

大型语言模型(LLMs)已成为自然语言处理(NLP)领域的基石,它们在理解和生成类人文本方面提供了变革性的能力。然而,随着它们日益突出的地位,这些模型的安全性和脆弱性问题也引起了重大关注。本文提供了一项关于针对LLMs的各种形式攻击的综合综述,讨论了这些攻击的性质和机制、潜在影响以及当前的防御策略。我们深入探讨了旨在操纵模型输出的对抗性攻击、影响模型训练的数据污染,以及与训练数据开发相关的隐私问题。文章还探讨了不同攻击方法的有效性、LLMs对这些攻击的抵御能力,以及这对模型完整性和用户信任的含义。 通过审查最新研究,我们提供了关于LLM脆弱性和防御机制当前景观的见解。我们的目标是提供对LLM攻击的细致理解,增进AI社区内的意识,并激发出为减轻这些风险而在未来发展中采用的强大解决方案。
人工智能的出现****在自然语言处理领域引发了一场显著的变革,通过引入大型语言模型(LLMs),实现了在语言理解、生成和翻译方面前所未有的进步(赵等,2023c;纳维德等,2023;阿恰姆等,2023)。尽管它们带来了变革性的影响,LLMs已变得容易受到各种复杂攻击的攻击,这对它们的完整性和可靠性构成了重大挑战(姚等,2023;刘等,2023d)。这篇综述论文全面检查了针对LLMs的攻击,阐明了它们的机制、后果和迅速发展的威胁环境。 研究LLMs上的攻击之重要性在于它们在各个领域的广泛整合及其随之而来的社会影响(埃隆杜等,2023)。LLMs在从自动化客户支持到复杂内容创建的应用中发挥着重要作用。因此,理解它们的脆弱性对于确保AI驱动系统的安全性和可信度至关重要(阿莫迪等,2016;亨德里克斯等,2023)。本文基于模型权重的访问权限和攻击向量,对攻击的范围进行了分类,每种都提出了不同的挑战,需要特定的关注。 此外,本文还剖析了执行这些攻击的方法论,提供了利用对抗性技术来利用LLM脆弱性的见解。在承认当前防御机制的限制的同时,本文还提出了增强LLM安全性的未来研究可能途径。 我们总结了我们工作的主要贡献如下:
**我们的贡献 **
➠ 我们提出了一种新的LLMs攻击分类法,这可以帮助研究人员更好地理解研究环境并找到他们的兴趣领域。 ➠ 我们详细介绍了现有的攻击和缓解方法,讨论了关键的实施细节。 ➠ 我们讨论了重要挑战,突出了未来研究的有希望方向。 探索LLM安全性:白盒和黑盒攻击 本节从白盒和黑盒的角度深入探讨了大型语言模型(LLMs)的安全挑战。它强调了理解和保护LLMs免受复杂安全威胁的重要性。 白盒这些攻击利用对LLM的架构、训练数据和算法的完全访问权限,使攻击者能够提取敏感信息、操纵输出或插入恶意代码。Shayegani等人(2023)讨论了白盒攻击,强调这种访问权限允许制造对抗性输入以改变输出或损害性能。该研究涵盖了各种攻击策略,如上下文污染和提示注入,旨在操纵LLMs以获得特定输出或降低其质量。 另外,李等人(2023a)检查了LLMs中的隐私问题,强调了在不断发展的AI技术面前保护个人信息的重要性。他们讨论了与训练和推理数据相关的隐私风险,强调了分析白盒攻击以有效缓解威胁的关键需求。 黑盒这些攻击利用LLM的脆弱性,对模型内部的了解有限,专注于通过输入输出界面操纵或降低性能。这种在实际场景中现实的方法带来了如敏感数据提取、偏见输出和对AI信任的减少等风险。Chao等人(2023)展示了黑盒方法“破解”诸如GPT-3.5和GPT-4之类的LLMs,而Qi等人(2023a);Yong等人(2023)探索了针对各种表面的基于API的模型如GPT-4的攻击。
LLM攻击分类法
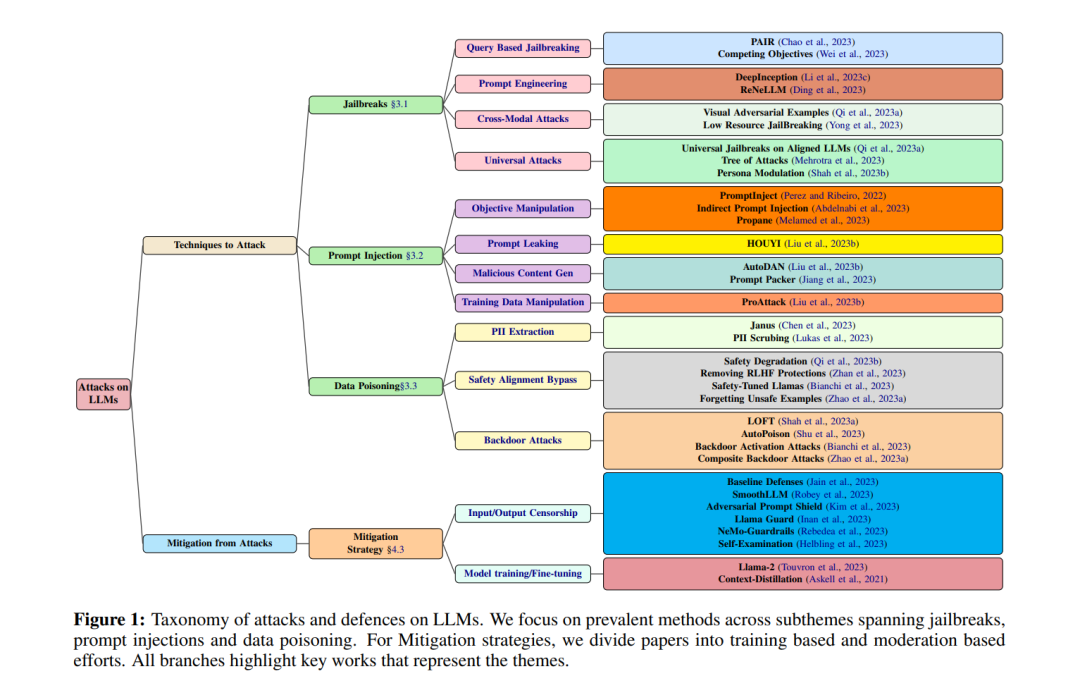
破解
本节深入探讨了针对LLMs的破解攻击,详细介绍了利用模型脆弱性进行未授权行为的策略,强调了强大防御机制的关键需求。 精细化基于查询的破解:Chao等人(2023)代表了一种策略性的破解方法,利用最少数量的查询。这种方法不仅利用了简单的模型脆弱性,而且涉及到对模型响应机制的微妙理解,迭代地精细化查询以探测并最终绕过模型的防御。这种方法的成功强调了LLMs的一个关键脆弱性:通过迭代、智能查询的可预测性和可操纵性。这项工作引入了Prompt Automatic Iterative Refinement (PAIR),一种旨在自动化生成LLMs语义破解的算法。PAIR通过使用一个攻击者LLM迭代地查询目标LLM,精细化候选破解。这种方法比以前的方法更高效,需要的查询次数更少,通常在二十次查询内就可以产生一个破解。PAIR在破解包括GPT-3.5/4和Vicuna在内的各种LLMs中展示了成功,其效率和可解释性显著,使得破解可转移到其他LLMs。 复杂的提示工程技术:Perez和Ribeiro(2022)深入探讨了LLMs的提示处理能力的复杂性。他们展示了在提示中嵌入某些触发词或短语可以有效劫持模型的决策过程,导致编程的伦理约束被覆盖。(丁等,2023)专注于使用嵌套提示的微妙、难以检测的破解方法。这些发现揭示了LLMs内容评估算法的一个关键缺陷,表明需要更复杂、上下文感知的自然语言处理能力,以识别和中和操纵性提示结构。 跨模态和语言攻击表面:Qi等人(2023a)揭示了LLMs对结合文本和视觉线索的多模态输入的易感性。这种方法利用了模型对非文本信息处理不够强大的优势。同样,Yong等人(2023)揭露了LLMs在处理低资源语言时的高度脆弱性。这表明了模型语言覆盖和理解的显著差距,特别是对于在训练数据中代表性有限的语言。这项工作展示了通过将不安全的英语输入翻译成低资源语言,可以规避GPT-4的安全保护措施。 通用和自动化攻击策略:如(Mehrotra等,2023)讨论的通用和自动化攻击框架的发展,标志着破解技术的一个关键进步。这些攻击涉及将特别选择的字符序列附加到用户的查询上,这可能导致系统提供未过滤的、潜在有害的响应。Shah等人(2023b)检查了利用LLMs的人格或风格模仿能力的攻击,为攻击策略引入了新的维度。
提示注入
本节概述了攻击者使用精心设计的恶意提示来操纵LLM行为的策略,并将研究组织成七个关键领域。 目标操纵:Abdelnabi等人(2023)展示了一种能够完全破坏LLMs的提示注入攻击,其实际可行性在如Bing Chat和Github Copilot的应用上得到展示。Perez和Ribeiro(2022)引入了PromptInject框架,用于目标劫持攻击,揭示了对提示错位的脆弱性,并提供了如停止序列和后处理模型结果等抑制措施的见解。 提示泄露:刘等人(2023b)讨论了像GPT-4这样的大型语言模型的安全漏洞,关注于提示注入攻击。它引入了HOUYI方法论,一种设计用于多种LLM集成服务/应用的通用和适应性强的黑盒提示注入攻击方法。HOUYI包括三个阶段:上下文推断(与目标应用交互以掌握其固有的上下文和输入输出关系)、有效负载生成(根据获得的应用上下文和提示注入指南制定提示生成计划),以及反馈(通过审查LLM对注入提示的响应来评估攻击的有效性,随后进行迭代精细化以获得最佳结果),旨在诱导LLM将恶意有效负载解释为问题而非数据负载。在使用HOUYI对36个真实世界LLM集成服务进行的实验中,攻击成功率达到86.1%,揭示了诸如未授权模仿服务和利用计算能力等严重后果。 恶意内容生成:刘等人(2023a)针对恶意提示生成的可扩展性挑战,提出了AutoDAN,旨在保持提示的意义性和流畅性。他们强调,发现提示注入攻击与恶意问题相结合,可以导致LLMs绕过安全特性,生成有害或令人反感的内容。使用为结构化离散数据集量身定制的层次遗传算法将AutoDAN与现有方法区分开来。种群的初始化至关重要,论文采用了LLM用户识别的手工破解提示作为原型,以减少搜索空间。引入了对句子和词的不同交叉策略,以避免陷入局部最优并持续搜索全局最优解。实现细节包括基于轮盘选择策略的多点交叉策略和一个动量词评分方案,以增强在细粒度空间的搜索能力。该方法实现了较低的句子困惑度,表明攻击在语义上更有意义且更隐蔽。 操纵训练数据:赵等人(2023b)介绍了ProAttack,它在规避防御方面拥有近乎完美的成功率,强调了随着LLMs应用的增长,更好地处理提示注入攻击的紧迫性。 LLM集成应用中的提示注入攻击与防御:如(刘等,2023e)等综合研究强调了理解和缓解提示注入攻击所带来风险的重要性。这些工作突出了像‘HouYi’(刘等,2023e)这样的复杂方法论,并强调了更强大安全措施的迫切需求。 提示操纵框架:最近的文献探讨了操纵LLM行为的各种方法,如(Melamed等,2023;江等,2023)所详细描述的。Propane(Melamed等,2023)介绍了一个自动提示优化框架,而Prompt Packer(江等,2023)介绍了组合指令攻击,揭示了LLMs对多方面攻击的脆弱性。 基准测试和分析LLM提示注入攻击:Toyer等人(2023)提出了一个包含提示注入攻击和防御的数据集,提供了关于LLM脆弱性的见解,并为更强大的系统铺平了道路。这种基准测试和分析对于理解提示注入攻击的复杂性和开发有效的对策至关重要。
数据污染
当代NLP系统遵循两阶段流程:预训练和微调。预训练涉及从大型语料库学习以理解一般语言结构,而微调则使用较小的数据集为特定任务定制模型。最近,像OpenAI这样的提供商已经允许最终用户微调模型,增强了适应性。本节探讨了关于数据污染技术及其在训练期间对安全性影响的研究,包括隐私风险和对抗性攻击的敏感性。 个人可识别信息(PII)提取:陈等人(2023)研究了在包含个人可识别信息(PII)的小数据集上微调大型语言模型(LLMs)是否会导致模型泄露其原始训练数据中嵌入的更多PII。作者展示了一种稻草人方法,其中一个LLM在转换为文本的小型PII数据集上进行微调,这使得模型在被提示时能够泄露更多PII。为了改进这一点,他们提出了Janus方法,该方法定义了一个PII恢复任务并使用少量示例微调。实验表明,仅在10个PII实例上微调GPT-3.5就使其能够准确泄露1000个目标PII中的650个,而不微调则为0。Janus方法进一步改善了这种泄露,泄露了699个目标PII。分析显示更大的模型和真实训练数据具有更强的记忆和PII恢复能力,且微调对PII泄露比单独的提示工程更有效。这表明LLMs可以通过最小的微调从不泄露转变为泄露大量PII。 绕过安全对齐:齐等人(2023b)研究了在微调对齐的LLMs中的安全风险,发现即使是良性数据集也可能危及安全。背景攻击被证明可以有效绕过安全措施,强调了改进训练后保护的需求。 Bianchi等人(2023)分析了指令调优的安全风险,显示过度指令调优的模型仍然可以产生有害内容。他们提出了一个安全调优数据集来减轻这些风险,平衡安全性和模型性能。 赵等人(2023a)研究了LLMs在微调过程中如何学习和遗忘不安全的示例,提出了一种称为ForgetFilter的技术,用于过滤微调数据并在不牺牲性能的情况下提高安全性。 后门攻击:沙等人(2023a)引入了Local Fine Tuning(LoFT)来发现对抗性提示,展示了对LLMs的成功攻击。舒等人(2023)提出了Autopoison,一种自动化数据污染管道,展示了其在不降低语义质量的情况下改变模型行为的有效性。 结论
本文提供了针对大型语言模型(LLMs)攻击的全面概述。我们首先将LLM攻击文献分类为一个新的分类法,以提供更好的结构并为未来的研究提供帮助。通过审查这些攻击向量,显而易见的是,LLMs容易受到多种威胁的攻击,这对它们在现实世界应用中的安全性和可靠性构成了重大挑战。此外,本文强调了实施有效的缓解策略来防御LLM攻击的重要性。这些策略包括多种方法,包括数据过滤、防护措施、强健的训练技术、对抗性训练和安全上下文蒸馏。 总结来说,尽管LLMs为提高自然语言处理能力提供了重大机遇,但它们对敌手利用的脆弱性凸显了解决安全问题的紧迫需求。通过持续探索和进步,在检测攻击、实施缓解措施和提高模型韧性方面,我们可以旨在充分利用LLM技术的优势,同时加强防御以抵御潜在风险。
