将自然语言(NL)问题转换为SQL查询,称为文本到SQL(Text-to-SQL),已成为促进关系型数据库访问的关键技术,尤其对于没有SQL知识的用户。大型语言模型(LLMs)在自然语言处理(NLP)领域的最新进展,显著推动了文本到SQL系统的发展,开辟了提升此类系统的新途径。本研究系统地回顾了基于LLM的文本到SQL,重点讨论四个关键方面:(1)对基于LLM的文本到SQL研究趋势的分析;(2)从多角度对现有的基于LLM的文本到SQL技术进行深入分析;(3)总结现有的文本到SQL数据集和评估指标;(4)讨论这一领域潜在的障碍和未来探索的方向。本综述旨在为研究人员提供对基于LLM的文本到SQL的深入理解,激发该领域的新创新和进展。 CCS概念:• 计算方法 → 自然语言处理;• 信息系统 → 结构化查询语言(SQL)。 附加关键词:文本到SQL、大型语言模型(LLMs)。
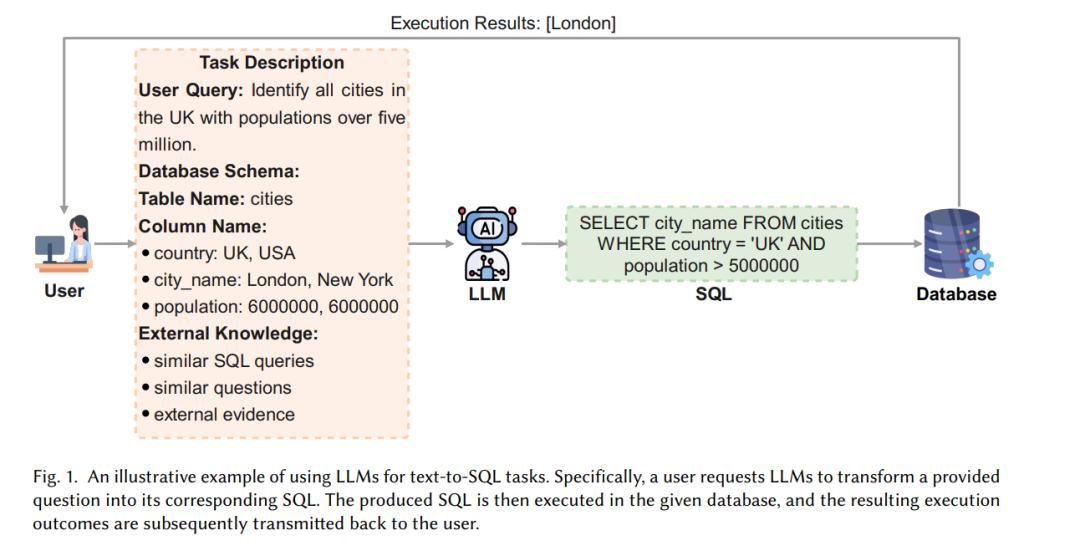
引言 SQL查询的利用显著提高了从多个数据库中提取数据的效率。这些数据已被有效应用于多个重要领域,如商业智能 [80] 和医疗分析 [78]。虽然技术专业人员擅长处理SQL查询,但数据库的自然语言接口(NLIDB)使得非技术用户也能够无缝地从结构化数据库中提取信息 [20]。这种便捷性显著推动了文本到SQL系统的发展,这些系统能够自动将自然语言(NL)查询转换为有效的SQL查询。为了说明这一点,我们考虑一个简单的数据库,如图1所示,包含一个名为“cities”的表格,表中有“country”、“city_name”和“population”三列。通过使用文本到SQL系统,用户输入类似“Identify all cities in the UK with populations over five million”的查询,将其转换为以下SQL查询:“SELECT city_name FROM cities WHERE country = ‘UK’ AND population > 5000000”。生成的SQL查询随后在给定数据库中执行,返回的结果(如“[London]”)将反馈给用户。整个过程简化了不熟悉SQL的用户对信息的访问。
近年来,自然语言处理(NLP)领域出现了重大突破,随着大型语言模型(LLMs)的出现 [1, 38],这些模型具有前所未有的处理和生成类人语境的能力,受到了广泛关注 [12, 145]。随着LLM的不断发展,新的能力开始显现,例如零-shot学习 [132]、few-shot学习 [108] 和指令跟随 [136]。鉴于这些能力,基于LLM的文本到SQL方法逐渐崭露头角,尤其是基于上下文学习(ICL-based) [89] 和微调(FT-based)技术 [63] 的方法。因此,研究人员有必要系统地理解基于LLM的文本到SQL的关键方法、挑战和未来方向。鉴于这一重要性,我们对2022年4月到2024年10月期间发表的92篇相关文献进行了系统概述,并选择了2017年到2024年10月间关于文本到SQL的开源数据集和评估指标。通过考察基于LLM的文本到SQL的发展趋势,并从多角度审视一系列研究成果,我们旨在概述潜在的挑战和未来研究的方向。 总之,本综述的贡献包括: • 研究趋势分析:我们对所调查的文献进行了分析,识别出研究趋势,包括按出版日期、出版平台和主要贡献类型进行的分类。 • 文献概览:我们将基于LLM的文本到SQL研究分为三大类:方法论、数据集和评估指标。每一类别都按顺序介绍,为读者提供系统的概述。 • LLM方法的新分类法:我们提出了一种新的SQL生成方法分类法,将其分为四种主要范式:预处理、上下文学习、微调和后处理。每个领域根据特定的模型设计进一步细分,提供了对当前创新的系统回顾。 • 数据集和评估指标概述:我们对现有的文本到SQL任务的数据集和评估指标进行了概述。 • 当前挑战与未来方向的讨论:通过对所调查文献的分析,我们识别出当前研究中的几个重要障碍。此外,我们还讨论了未来研究的关键方向,为开发更健壮、高效和可靠的系统提供指导。 本文的其余部分安排如下:第二部分介绍了文本到SQL模型的发展,强调了使用LLM进行SQL生成的原因。第三部分概述了我们的系统文献综述方法。第四部分考察了基于LLM的文本到SQL研究趋势。第五部分探讨了现有的方法论,并将其分类为预处理、上下文学习、微调和后处理范式。第六部分回顾了现有的文本到SQL数据集和评估指标。第七部分讨论了文本到SQL中的当前挑战和潜在的未来研究方向。第八部分分析了我们研究的有效性威胁,第九部分总结了本综述。我们希望本综述能够为当前进展提供清晰的全景图,并激发未来在基于LLM的SQL生成领域的探索。