
导读 |** **CVPR是计算机视觉的世界三大顶会之一,2022年将在美国新奥尔良召开。本届会议自动化所共有35篇论文录用,我们将通过上下两期推文对相关研究进行简要介绍(排名不分先后),欢迎大家一起交流讨论。
**01. **AnyFACE: 自由式文本到人脸合成与操控
AnyFace: Free-style Text-to-Face Synthesis and Manipulation 现有的文本到图像生成的方法通常只适用于数据集中已有的单词,然而,有限的单词无法全面地描述一张人脸。因此,本文开创性地提出了一种自由风格的文本到人脸生成方法(AnyFace)以支持元宇宙、社交媒体、取证等更广泛的应用。对于任意给定的文本,AnyFace 采用一个新型的双通道网络实现人脸的生成和编辑。首先用CLIP编码器对人脸的文本和图像特征进行编码,跨模态蒸馏模块用于实现视觉和文本空间的交互。此外,本文还采用了一个多样化对比损失来生成更加多样化和细密度的细节。在多个数据集上的实验证明了算法的有效性。AnyFace可以在对输入没有限制的条件下实现高质量,高分辨率,多样性的人脸生成和编辑。
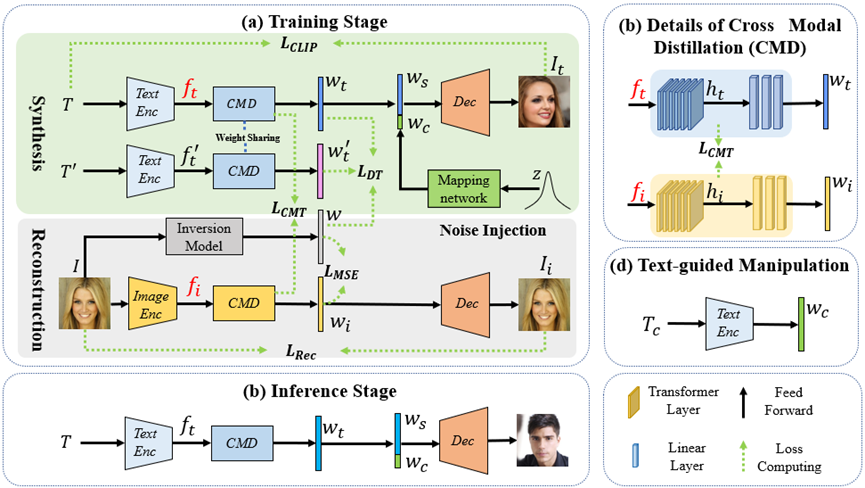
图. 自由风格的文本到人脸生成方法示意图
作者:Jianxin Sun, Qiyao Deng, Qi Li, Muyi Sun, Min Ren, Zhenan Sun
**02. **基于独立成分的艺术风格发掘
Artistic Style Discovery with Independent Components 目前大多数风格迁移模型通常选择卷积神经网络来实现高质量的图像风格化,但这些方法很少对潜在的风格空间进行探索。在潜在的风格空间中,大量信息未能得到有效的利用,这导致生成的风格可控性差以及有限的实际应用。我们重新审视了风格特征的内在意义,并且提出了一种新颖的无监督算法。该算法用于生成多种风格并实现个性化操作。我们重新探索了风格转移的机制,并从由不同风格特征组成的潜在空间中解耦出了不同的艺术风格成分。通过线性组合不同的风格成分可以生成多种新的风格特征。我们在AdaIN、SANet、Linear、MST上取得了不错的效果。

图. 基于不同模型的多样性风格化图像
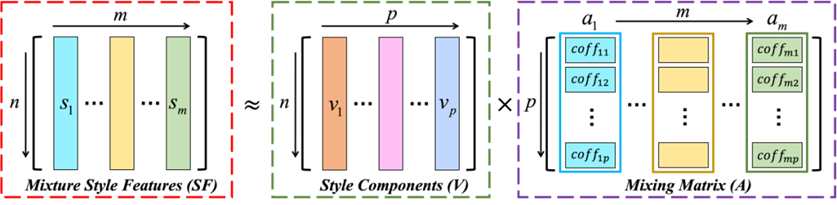
图. 风格特征由风格元件线性组合 作者:Xin Xie, Yi Li, Huaibo Huang, Haiyan Fu, Wanwan Wang, Yanqing Guo
**03. **一种基于数据域和下游任务的预训练模型
DATA: Domain-Aware and Task-Aware Pre-training 通过自监督学习 (SSL) 和对许多下游任务进行微调来在无标签的海量数据上训练模型的范式最近已成为一种趋势。 然而,由于训练成本高和下游使用的无意识,大多数自监督学习方法缺乏对应下游场景多样性的能力,因为存在各种数据域、延迟约束等。 神经架构搜索 (NAS) 是一种公认的克服上述问题的方式,但在 SSL 上应用 NAS 似乎是不可能的,因为没有提供用于判断模型选择的标签或指标。在本文中,我们介绍了 DATA,这是一种简单而有效的 NAS 方法,专门用于 SSL,提供数据域相关和任务相关的预训练模型。具体来说,我们 (i) 首先训练了一个超网,它可以被视为一组数百万个网络,涵盖了广泛的模型规模,没有任何标签,(ii) 其次提出了一种与 SSL 兼容的灵活搜索机制,可以针对没有提供明确指标的各种下游视觉任务和数据域,找到不同计算成本的网络。使用 MoCov2 实例化,我们的方法在下游任务的广泛计算成本上取得了可喜的结果,包括图像分类、目标检测和语义分割。DATA 与大多数现有 SSL 方法正交,并赋予它们根据下游需求进行定制的能力。大量的实验验证了所提出的方法在其他 SSL 方法(包括 BYOL、ReSSL 和 DenseCL)上的普适性。
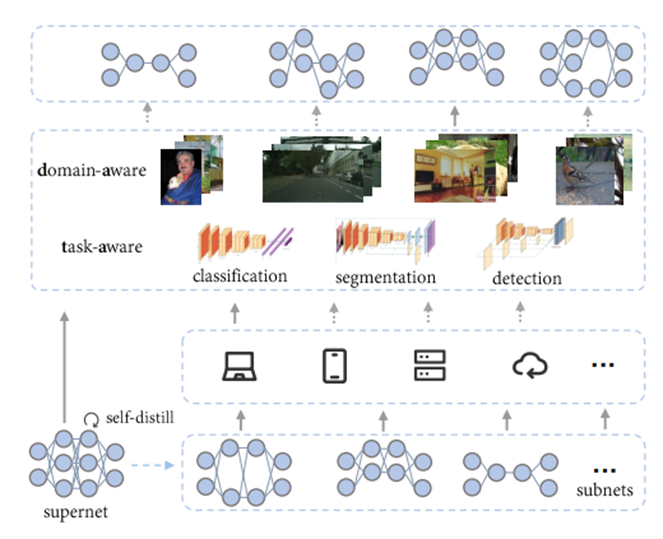
图. DATA结构设计 作者:Qing Chang, Junran Peng, Jiajun Sun, LingxiXie, Haoran Yin, Qi Tian, Zhaoxiang Zhang 代码已开源在:https://github.com/GAIA-vision/GAIA-ssl
**04. **DINE:基于单个或多个黑盒预测模型的领域自适应方法研究
DINE: Domain Adaptation from Single and Multiple Black-box Predictors 为了减轻标注的负担,无监督领域自适应学习旨在将先前和相关的已标注数据集(源域)中的知识转移到新的无标注数据集(目标域)。尽管取得了令人印象深刻的进展,但现有的方法总是需要访问原始的源域数据并依赖于此研发基于转导学习的方式识别目标样本,这可能会引起源域个体的数据隐私问题。最近的一些研究求助于另一种解决方案,即利用源域的已训练白盒模型(模型参数可见),然而,它仍然可能通过生成对抗学习来泄露原始数据。
本文研究了无监督领域自适应一种实用且有趣的场景,即在目标域自适应期间只提供黑盒源域模型(即只有网络的预测可见)。为解决这一问题,我们提出了一种新的两步知识自适应框架(DINE)。考虑到目标数据结构,DINE首先将源预测器中的知识提取到定制的目标模型中,然后对提取的模型进行微调以进一步适应目标领域。此外,DINE不需要需要跨域的网络结构一致,甚至可以在低资源设备上进行有效的自适应学习。在多个场景如单源、多源和部分集上的实验结果证实,与最先进的数据依赖方法相比,DINE均获得了极具竞争力的性能。
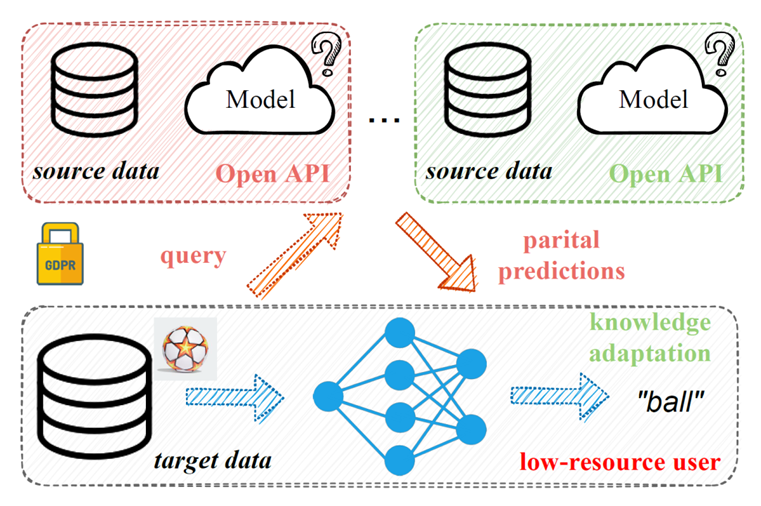
图. 基于黑盒模型的无监督域自适应学习问题
作者:Jian Liang, Dapeng Hu, Jiashi Feng, Ran He
**05. **基于稀疏Transformer的单步长3D物体检测器
Embracing Single Stride 3D Object Detector with Sparse Transformer 在自动驾驶场景中,相比于整个场景的尺度,单个物体的尺度通常很小。下图展示了COCO数据集和Waymo数据集上物体相对尺度的分布情况:

图. COCO和Waymo上物体相对尺度分布
这一特性往往被基于Pillar或者体素的检测器所忽略,它们通常借用了成熟的2D多尺度检测器的结构。基于这一考量,本文探索了单步长(无降采样)的检测器结构。如果简单地将卷积网络提升为单步长网络,会取得一定的性能提升,但是会带来感受野不足的问题以及巨大的计算量。为了得到一个高效高性能的单步长检测器,我们借用了当前流行的swin transformer的结构,舍弃了其多尺度的结构并且针对点云数据的特点将其稀疏化,我们将其命名为单步长稀疏Transformer(Single-stride Sparse Transformer, SST)。我们在当前最大的3D检测数据集Waymo Open Dataset上做了详尽的实验,从各个方面探讨了SST的特性,并取得了SoTA的性能,特别是在小物体上比之前的方法有了显著的提升(达到了83.8的Level 1 AP)。
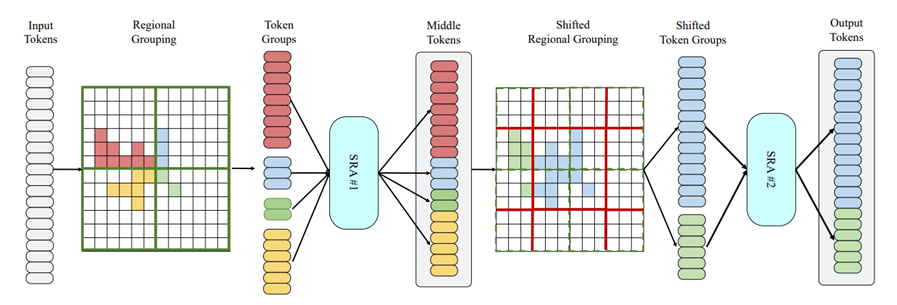
图. Sparse Attention结构设计
作者:Lue Fan, Ziqi Pang, Tianyuan Zhang, Yu-Xiong Wang, Hang Zhao, Feng Wang, Naiyan Wang, Zhaoxiang Zhang 代码已开源在:https://github.com/TuSimple/SST
**06. **基于夏普利值的少样本后门防御
Few-shot Backdoor Defense Using Shapley Estimation 神经网络在诸多领域有着广泛的应用,但已有研究表明神经网络容易遭受后门攻击,造成潜在安全威胁,因此后门防御是一个非常重要的问题。已有后门防御工作通常需要较多训练数据并剪除大量神经元,这些防御算法容易破坏网络原本结构并依赖于来网络微调操作。
为了更高效准确地去除神经网络中的后门攻击,我们提出一种基于Shapley value的ShapPruning后门去除算法。ShapPruning利用触发器逆合成估计后门触发器,并通过蒙特卡洛采样以及epsilon-greedy算法高效估计神经网络中各神经元与网络后门攻击行为的关联程度,从而准确定位后门感染神经元,进而更精准的指导后门去除。相较于之前研究,我们的工作可以在每一类只有一张图片的情况下去除后门攻击,同时印证了后门攻击只通过感染神经网络中极少数神经元(1%左右)实现网络操纵。同时,我们采用data-inverse的方法,从感染模型中恢复训练数据,提出了一种无数据的混合模式ShapPruning算法,实现了无数据的神经后门去除。我们的方法在数据缺乏情况下,在CIIFAR10, GTSRB, YouTubeFace等数据集上针对已有后门攻击方式均取得了很好的效果。
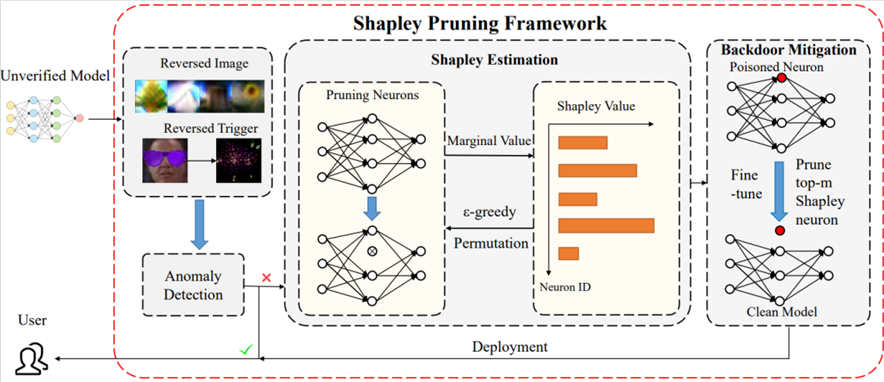
图. ShapPruning后门防御算法 作者:Jiyang Guan, Zhuozhuo Tu, Ran He, Dacheng Tao
**07. **基于隐式样本扩展的无监督行人重识别
Implicit Sample Extension for Unsupervised Person Re-Identification 现有的无监督行人重新识别(ReID)工作大都是通过聚类的方法来预测伪标签,其中同一聚类中的样本被认为具有相同的身份。然而,聚类通常会将不同的真实身份混合在一起,或者将相同的身份分成两个或多个子集群。毫无疑问,对这些有问题的集群进行训练会损害 Re-ID 的性能。 基于这一观察,我们假设现有数据分布中可能缺少一些基础信息,这些信息对于产生理想的聚类结果很重要。为了发现这些信息,提出了一种隐式样本扩展(ISE)方法来生成我们所说的围绕集群边界的支持样本。具体来说,我们开发了一种渐进线性插值(PLI)策略来指导支持样本生成的方向和程度。PLI控制支持从实际样本到其 K-最近聚类生成的样本。同时,决定了应将多少来自 K-最近集群的上下文信息纳入支持样本。此外,为了提高支持样本的可靠性,我们提出了一种保留标签的损失ISE,强制它们接近原始样本。有趣的是,有了我们的 ISE,聚类质量逐渐提高,上述子集群和混合集群的问题得到了很好的缓解。大量实验表明,所提出的方法是有效的,并且在无监督行人重识别 Re-ID 设置下实现了最先进的性能。
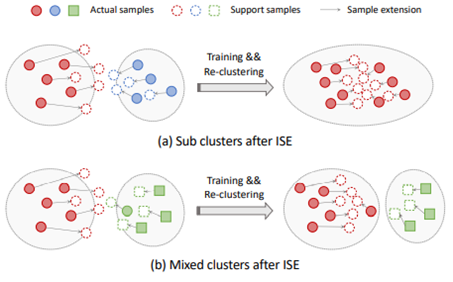
图. ISE方法说明
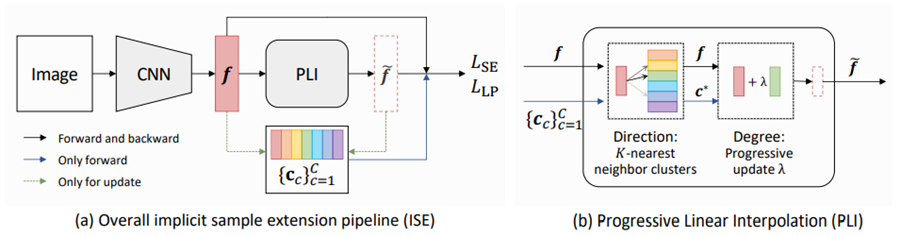
图. 模型结构示意图 作者:Xinyu Zhang, Dongdong Li, Zhigang Wang, Jian Wang, Errui Ding, Javen Qinfeng Shi, Zhaoxiang Zhang, Jingdong Wang
**08. **基于变分图信息瓶颈的子图识别方法
Improving Subgraph Recognition with Variational Graph Information Bottleneck 子图识别问题是指识别图结构数据中的与图属性有关的预测性子图。该问题是图神经网络可解释性分析、组织病理学分析以及鲁棒图分类等任务中的关键性问题。针对该问题,现有的方法通过优化图信息瓶颈目标函数来识别预测性子图。然而,由于互信息估计过程十分繁琐且难以准确估计,现有的方法训练耗时且不稳定,并极易得到退化解。因此,本文提出了变分图信息瓶颈方法。该方法首先引入噪声注入模块,对图数据中的节点依概率选择性注入噪声从而得到扰动图。通过比较扰动图与原始图预测结果的差别来衡量注入噪声节点的重要性。针对采样过程不可导,我们设计了基于重参数化技巧的噪声注入方法。通过引入噪声注入模块,我们将原始图信息瓶颈目标函数转化为变分图信息目标函数,并利用变分技巧得到了目标函数的变分上界。通过优化该变分上界求解图信息瓶颈问题,提高了优化过程的稳定性与速度。最后,将扰动图中的噪声节点去掉即得到了预测性子图。我们在多种视觉任务和图学习任务上测试了变分图信息瓶颈方法。实验结果表明该方法不仅易于优化,且在多种任务上取得很好的效果。
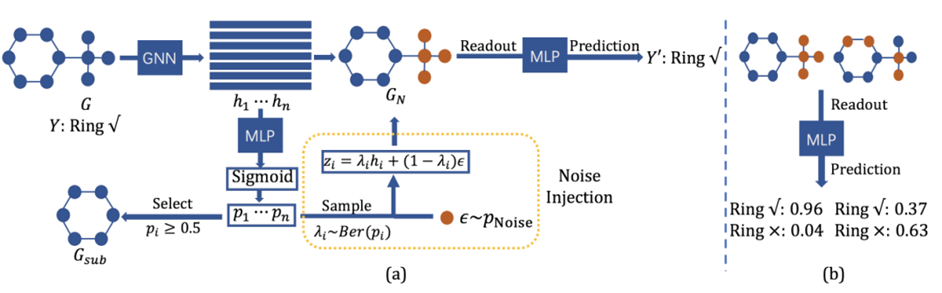
基于变分信息瓶颈的子图识别框架 作者:Junchi Yu, Jie Cao, Ran He
**09. **面向盲超分辨率的退化分布学习
Learning the Degradation Distribution for Blind Image Super-Resolution 当前的超分方法大多采用合成的成对的高清-低清样本来训练模型。为了避免合成数据与真实数据之间存在域差异,之前大部分方法采用可学习的退化模型去自适应地生成合成数据。这些降质模型通常是确定性的(deterministic),即一张高清图片只能用来合成一张低清样本。然而,真实场景中的退化方法通常是随机的,比如相机抖动造成的模糊和随机噪声。确定性的退化模型很难模拟真实退化方法的随机性。针对这一问题,本文提出一种概率(probabilistic)退化模型。该模型把退化当作随机变量进行研究,并通过学习从预定义的随机变量到退化方法的映射来建模其分布。和以往的确定性退化模型相比,我们的概率退化模型可以模拟更加多样的退化方法,从而生成更加丰富的高清-低清训练样本对,来帮助训练更加鲁棒的超分模型。在不同的数据集上的大量实验表明,我们的方法可以帮助超分模型在复杂降质环境中取得更好的结果。
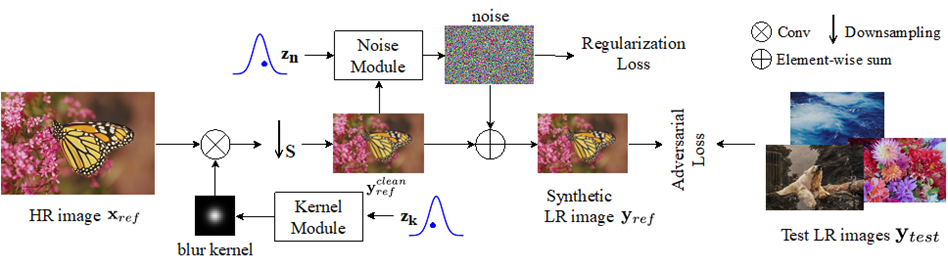
图. 基于概率退化模型的盲超分模型结构
作者:Zhengxiong Luo, Yan Huang, Shang Li, Liang Wang, Tieniu Tan
10. 一种基于Meta-Memory的跨域小样本语义分割方法
Remember the Difference: Cross-Domain Few-Shot Semantic Segmentation via Meta-Memory Transfer 小样本语义分割旨在通过使用少量标记数据来预测像素类别。现有小样本语义分割研究主要关注于在同一分布中采样基类和新类。然而,现实中数据分布并不能保证都在同一分布中,实际中显著存在的域偏移问题降低了小样本学习的性能。为了解决这个问题,我们引入了一个有趣且具有挑战性的跨域小样本语义分割任务,其中训练任务和测试任务在不同的域上执行。
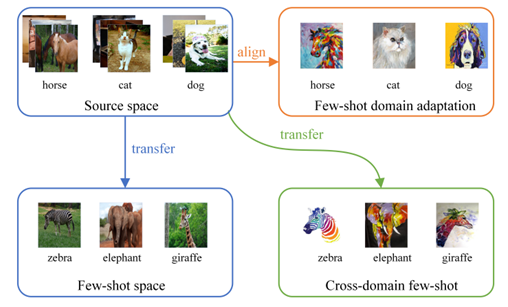
图. 跨域小样本学习 在学习过程中,我们使用一个元知识库来存储源域实例的域内样式信息并将它们传输到目标域样本,并且我们采用对比学习策略来约束迁移阶段新类的判别信息,由于源域信息的载入,目标域与源域的domain gap被有效降低。实验表明,我们提出的方法在4个数据集上的跨域少样本语义分割任务上取得了优异的性能。
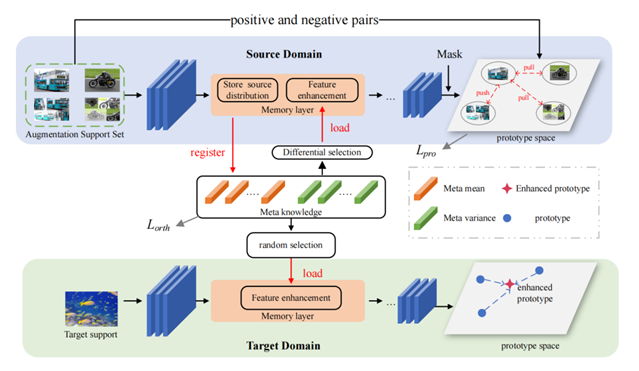
图. 模型结构设计 作者:Wenjian Wang, Lijuan Duan, Yuxi Wang, Qing En, Junsong Fan, Zhaoxiang Zhang
**11. **重新思考图像裁切:从全局视角探索多样化的构图
Rethinking Image Cropping: Exploring Diverse Compositions from Global Views
图像裁切是一种简单有效的可以提升图像构图美感的方式。现有的两类模型,候选裁切评估模型和裁切坐标回归模型,都有明显的缺陷。候选裁切评估模型难以遍历所有高质量裁切,无法满足全局性要求;而裁切坐标回归模型则只能输出一个裁切结果,忽视了多样性。针对全局性和多样性不能兼得的问题,我们提出了一种基于软标签集合预测的图像裁切模型。模型使用一组固定数量的可学习锚通过条件Transformer网络回归多个裁切。回归裁切与真实裁切进行二分图匹配,匹配结果用于训练一个辅助的有效性分类器,使模型可以从所有预测中挑选有效子集。为了缓解有效性分类硬标签与无效裁切的真实质量之间的不一致性,我们进一步提出了两种标签平滑策略。第一种基于裁切的局部冗余性对质量分数进行直接估计并映射为软标签;第二种使用自蒸馏策略进行自主平滑。两种策略分别适用于密集标注和稀疏标注的数据集。我们的模型在两个版本的GAIC数据集和FLMS数据集上均取得突出效果,同时克服了两类传统模型的缺陷,能够对图像进行全局遍历并找出多个高质量裁切。更加适用于真实场景的应用。
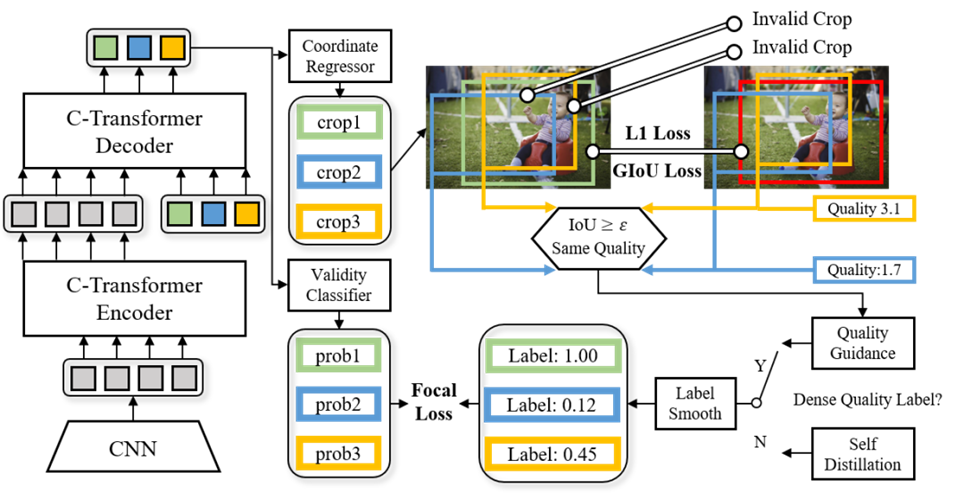
图. 基于软标签集合预测的图像裁切模型 作者:Gengyun Jia, Huaibo Huang, Chaoyou Fu, Ran He
**12. **自监督预测学习:一种用于视觉场景声源定位的无负样本方法
Self-Supervised Predictive Learning: A Negative-Free Method for Sound Source Localization in Visual Scenes 视觉和声音信号在物理世界常常相伴而生。一般而言,人可以“较为轻松地”将耳朵听到的声音和眼睛看到的物体一一对应起来,从而根据声音来定位发声物体。为实现这一类人行为智能,现有方法大多基于对比学习策略来构建图像和声音特征之间的对应关系。但这类方法均以随机采样的方式形成对比学习的负样本对,易引起不同模态特征之间的错误对齐,最终造成声源定位结果的混淆。 在本文中,我们提出了一种无需使用负样本的自监督学习方法,通过充分挖掘来自相同视频的视频帧图像和声音信号在特征水平上的相似性,来避免随机采样负样本引起的定位混淆问题。 为实现这一目的,我们首先设计了一个三分支深度网络,通过对同一视频帧图像进行数据增广,来构建声音特征与不同视角下的视觉特征之间的语义相关性;然后利用SimSiam式的自监督表示学习方法训练模型;最后,使用声音特征与视觉特征之间的相似性图确定声源位置。值得强调的是,提出的预测编码(Predictive Coding)模块有效实现了视觉模态和声音模态之间的特征对齐,有望拓展应用到其它多模态学习任务,如视觉-语言多模态。
在两个标准的声源定位数据集(SoundNet-Flickr和VGG-Sound Source)上进行的定量和定性实验表明,我们的方法在单声源定位任务上表现最优,证明了所提方法的有效性。
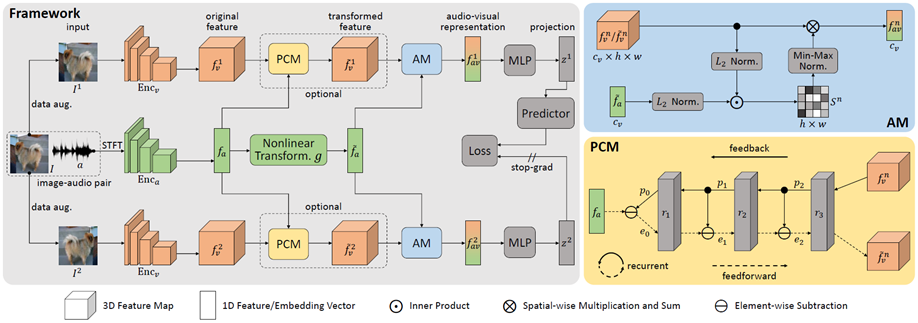
图. SSPL结构设计 作者:Zengjie Song, Yuxi Wang, Junsong Fan, Zhaoxiang Zhang, Tieniu Tan
**13. **基于稀疏实例激活的实时实例分割方法
Sparse Instance Activation for Real-Time Instance Segmentation 在本文中,我们提出了一种新颖、高效的全卷积实时实例分割框架。以前,大多数实例分割方法严重依赖目标检测并基于边界框或密集中心执行掩码预测。相比之下,我们提出了一组稀疏的实例激活图,作为新的对象表示,以突出每个前景对象的信息区域。然后根据高亮区域聚合特征得到实例级特征,进行识别和分割。此外,基于二分匹配,实例激活图可以以一对一的方式预测对象,从而避免后处理中的非极大值抑制(NMS)。由于具有实例激活图的简单而有效的设计,SparseInst 具有极快的推理速度,在 COCO 基准测试中达到了 40.2 FPS 和 36.9 AP,在速度和准确性方面明显优于现有方法。
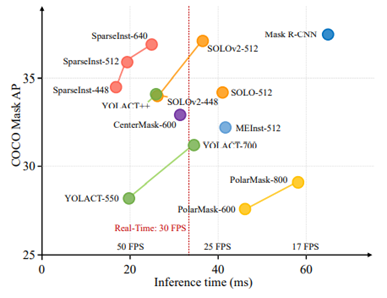
图. 在速度和精度上与现有实时实例分割算法的比较
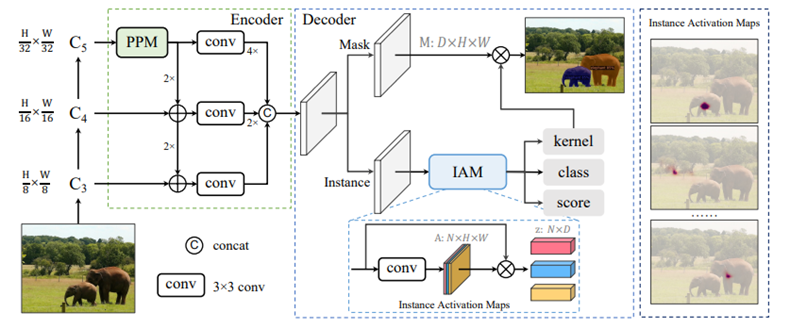
图. SparseInst框架结构 作者:Tianheng Cheng, Xinggang Wang, Shaoyu Chen, Wenqiang Zhang, Qian Zhang, Chang Huang, Zhaoxiang Zhang, Wenyu Liu
**14. **基于窗口注意力机制的深度图像压缩
The Devil Is in the Details: Window-based Attention for Image Compression 近年来,基于深度学习的图像压缩方法表现出比传统图像压缩方法具有更好的RD Performance。目前基于深度学习的图像压缩模型大都基于CNN。其主要缺点是CNN结构不是为捕捉局部细节而设计的,尤其是局部冗余信息,影响了重建质量。因此,如何充分利用全局结构和局部纹理成为基于深度学习图像压缩的核心问题。
受到ViT和 Swin的启发,我们发现将局部感知注意力机制与全局相关特征学习相结合可以满足图像压缩的预期。在本文中,我们首先广泛研究了多种注意力机制对局部特征学习的影响,然后介绍了一种更直接有效的基于窗口的局部注意力块。所提出的基于窗口的注意力非常灵活,可以作为即插即用组件来增强图像压缩模型。此外,本文提出了一种新颖的Symmetrical Transformer框架,是Transformer在图像压缩领域的第一次探索。
基于本文设计的Symmetrical Transformer框架和CNN框架在基于PSNR和MS-SSIM的量化指标上,均取得了新的SOTA性能。此外,在主观质量上,也有明显的改善。
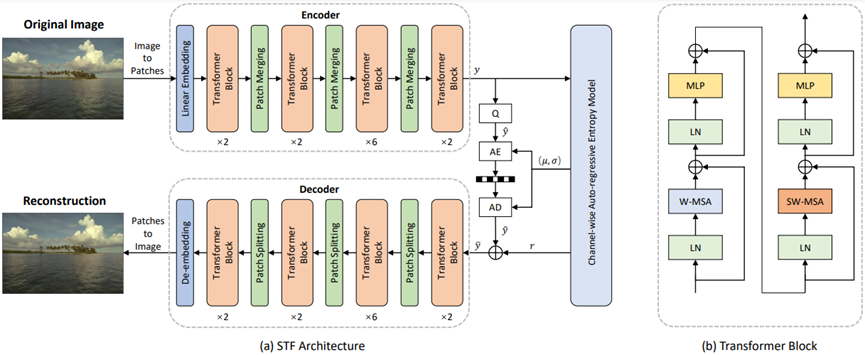
图. Symmetrical Transformer结构设计 作者:Renjie Zou, Chunfeng Song, Zhaoxiang Zhang 代码近期将开源:https://github.com/Googolxx/STF
**15. **可迁移稀疏对抗攻击
Transferable Sparse Adversarial Attack
研究对抗攻击对深度神经网络的鲁棒性评估具有重要意义。在本文中,我们关注基于零范数约束的稀疏对抗攻击,即修改图像的少量像素点造成模型的错误输出。已有稀疏对抗攻击尽管取得了较高的白盒攻击成功率,但由于过拟合目标模型,在黑盒攻击中可迁移性较差。我们引入了一种生成器框架来缓解过拟合问题,从而有效地生成可迁移的稀疏对抗样本。具体地,我们所设计的生成器将稀疏扰动解耦为幅值和位置,使用所设计的随机量化算子,以端到端的方式联合优化这两个分量。实验表明,与最先进的方法相比,我们的方法在相同的稀疏度下显著提高了可迁移性和计算速度。
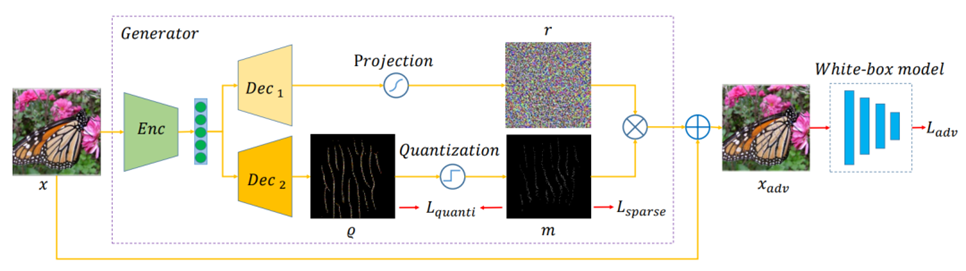
图. 可迁移稀疏对抗攻击框架 作者:Ziwen He, Wei Wang, Jing Dong, Tieniu Tan 代码已开源: https://github.com/shaguopohuaizhe/TSAA
**16. **基于低噪声物体轮廓的弱监督语义分割
Towards Noiseless Object Contours for Weakly Supervised Semantic Segmentation 得益于深度神经网络的迅速发展,语义分割研究在近年来取得了巨大进展。然而,生成像素级语义分割标签需要巨大的时间和经济投入。使用图像类别、物体框、物体划线、物体点标记等弱标签训练分割网络可以有效降低时间和经济成本。其中,图像类别标签成本最低,相关的弱监督分割研究最为活跃。这些方法通常会训练一个分类网络,基于分类网络的类激活图(CAM)生成分割伪标签L1,利用L1训练分割网络,这种伪标签通常不能覆盖完整的前景物体。一些方法利用伪标签L1训练模型预测物体轮廓,并在轮廓约束下将CAM分数从高置信度前景区域传播到低置信度前景区域,使生成的伪标签L2包含更完整的前景物体。我们认为伪标签L1缺乏足够的高层语义信息来监督轮廓检测网络,轮廓网络输出的噪声边界会阻碍CAM分数传播。为了得到低噪声物体轮廓,我们训练了SANCE模型,它包含一个辅助语义分割分支,该辅助分支通过主干网络特征共享和在线标签为轮廓检测分支训练提供足够的高层语义信息,辅助分支预测的分割结果也提供了比CAM更好的前景物体分布信息,进一步提高了伪标签质量。我们在Pascal VOC 2012 和COCO 2014数据集上进行了实验,伪标签训练的语义分割网络取得了SOTA性能。
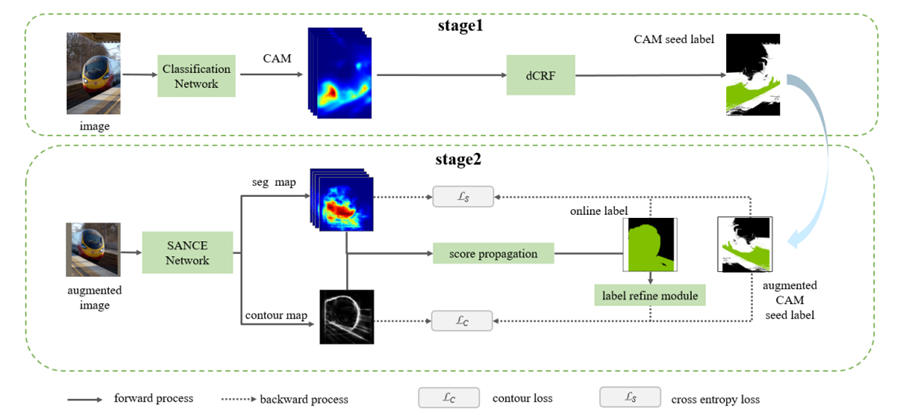
图. 模型结构设计 作者:Jing Li,Junsong Fan ,Zhaoxiang Zhang
**17. **基于代表性片段知识传播的弱监督时序行为定位
Weakly Supervised Temporal Action Localization via Representative Snippet Knowledge Propagation 弱监督时序行为定位的目的是仅通过视频类别定位出视频中的行为边界。现有的许多方法大多基于分类的框架,并试图生成伪标签以减小分类任务和定位任务之间的差异。现有的方法通常只利用有限的上下文信息来生成伪标签,导致生成的伪标签。为了解决这个问题,我们提出了一个提取出并传播代表性的片段的弱监督时序行为定位框架。我们的方法旨在挖掘每个视频中的代表性片段,以便在视频片段之间传播信息,以生成更好的伪标签。对于每个视频,我们的方法基于高斯混合模型生成其独有的代表性片段,并将代表性片段根据分数优先的原则储存在对应类别的记忆库中。在得到代表性片段后,我们的方法利用所提出的双向随机游走模块更新原始的视频特征,利用更新后的视频特征生成视频的伪标签,以在线的方式纠正主分支的预测结果。我们的方法在两个基准数据集THUMOS14和ActivityNet1.3上获得了优越的性能,在THUMOS14上的平均mAP高于最优方法1.2%。
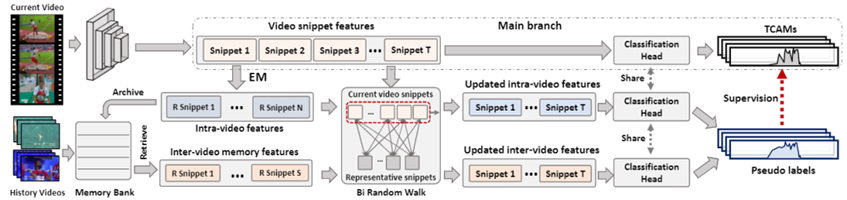
图. 代表性片段知识传递框架 作者:Linjiang Huang, Liang Wang, Hongsheng Li

