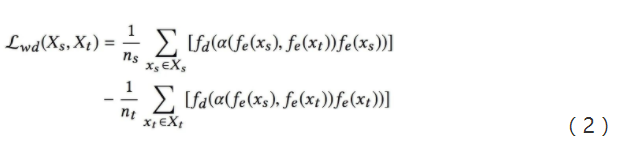近日,快手 Y-Tech 团队研发上线了国内首家端上单目三维手势技术,用户在手机上就能体验到流畅的三维手势技术和相关魔表效果。
历时一年多,快手研发人员在手部数据生成、数据真实化、网络定制化与轻量化、领域迁移等多个方面进行了大量探索,提出了领域特征自适应对齐和显式教师网络等方法,提高了跨域训练效果,降低了不合理手型概率,相关工作分别发表在 ACMMM 2020 和 BMVC 2020 上。
![]()
论文链接:https://dl.acm.org/doi/10.1145/3394171.3413651
![]()
论文链接:https://www.bmvc2020-conference.com/assets/papers/0242.pdf
效果展示:
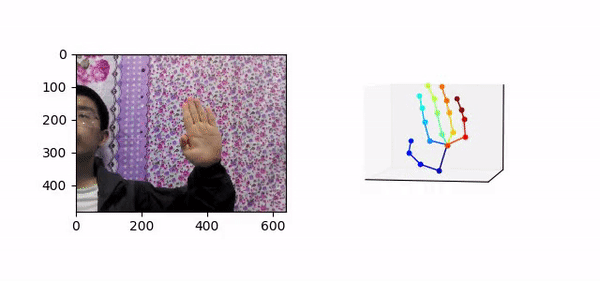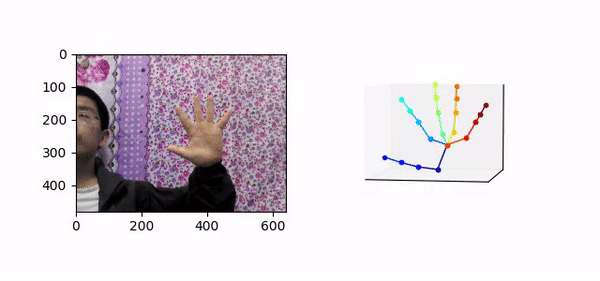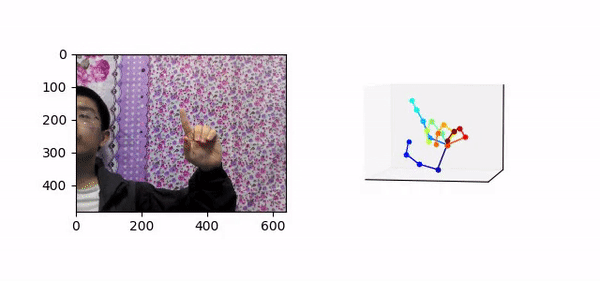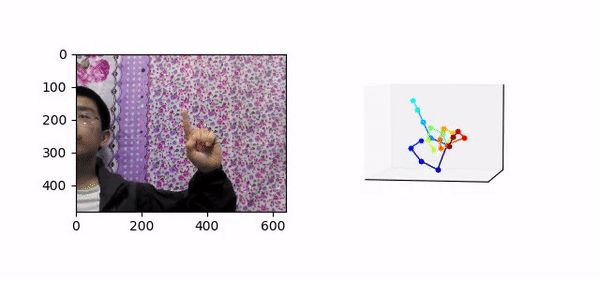
三维手势技术指的是输入包含人手的彩色图像,预测人手关键点在相机空间下的三维坐标,如图 1 所示。
![]()
该技术在虚拟现实、机器人控制以及体感游戏等领域有着广泛的应用前景,成为近年来的热点研究方向。但是三维手势识别,尤其是单目场景下,是一项极具挑战性的任务。受深度歧义性以及遮挡等因素的影响,三维手势数据的标注十分困难,这导致了三维手势训练数据的匮乏。基于这种场景单一和有限的手势数据进行训练,神经网络很难取得令人满意的效果。
一种解决方案是利用多摄像头系统采集不同角度的手部图片,然后使用三角化方法以自动或半自动的方式标注数据。然而该方案采集的图片背景比较单一,标注噪音也较大。另一种方案是使用计算机图像学(CG)方法生成虚拟手部数据。生成数据成本低廉、分布均匀可控、标注准确,能够作为真实数据集的补充引入到训练当中,结合数据真实化和领域迁移等方法能够有效提升手势识别的鲁棒性。
快手 Y-Tech 团队使用 CG 生成数据,结合提出的两种网络训练新方法有效缓解了训练数据不足和预测手型不合理现象,提升了预测的准确性。
自适应特征对齐方法提升跨域训练效果。现有方法大多采用生成数据与真实数据联合训练的方式,忽略了两者在图像和标注层面的差异,导致神经网络无法有效学习二者的共性特征。通过自适应学习领域共有特征和独有特征,该方法能有效提升生成数据在真实场景的泛化能力。
结合教师网络和人手物理约束提升预测手势合理性。训练数据不足时,神经网络无法充分挖掘数据集的高层次信息,导致预测手势中具有较多的不合理手型。针对这个问题,研究人员设计了一种显式教师网络来指导手势关键点预测模型,使输出符合人手物理约束。
近年来,许多研究者使用生成数据来缓解真实场景下的训练数据匮乏问题,显著提升了真实场景数据集下的三维手势预测准确率 [1,2],但是这些方法往往采用生成数据与真实数据联合训练的方式,忽略了二者的领域差异。
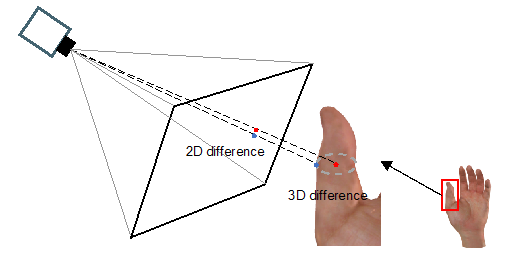
生成数据与真实数据的领域差异主要体现在两个方面:视觉差异与标注差异。由于人手的皮肤纹理非常复杂,现有的生成数据还无法模拟出完全真实的人手,如图 2 所示。同时由于标注机制的不同,生成数据可以使用人手骨骼作为标注点,而真实数据集往往只能以皮肤表面点为标注点,这导致二者的三维标注并不相同,如图 3 所示。
由于生成数据和真实数据的差异性无法避免,特征对齐或特征映射的难度较大,无法有效学习二者的共有特征,因而生成数据集的作用被弱化。
![]()
图 2:生成人手(左图)与真实人手(右图)的视觉差异
![]()
针对生成数据与真实数据存在的领域差异问题,早期研究人员利用数据集的先验知识,使生成数据与真实数据具有相似的预测结果。比如 Yujun Cai 等人 [3] 在三维人手姿态检测任务中约束生成数据与真实数据预测结果的相对深度范围。但是这种基于先验知识的约束只能限制生成数据与真实数据的输出满足预先设定的条件,并不能让网络自动挖掘两种数据集的共有特征,因此,一些学者开始研究显式的共有特征学习方法。
领域迁移 [4,5] 是学习不同数据集间共有特征的常用方法。这类方法通过拉近真实数据与生成数据的特征来提取二者的共有信息,并且在图像分割 [6]、姿态检测 [7]、图像分类 [8] 等领域得到广泛应用。虽然拉近二者特征能够提升生成数据的泛化能力,但是由于领域差异的存在,不加区分地拉近生成数据与真实数据的特征,会增加优化的难度,导致无法收敛或者无法得到满意的性能。因此,有必要对神经网络的特征进行区分,在拉近二者特征的同时,保留领域独有的特征,消除领域差异带来的影响。
基于这个思路,研究人员设计了自适应的特征对齐方法,让神经网络在训练过程中自适应地学习领域共有与领域独有特征,自动挖掘共有信息,同时降低生成数据与真实数据差异带来的优化困难问题。
![]()
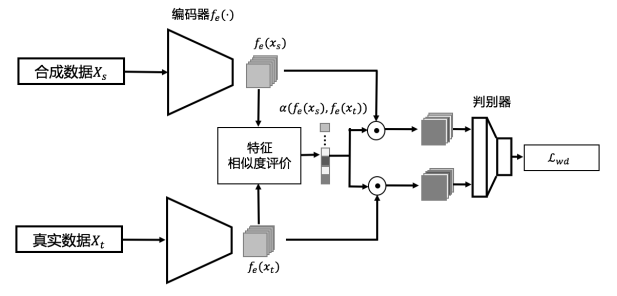
如图 4 所示,本研究在常见判别网络基础上引入了特征相似度评价指标,利用该指标实现共有特征和独有特征的自适应学习。由于每个通道的特征是由同一个卷积核计算得到,因此假定深度网络的特征每个通道代表一种含义。该特征相似度评价公式如公式(1)所示:
![]()
其中,
![]() 代表的是第 i 个通道的特征。
得到生成数据与真实数据特征逐通道的相似度后,将该相似度与原有特征相乘得到加权后的特征。通过判别器网络
代表的是第 i 个通道的特征。
得到生成数据与真实数据特征逐通道的相似度后,将该相似度与原有特征相乘得到加权后的特征。通过判别器网络
![]() 最小化新特征间的推土机距离,使生成数据和真实数据的共有特征尽可能相似。该过程的损失函数如公式(2)所示:
最小化新特征间的推土机距离,使生成数据和真实数据的共有特征尽可能相似。该过程的损失函数如公式(2)所示:
![]()
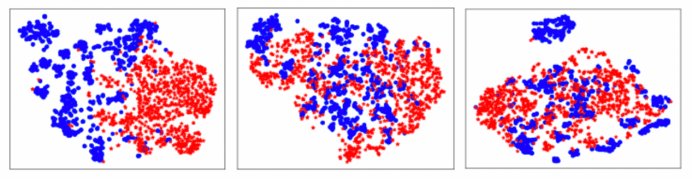
经过优化,权重大的特征在拉近后应该会更加接近,权重小的特征则会保持原有距离。使用 t-SNE [9] 对特征进行可视化,结果如图 5 所示,其中红色代表生成数据的特征,蓝色代表真实数据的特征。
![]()
图 5:直接联合训练、直接特征拉近训练和自适应特征对齐训练
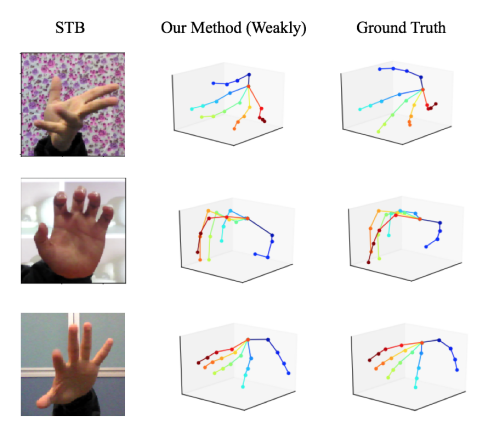
图 6 展示了该方法在 STB [10] 数据集上的可视化结果。虽然没有使用真实数据集的深度标注,但是仍然能够取得较为正确的预测结果。
![]()
在训练数据不充足的情况下,网络很容易输出不合理的手型,如图 7 所示:
![]()
一类 [11,12] 是借助人手模型将约束表示为人手模型的参数,通过限制这些参数的范围保证预测手势的合理性。但由于人手模型相比关键点是更高层次的抽象,因此需要较大的模型以及充足的训练数据才能获得令人满意的效果。
第二类 [13,14] 是在神经网络输出的关键点之后引入物理约束,通过损失函数让网络在训练中学会避免不合理手型。同样地,在数据量不足的情况下,该方法很容易对当前数据产生过拟合,影响模型泛化性。
针对这些问题,研究人员提出了基于显式教师网络的人手物理约束方法。该方法的设计思路借鉴了真实的教学过程。
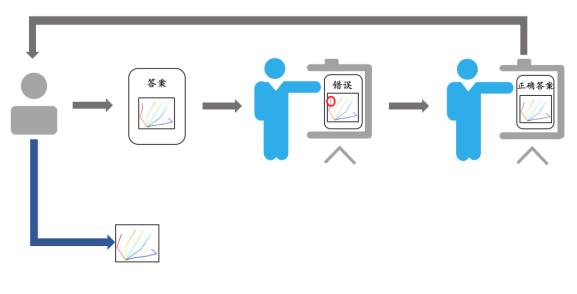
在现实中,老师往往通过发现学生行为的错误来指导学生学习某种知识。老师首先允许学生给出自己的答案,然后去评判答案,如果其中有错误,老师会给出正确方案。学生在接收到老师的反馈后,反思自己答案中的问题,并在之后的预测中避免类似的错误。该过程如图 8 所示。
![]()
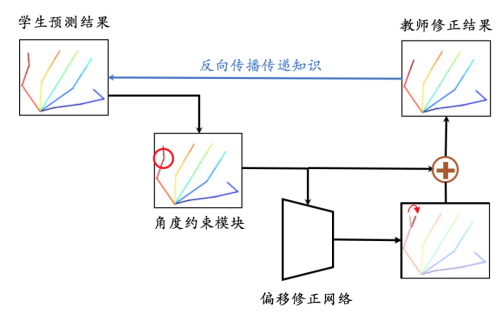
基于这个思想,研究人员设计了用于指导人手物理约束的教师网络。该网络包含两个部分:角度约束模块以及偏移修正网络,如图 9 所示。
![]()
角度约束模块通过关节点之间的角度是否满足预先设定的合理范围,来判断学生预测结果是否合理。当发现预测手势为不合理手型时,将该样本送入偏移修正网络进行修正,得到修正后的结果后再通过损失函数反向传播至学生网络,让学生网络在之后的预测中避免相似的错误。
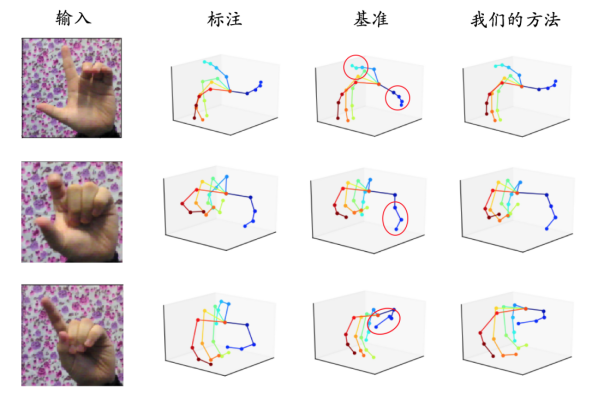
图 10 展示了使用该方法训练模型的手势预测结果和基准模型的结果,可以看到,使用显式教师模型训练的结果更倾向于输出满足人手物理约束的手势。
![]()
作为常用的自然交互方式之一,手势是近乎本能的一种表达方式,早在语言出现之前就已经是日常沟通的主要手段。在未来的数字时代,AR、VR 和 MR 等沉浸式场景将成为主流的数码和交互设备,而手势因其自然、非接触式特点,打破了现实和虚拟之间的鸿沟,无疑是未来设备标配技术之一。事实上,三维手势等手势识别技术已经广泛应用于虚拟现实、游戏等领域。然而,目前三维手势技术严重依赖于深度摄像头等专业设备,导致使用门槛过高,不适合普通用户使用。在快手,得益于自研的高效端上推理引擎 YCNN 和大量神经网络结构优化经验,三维手势能够中低端机型上实时运行,为数亿快手用户提供了新的交互方式,激发了用户的创作热情。
目前快手已经上线了 “指尖小怪物” 等魔表效果,也在打磨多款具有 3D 感知的特效。与此同时,该技术也将与快手混合现实 (MR) 技术结合起来,打造具有沉浸感的虚拟现实互动系统。
未来快手将进一步探索 CG 数据在神经网络训练中的领域迁移等技术,提升生成数据训练的效果。另一方面,该团队同时也在研发轻量级的手部 Mesh 重建技术,期待为用户提供更多的交互形式。
[1] Zimmermann C, Brox T. Learning to Estimate 3D Hand Pose from Single RGB Images[C]. IEEE international conference on computer vision. 2017.
[2] Cai Y, Ge L, Cai J, et al. 3D Hand Pose Estimation Using Synthetic Data and Weakly Labeled RGB Images[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020.
[3] Cai Y, Ge L, Cai J, et al. Weakly-supervised 3D Hand Pose Estimation from Monocular RGB Images[C]. European Conference on Computer Vision. 2018.
[4] Ganin Y, Lempitsky V. Unsupervised Domain Adaptation by Backpropagation. International Conference on Machine Learning. 2015.
[5] Ghifary M, Kleijn W B, Zhang M, et al. Deep Reconstruction-Classification Networks for Unsupervised Domain Adaptation. European Conference on Computer Vision. 2016.
[6] Zou Y, Yu Z, Vijaya Kumar B V K, et al. Unsupervised Domain Adaptation for Semantic Segmentation via Class-Balanced Self-Training. European Conference on Computer Vision. 2018.
[7] Baek S, Kim K I, Kim T K. Weakly-Supervised Domain Adaptation via GAN and Mesh Model for Estimating 3D Hand Poses Interacting Objects. IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020.
[8] Liu H, Long M, Wang J, et al. Transferable Adversarial Training: A General Approach to Adapting Deep Classifiers. International Conference on Machine Learning. 2019.
[9] Maaten L, Hinton G. Visualizing Data using T-SNE. Journal of Machine Learning Research, 2008.
[10] Zhang J, Jiao J, Chen M, et al. 3D Hand Pose Tracking and Estimation using Stereo Matching. IEEE International Conference on Image Processing. 2017.
[11] Zhou X, Wan Q, Zhang W, et al. Model-Based Deep Hand Pose Estimation. International Joint Conferences on Artificial Intelligence Organization. 2016.
[12] Zhang X, Li Q, Mo H, et al. End-to-end Hand Mesh Recovery from a Monocular RGB Image[C]. IEEE International Conference on Computer Vision. 2019.
[13] Sharma S, Huang S, Tao D. An End-to-end Framework for Unconstrained Monocular 3D Hand Pose Estimation. ArXiv 2019.
[14] Spurr A, Iqbal U, Molchanov P, et al. Weakly Supervised 3D Hand Pose Estimation via Biomechanical Constraints. European Conference on Computer Vision. 2020.
10月14日,AWS解决方案架构师贺浏璐将带来一场live coding,演示如何利用AWS云服务构建一个简单的数据管道从爬取、处理到分析视频内容。
识别二维码或点击阅读原文,立即预约直播。
![]()
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com



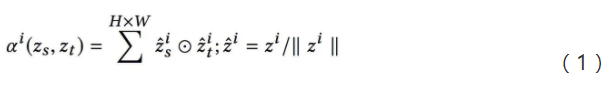
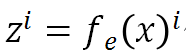 代表的是第 i 个通道的特征。
代表的是第 i 个通道的特征。
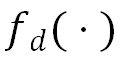 最小化新特征间的推土机距离,使生成数据和真实数据的共有特征尽可能相似。该过程的损失函数如公式(2)所示:
最小化新特征间的推土机距离,使生成数据和真实数据的共有特征尽可能相似。该过程的损失函数如公式(2)所示: