

深度强化学习技术以一种端到端学习的通用形式融合了深度学习的感知能力与强化学习的决策能力, 在多个领域 得到了广泛应用, 形成了人工智能领域的研究热点. 然而, 由于对抗样本等攻击技术的出现, 深度强化学习暴露出巨大的安 全隐患. 例如, 通过在真实世界中打印出对抗贴纸便可以轻松地使基于深度强化学习的智能系统做出错误的决策, 造成严重 的损失. 基于此, 本文对深度强化学习领域对抗攻防技术的前沿研究进行了一次全面的综述, 旨在把握整个领域的研究进展 与方向, 进一步推动深度强化学习对抗攻防技术的长足发展, 助力其应用安全可靠. 结合马尔科夫决策过程中可被扰动的空 间, 本文首先从基于状态、 基于奖励以及基于动作角度的详细阐述了深度强化学习对抗攻击的进展; 其次, 通过与经典对抗 防御算法体系进行对齐, 本文从对抗训练、 对抗检测、 可证明鲁棒性和鲁棒学习的角度归纳总结了深度强化学习领域的对 抗防御技术; 最后, 本文从基于对抗攻击的深度强化学习机理理解与模型增强的角度分析了对抗样本在强化学习领域的应用 并讨论了领域内的挑战和开放研究方向.
1 引言
人工智能技术是引领新一轮科技革命和产业 变革的战略性技术, 已经成为世界各国抢占战略制 高点、 开展科技竞争的核心领域. 这其中, 深度强 化学习(Deep Reinforcement Learning, DRL)融合了 强化学习的自我激励决策能力和深度学习的抽象 表征感知能力, 通过赋予智能体自监督学习机制, 在不断地与环境交互过程中修正策略并使用深度 神经网络的强大表征能力拟合复杂高维的环境特 征, 形成了人工智能领域新的研究热点. DRL 这种 通用性较强的端到端感知控制系统展示出了人类 专家级别的能力, 并在公共安全、 金融经济、 国 防安全等领域得到了应用, 发挥了极其关键的作用 [1-4] . 例如, 2017 年基于 DRL 的 AlphaGo 系统在复 杂的围棋比赛中击败了人类世界围棋冠军 [5] ; AlphaStar 在星际争霸游戏比赛中战胜了多位人类 职业电竞选手, 证明了 DRL 在复杂空间中的有效 性; DRL 在商业领域的推荐系统中也大放异彩. 这 些都充分地展示了深度强化学习技术的重要性、 实用性以及非凡的应用价值. 然而, 由于现实应用 场景的开放性, 以大数据训练和经验性规则为基础 的深度强化学习方法面临环境的动态变化、 输入 的不确定性、 甚至是恶意攻击等问题, 暴露出稳定 性、 安全性等方面的安全隐患. Christian Szegedy 等人[6]在 2013 年首次发现并提出了出现在计算机 视觉领域的对抗样本(Adversarial examples). 这种 样本隐藏了微小的恶意噪声, 人眼无法区分但会导 致人工智能算法模型产生错误的预测结果, 对其安 全性和可靠性构成了严重的威胁. 除了计算机视觉 领域, 研究学者还发现对抗样本对于自然语言处理、 深度强化学习等不同领域和类型的人工智能 算法和系统都能够产生较强的迷惑性和攻击性. 更 为重要的是, 对抗样本可以在没有目标模型具体信 息的条件下轻易地攻破智能系统并迫使其产生攻 击者期望的任何输出. 在军事领域和民用公共安全领域存在着大量 以深度强化学习为基础的智能应用场景, 如: 智能 无人机控制[7]、 智能视觉导航[8]、 车联网计算控 制[9]、 异构工业任务控制[10]等, 这些安全攸关的场 景对于人工智能的安全、 可靠、 可控有极高的需 求. 然而, 基于深度强化学习的智能算法都极易受 到对抗噪声的干扰产生不可预期的错误, 甚至可能 被误导产生严重的安全问题. 例如, 对抗噪声的攻 击可以造成真实世界的自动驾驶系统错误地识别 路牌、 做出错误的决策行为, 引发危险事故; 自动 导航机器人在遇到对抗噪声攻击后就会执行错误 的决策, 执行错误的路径预测, 无法达到预设终点; 在多智能体博弈场景中, 攻击者还能利用某个智能 体的对抗行为来诱导其他智能体产生错误的动作、 配合, 使其最终输掉博弈比赛[11-17] . 可以看到, 对 抗攻击的出现对于深度强化学习的安全、 可靠、 稳定应用提出了极大的挑战. 因此, 系统性地分析 归纳深度强化学习对抗攻防研究发展脉络和未来 方向, 对于深刻认识深度强化学习鲁棒性的研究进 展与方向、 进一步解决研究不足之处并推动安全 可靠深度强化学习技术的发展都显得尤为重要. 然 而, 学术界对于深度强化学习对抗安全的综述性研 究却仍十分滞后: 研究人员[12,18-20]于 2018 年和 2020 年对深度强化学习的对抗攻防进行了初步的 总结探讨, 然而这些研究距发表至今已数年有余, 缺乏对大量较新研究成果的涵盖,对于领域未来发 展脉络的把握也已不足. 在此背景下, 为了系统全 面地梳理 DRL 对抗攻防的发展思路、 进一步支撑 和推动高安全和可信赖深度强化学习技术的发展, 本文针对深度强化学习算法模型的对抗攻防开展 了系统的综述性研究, 从面向深度强化学习的对抗 攻防技术的发展现状、 研究历程、 未来趋势进行 了详细的讨论.
本文围绕面向深度强化学习的对抗攻防技术 展开研究和讨论, 其组织结构如下: 第 1 章介绍本 文的研究背景、研究内容等; 第 2 章主要从强化学 习和对抗样本两个角度对相关预备知识和概念进 行介绍及定义; 第 3 章从基于状态、基于奖励以及 基于动作这三个角度对 DRL 的对抗攻击技术进行讨论和分析; 进一步, 第 4 章主要从对抗训练、 对 抗检测以及可证明鲁棒性这三个角度对 DRL 的对 抗防御算法进行讨论和总结; 在第 5 章中, 本文又 进一步归纳并讨论了基于对抗的强化学习机理理 解和模型增强, 如: 对抗增智等; 第 6 章结合深度 强化学习对抗攻防领域的挑战进行了讨论和分析; 最后, 第 7 章给出本文的结论和未来研究方向.
2. 面向深度强化学习的对抗攻击技术
基于上文所述, 本文将对强化学习的攻击分为 基于状态𝒮、 基于奖励𝑅以及基于动作𝒜三种攻击方式, 并按照这三种方式进行归纳总结(如表 1 所 示). 其中, 基于状态𝒮的攻击通过扰动智能体观测 或者改变智能体观测结果, 从而诱使智能体做出最 小化目标函数的决策; 基于奖励𝑅的攻击通过微小 地扰动智能体训练过程中的奖励函数, 从而影响智 能体的全局策略; 基于动作𝒜的攻击直接对智能体 的动作进行微小扰动, 从而大幅影响智能体的目标 函数, 或通过训练具有对抗策略的智能体从而影响 其他智能体决策. 对应至公式 3 中经典对抗样本 𝐱𝑎𝑑𝑣的定义, 强化学习中的对抗攻击分别从𝒮、 𝑅 和𝒜三个空间中加入噪声进行对抗攻击. 从攻击者 的角度来看,基于状态和奖励的攻击需要能够获取 到模型的控制权, 相比基于动作的攻击更加困难一 些.
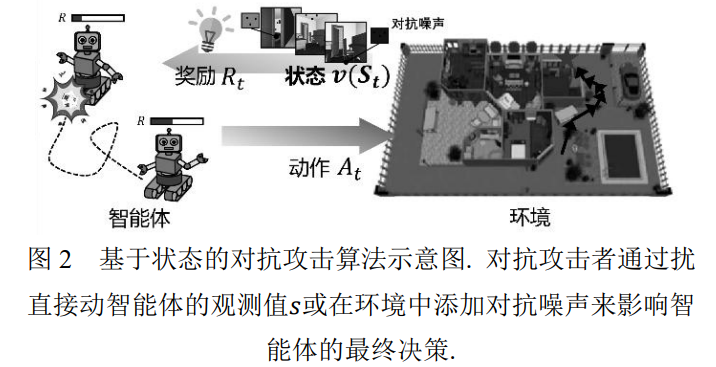
基于状态的对抗攻击 在这一节中, 本文将梳理和归纳基于状态的深 度强化学习对抗攻击算法. 我们将基于状态的攻击 (如图 2)分为两类: 基于观测的对抗攻击与基于环 境的对抗攻击. 其中, 基于观测的对抗攻击主要通 过扰动智能体的观测值𝑠, 从而改变智能体策略 𝜋(𝑠) = 𝑝(𝑠|𝑎)来实现攻击; 基于环境的对抗攻击在 环境中添加对智能体观测值𝑠的扰动的同时, 还要 求此扰动符合状态转移方程𝒯 = 𝑝(𝑠 ′ , 𝑟|𝑠, 𝑎); 对于 算法开销而言, 如果攻击方式仅对强化学习的单步 决策进行攻击, 则攻击者通过规则直接确定强化学 习需要扰动的变量, 并使用模型梯度直接生成可以 攻击强化学习策略网络的噪声, 攻击开销较小. 如 果攻击方式需要对强化学习的整体策略进行规划, 则攻击者所做出的决策则需要通过求解马尔可夫 决策过程, 即训练一个攻击者具有的强化学习智能 体获取. 随后, 攻击者在攻击阶段基于其训练的强 化学习智能体生成目标噪声. 这类方法由于需要训 练强化学习智能体, 攻击开销中等.
基于奖励的对抗攻击
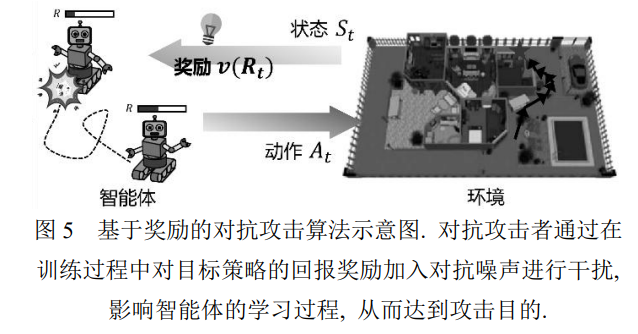
基于奖励的对抗攻击(如图 5)主要是对目标策 略的回报奖励加入对抗噪声进行干扰, 影响智能体 的学习过程, 尽可能减少所学策略的回报, 从而达 到攻击目的.
基于智能体动作的对抗攻击
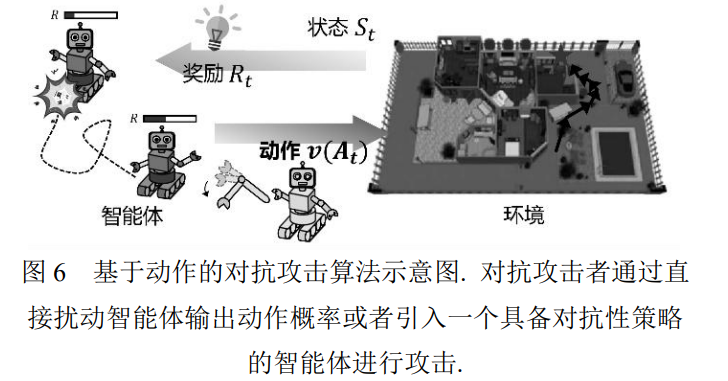
在基于观测和基于奖励的对抗攻击外, 业内也 存在不少工作从强化学习智能体行为动作方面展 开对抗攻击的研究(如图 6). 一方面, 可以通过直接 扰动智能体策略输出动作的概率来进行攻击; 另一 方面, 可以引入另一个智能体, 使其具备对抗性策 略并做出攻击性动作, 造成原智能体回报大幅下 降.
小结
在本章中, 我们系统性地介绍了近年来深度强 化学习领域对抗攻击的研究, 并从基于状态、 基于 奖励以及基于动作三个角度对这些工作进行了分 类和总结.(1) 基于状态的攻击算法是针对深度强化学习的对抗攻击中研究最多、 范围最广的攻击方式. 已 有的工作从黑盒或白盒、 训练或测试阶段等不同 角度提出了各种高效的基于状态的攻击算法. 由于 和经典的计算机视觉中的对抗攻击方式相似, 这类 攻击算法适用范围广, 攻击效果好, 且具有丰富的 研究工作作为基础. 然而, 这些算法几乎全部派生 自传统对抗攻击方法, 针对强化学习任务进行了调 整, 并没有提出具有足够创新性的理论改进; 与此 同时, 由于本身与传统对抗攻击方法的相似性, 这 些方法也容易被传统对抗防御方法克制.(2) 基于奖励的攻击算法以奖励函数投毒为基本思想, 并针对实际应用场景进行了改进, 通过对 奖励函数添加噪声或符号翻转来对模型训练过程 造成影响, 从而实现对抗攻击. 基于奖励的攻击方 法往往不限制待攻击模型或算法, 适合用于扰动经 验回放池中的奖励符号, 从而对模型训练带来长期 影响. 同时, 基于奖励的攻击方法对于在线学习类的强化学习算法也有可预见的攻击效果.(3) 基于动作的对抗攻击充分利用了强化学习的特点, 抓住其与传统计算机视觉中任务的不同点 进行攻击. 不同于传统的分类任务, 在强化学习任 务的马尔可夫过程中, 动作既是上一次策略网络的 输出, 也会影响到下一次网络自身的输入. 即对动 作的扰动会带来时序层面的影响, 对网络关键输出 的扰动价值也远大于传统对抗攻击. 无论是基于动 作概率还是基于对抗策略的攻击, 都是强化学习领 域中特定的攻击算法, 具有重要价值和挖掘潜力. 可以看到, 由于强化学习训练过程的特殊性, 存在一定量的算法是在智能体训练阶段实施攻击 的. 值得注意的是, 这些攻击算法借鉴了投毒攻击 [67]的基本思想, 将加入了噪声的样本混入训练过 程, 使得智能体模型在最终的测试阶段产生错误预 测. 它虽然与在测试阶段直接污染测试数据的对抗 攻击不完全一致, 但是其攻击目标是一致的. 在本 文中, 笔者将其描述为“训练阶段的对抗攻击”. 总体来看, 针对强化学习的对抗攻击方法研究 依然存在不足: 一方面, 现有的大部分工作主要是 基于传统对抗攻击算法在强化学习领域的应用, 如 何利用强化学习本身特性进行攻击尚有研究空间; 另一方面, 强化学习领域的对抗攻击方法普遍存在 迁移性不强、 难以实现的问题, 缺乏在物理世界中 的实验.
3 面向强化学习的对抗防御技术
在系统的归纳总结了深度强化学习领域的对 抗攻击研究后, 本章进一步分析深度强化学习领域 中的对抗防御方法的研究. 与针对攻击的分析不同 之处在于, 本文并没有直接基于马尔科夫决策过程 四元组进行对抗防御的分类. 相反, 本章结合传统 对抗防御方法的分类方式从对抗训练、 对抗检测、 可证明鲁棒性、 鲁棒学习等角度出发, 对现有工作 进行梳理总结(如表 2 所示). 笔者认为: 首先, 大量 的防御方式都是用于防御状态扰动攻击, 直接从状 态、 奖励、 动作的维度进行分类可能会造成极度 的不平衡, 丧失分类讨论分析的意义; 其次, 这种 分类方式可以帮助研究人员将强化学习中的对抗 防御手段与经典对抗防御体系进行对齐, 更好地理 解在 DRL 领域中的对抗防御算法.
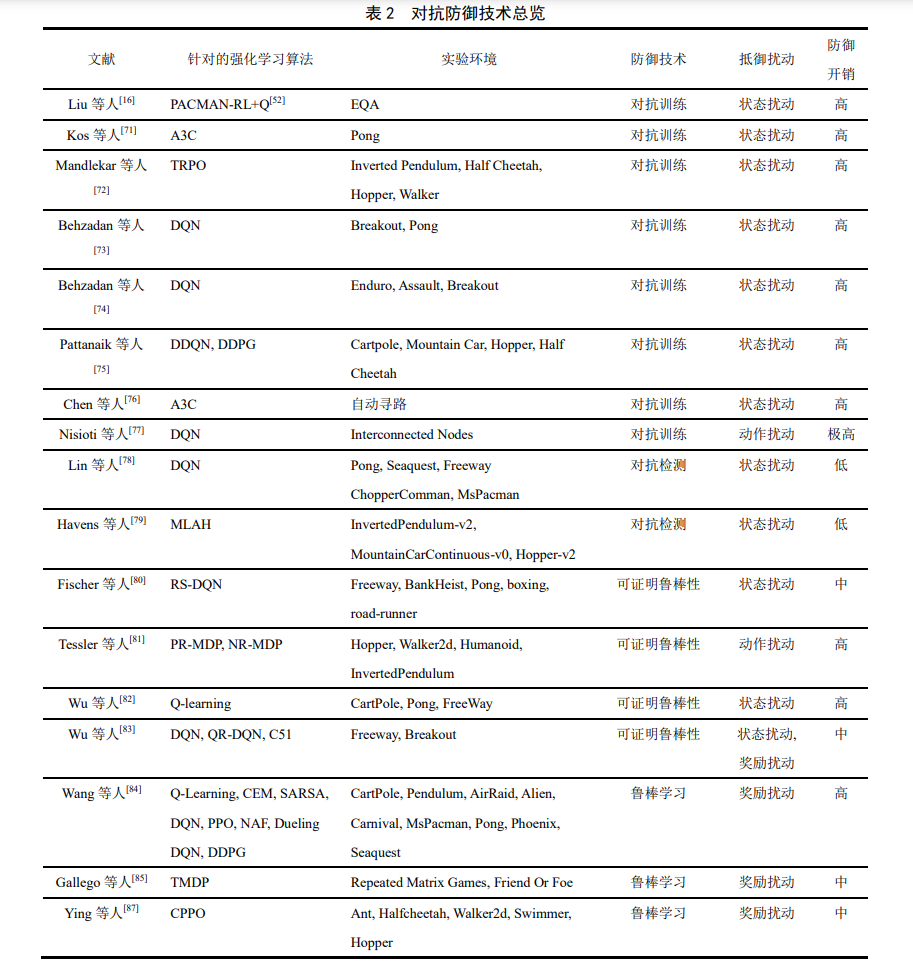
在本章中, 我们针对强化学习领域中的对抗防 御方法作了较为全面的回顾, 从传统对抗攻防领域 中的对抗训练、 对抗检测、 可证明鲁棒性等防御 方法出发, 对现有工作进行梳理总结. (1) 一系列工作将传统对抗攻防中的对抗训练算法迁移应用到深度强化学习领域中. 通过在智能 体训练过程中引入干扰噪声(大多选用简单的 FGSM对抗攻击算法生成扰动), 对智能体的状态进 行扰动进而优化智能体对于噪声的鲁棒性. 然而, 这些方法并未对强化学习本身特性进行更深入的 研究, 只是将对抗训练方法的思想迁移至深度学习 领域进行应用, 并未取得防御技术的发展突破. (2) 基于对抗检测的防御方法从分辨干净样本 与对抗样本角度入手, 使用专门训练的检测模型分 离出干净样本. 其优点在于不改变智能体的原有策 略, 但这种方法的通用防御能力相对较弱, 检测器 对于训练过程使用的对抗样本会具有较好的检测 能力, 而一旦面对未曾在训练中出现的对抗攻击方 法, 则难以有效检测出对抗样本. 基于对抗检测的 防御方法适合于智能体开箱即用的强化学习场景, 从而在智能体不修改的情况提供防御能力. (3) 基于可证明鲁棒性的防御方法结合了强化 学习决策过程, 通过对智能体鲁棒性下界给出证明 (如扰动半径的下界), 在理论层面为智能体鲁棒性 进行了保护. 经过鲁棒认证的智能体模型能在认证 范围内安全鲁棒, 但这种防御方法也存在一些限制 (如: 主要针对ℓ1 , ℓ2范数约束下的对抗样本), 与 基于经验性的鲁棒防御算法的表现(如: 对抗训练) 仍有差异. 这种防御方法如果能在更多情况下推广 应用(如: ℓ∞范数下的对抗样本), 将为深度强化学 习在理论的鲁棒性提供有力保障. (4) 与上述防御方法不同的是基于鲁棒学习的 防御策略. 这类方法针对强化学习算法的特点, 应 用与算法适配的特殊方法(如: 混淆矩阵、 奖励估 计等)来进行防御. 这类防御方法与强化学习算法 场景紧密耦合, 在其它算法上难以进行通用的适 配. 然而, 由于其和强化学习的独特关系, 这个方 向具有重要研究价值和挖掘潜力.
目前而言, 针对强化学习领域中对抗防御的研 究仍旧存在较大的发展空间: (1) 现有的防御方法 大多是传统对抗防御算法在强化学习中的迁移应 用, 未来还需要从强化学习本身特性进一步探索; (2) 现有防御方法的泛化能力不足, 需要探索更通 用的防御方法, 保障智能体在动态复杂环境面对不 确定干扰时的鲁棒表现; (3) 目前主要的防御方法 都是针对于状态扰动攻击的加固, 而针对于其他类 型对抗攻击的防御较少. 分析其背后原因可看到: 基于状态扰动攻击的定义与计算机视觉领域中的 对抗样本较为相似也是相对最早被提出、 有大量研究基础的一种攻击方法, 因此催生了大量的防御 算法. 相反, 其他类型的攻击, 如: 基于动作的攻 击和基于奖励函数的攻击都有特殊的要求 (如: 要 求在零和博弈场景中进行或直接改变奖励函数), 直接防御的难度较大, 相关的防御研究也较少.
4. 基于对抗攻击的深度强化学习机理
理解与模型增强 在本章中, 我们将介绍和分析在深度强化学习 领域除了对抗攻防之外的对抗样本相关的研究工 作, 主要分为: 使用对抗样本来分析深度强化学习 的脆弱性机理以及提升智能体的任务相关能力两 个部分, 如表 3 所示. 可以看到, 这部分研究的第 一篇相关论文发表于 2021 年, 是一个仍处于初步 探索阶段的新兴方向. 然而, 这个领域的探索向研 究人员证明了: 对抗样本对于深度强化学习并非百 害而无一益, 通过适当的手段, 对抗攻击也可以变 成一种提升对于深度强化学习可解释性和能力的 工具. 因此, 这个新兴的领域定会在未来成为深度 强化学习对抗攻击领域的一个重要研究方向.
5. 结论
深度强化学习的广泛应用引起了大量研究对 于其对抗鲁棒性的关注. 本文对于深度强化学习领 域对抗攻防技术的前沿研究进展进行了一次全面 的综述. 本文首先阐述了基于状态、 基于奖励以及 基于动作的深度强化学习对抗攻击进展; 本文接着 从对抗训练、 对抗检测、 可证明鲁棒性和鲁棒学 习的角度归纳总结了深度强化学习领域的对抗防御技术; 最后, 本文分析了基于对抗样本的深度强 化学习机理理解与模型增强并讨论了领域内的未 来研究方向. 虽然研究人员在深度强化学习领域开展了大 量对抗攻防的研究, 然而领域内还存在多个亟待解 决的问题和挑战制约着深度强化学习对抗攻防研 究的发展, 如: 面向物理世界的深度强化学习对抗 攻防仍鲜有探索、 缺乏统一标准的对抗攻防评测 基准环境等. 希望本文能够帮助更多研究人员投身 于研究和构建更加安全可靠的深度强化学习技术 之中.

