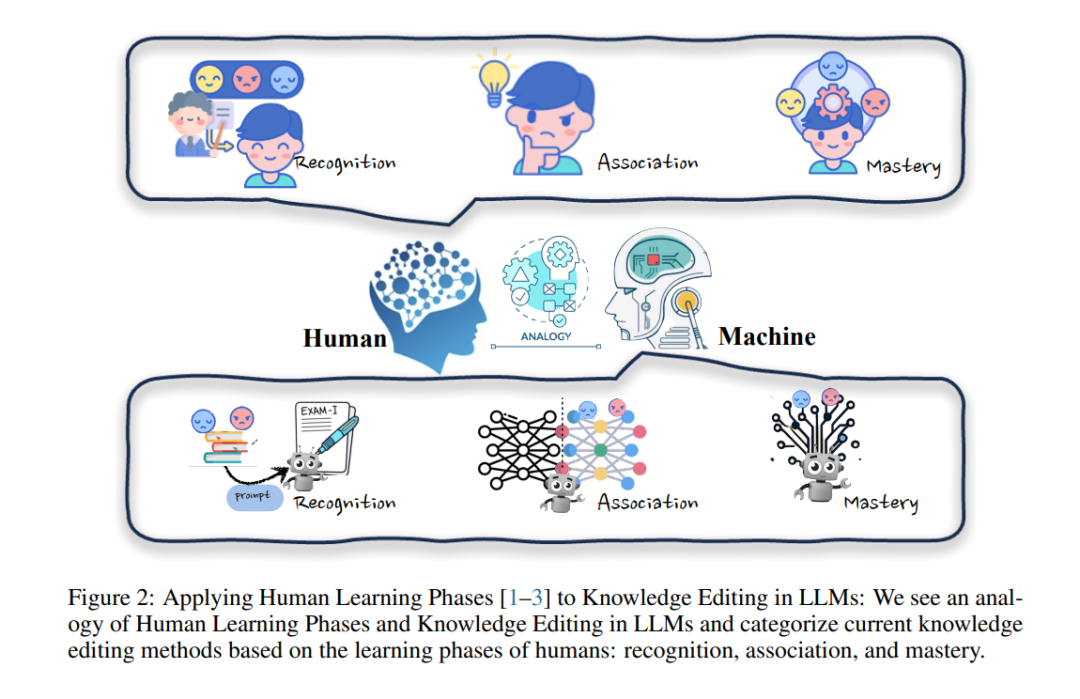
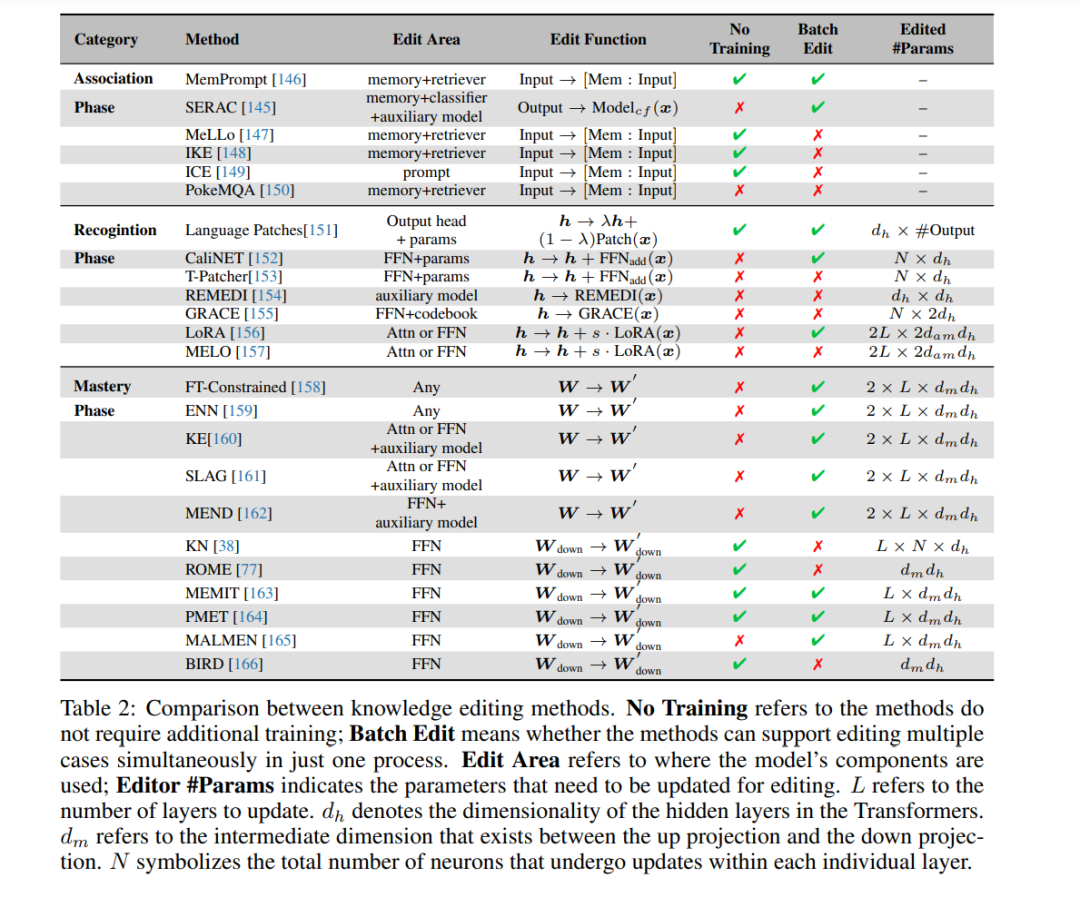
LLMs的发展已经达到了一个阶段,其能力与人类的认知过程非常相似,特别是在学习和获取知识方面。从人类学习过程中汲取灵感,我们可以类比地将这些概念应用到LLMs的编辑过程中,正如图2所示。教育和认知研究[1-3]将人类的知识获取划分为三个明确的阶段:识别、关联和掌握。这些阶段为概念化LLMs中的知识编辑方法提供了一个框架,我们在表2中列出了它们。
• 识别阶段:在识别阶段,模型需要在相关背景下接触新知识,就像人们首次遇到新信息一样(§3.3.1)。例如,提供描述事实更新的句子作为模型演示可以初步识别需要编辑的知识。
• 关联阶段:在关联阶段,新知识与模型中现有知识之间建立联系(§3.3.2),类似于人类将新思想与先前概念相关联。方法会将输出或中间输出h与已学知识表示hknow结合或替代。
• 掌握阶段:掌握阶段涉及模型完全掌握其参数中的知识并可靠利用它(§3.3.3),类似于人类的深层掌握。这种方法直接改变了模型的权重∆W,模型可以处理问题,无需任何外部帮助或合并。
实验结果
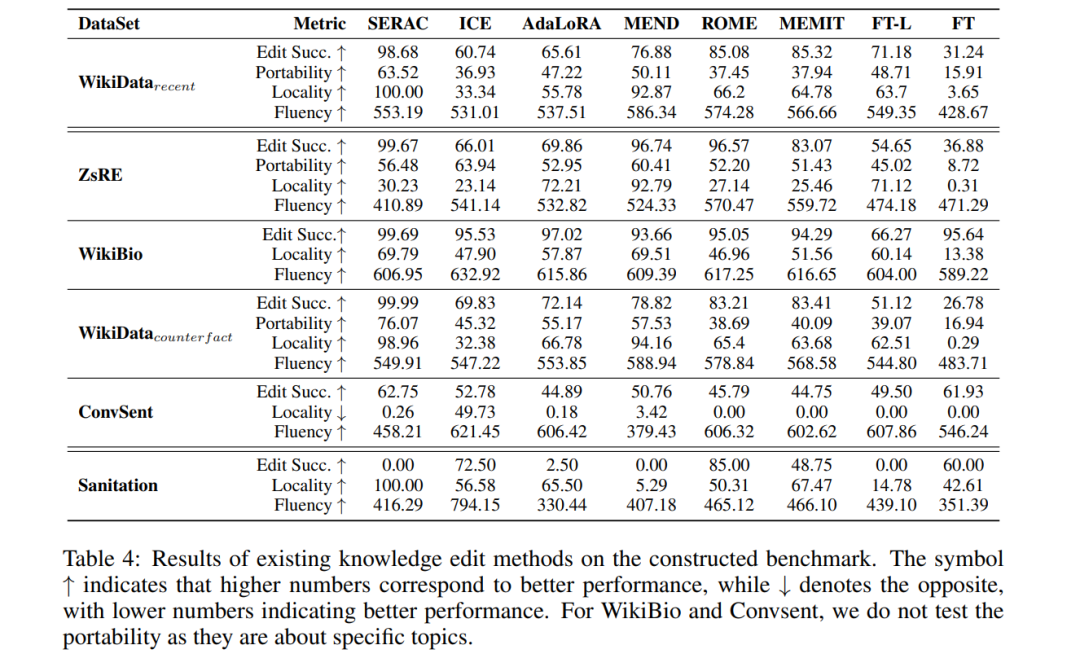
主要来说,SERAC在知识插入和修改任务中表现良好。它的编辑成功率优于其他编辑方法,且可移植性相对较好,因为新的反事实模型可以有效地学习编辑后的知识。与此同时,在不改变原始模型参数的情况下,SERAC除了ZsRE之外,在局部性能方面表现良好。然而,由于反事实模型通常比原始模型小,其生成能力不是很强,在WikiDatacounterfact、ZsRE和Convsent等任务中,我们可以发现SERAC的流畅性较其他编辑方法如MEND更低。与此同时,在ICE任务中,我们可以发现编辑成功率并不太好,这可能归因于知识冲突问题。同时,IKE提出将演示文稿连接在一起作为提示,但它们需要较长的输入长度,并限制了模型进行下游任务。 对于修改模型参数的方法,我们可以发现MEND在不同指标下在这些任务中表现良好。它的编辑成功率和可移植性良好,表现出良好的局部性和流畅性。然而,对于ROME和MEMIT,尽管编辑成功率更好,但它们的局部性不如MEND和其他类型的编辑方法。同时,它的可移植性令人不满。对于局部微调方法FT-L,其编辑成功率不如ROME或MEMIT,但局部性和可移植性更好。此外,似乎FT-L在处理插入任务时更好,因为其在WikiDatarecent任务中的编辑成功率和可移植性优于ZsRE和WikiDatacounterfact。对于WikiBio任务,当前方法可以适当减轻幻觉并保持良好的流畅性。至于Convsent任务,我们可以发现当前方法不能很好地改变模型的情感,因为编辑成功率低于65%。SERAC,它可以完美地处理小型LMs [145],在7B模型上表现不佳。考虑到其在其他任务中在事实级别编辑方面的出色表现,MEND对这些任务的流畅性也较低。至于知识删除任务Sanitation,旨在从LLMs中删除知识,我们可以发现当前的知识编辑方法不能适当地处理这项任务。我们可以发现ROME可以避免模型提供目标知识,因为它的准确率达到了90%。但是,它会破坏模型对无关知识的性能,因为其局部性仅为55.61%。其他编辑方法也不能删除与给定知识相关的模型。
我们还展示了在WikiDatarecent和WikiDatacounterfact的子指标中的平均性能结果,如我们在图3中的先前评估部分中讨论的那样。在这里,我们可以发现MEND在推理集下表现更好,而AdaLoRA表现出良好的逻辑概括性能。
