
基于Transformer的模型目前在NLP中得到了广泛的应用,但我们对它们的内部工作原理仍然知之甚少。本文综合了40多项分析研究,对著名的BERT模型(Devlin et al 2019)的已知情况进行了描述。我们还提供了对模型及其训练机制的拟议修改的概述。然后我们概述了进一步研究的方向。
概述
自2017年推出以来,Transformers(Vaswani et al 2017)掀起了NLP的风暴,提供了增强的并行化和更好的长依赖建模。最著名的基于Transformers 的模型是BERT (Devlin et al 2019),他们在许多基准测试中获得了最先进的结果,并集成在谷歌搜索中,提升了10%的查询准确率。
虽然很明显BERT和其他基于Transformer的模型工作得非常好,但是不太清楚为什么,这限制了架构的进一步假设驱动的改进。与CNNs不同,Transformer几乎没有认知动机,而且这些模型的大小限制了我们进行预训练实验和消融研究的能力。这解释了过去一年里大量的研究试图理解BERT表现背后的原因。
本文概述了迄今为止所了解到的情况,并强调了仍未解决的问题。我们重点研究BERT学习的知识的类型,这些知识在哪里体现,如何学习,以及提出的改进方法。
BERT架构
从根本上说,BERT是一堆由多个“头”组成的Transformer 编码器层,即全连接神经网络增强了一个自我注意机制。对于序列中的每个输入标记,每个头计算键、值和查询向量,这些向量用于创建加权表示。将同一层中所有磁头的输出合并并通过全连接层运行。每个层都用一个跳过连接进行包装,并在它之后应用层规范化。
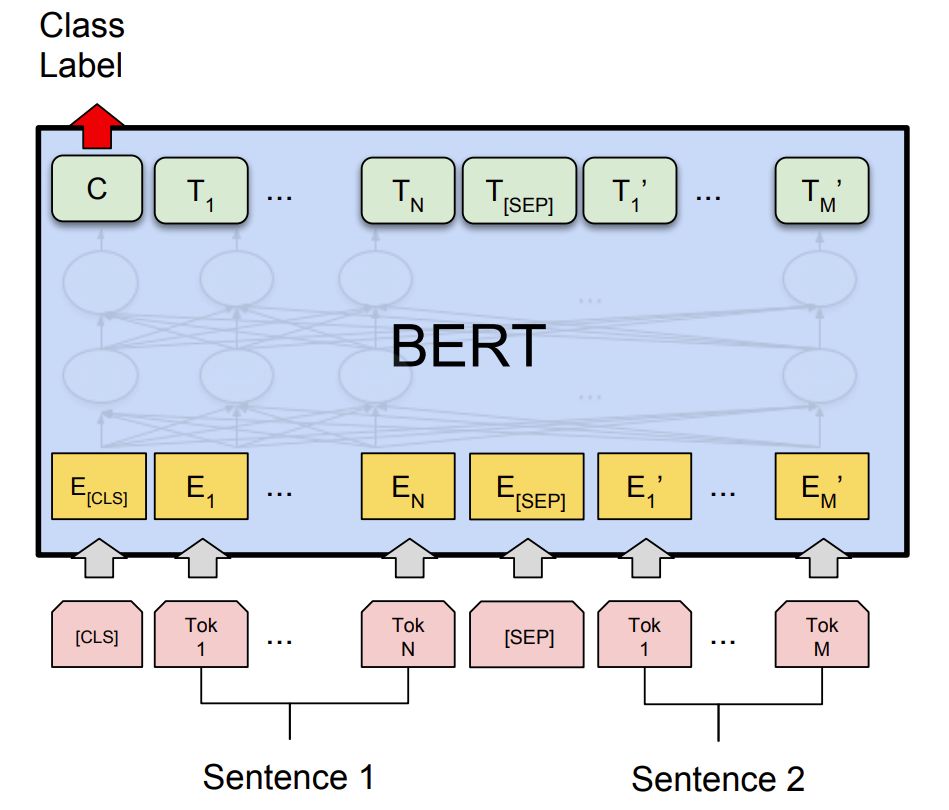
图1 BERT模型
目录:
- BERT嵌入
- BERT拥有什么知识
- 局部化语言知识
- 训练BERT
- BERT模型尺寸
- 多语言BERT
成为VIP会员查看完整内容

相关内容

Arxiv
15+阅读 · 2018年10月11日

相关VIP内容
相关资讯
相关论文
Arxiv
15+阅读 · 2018年10月11日