加入极市专业CV交流群,与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度 等名校名企视觉开发者互动交流!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。关注 极市平台 公众号 ,回复 加群,立刻申请入群~
光场相机可以记录当前场景不同视角的图像,每个视角图像的上下文信息(空间信息)与不同视角之间的互补信息(角度信息)都有助于提升图像超分辨的性能。
近日,来自国防科技大学、上海科技大学等单位的学者提出了新型光场图像超分辨算法(Spatial-Angular Interaction for Light Field Image Super-Resolution),通过交互光场图像的空间信息与角度信息提升了超分辨性能。
引言(Introduction)
光场(light field,LF)相机可以记录当前场景多个视角的图像,在重聚焦、深度估计、显著性检测、场景3D感知方面具有广泛应用。
然而受硬件条件限制,光场图像在空间分辨率(每个视角的图像分辨率)与角度分辨率(视角的采样密度)上存在制约关系。
该文针对光场图像超分辨问题开展研究,提升每个视角图像的空间分辨率。
作为底层视觉的一个关键任务,图像超分辨在近年来受到了广泛关注。对于单幅图像,超分辨算法需要充分利用低分辨率图像的上下文信息(空间信息)恢复高分辨率图像中对应的细节纹理。
对于光场图像,结合每个视角图像的空间信息与不同视角图像的互补信息(角度信息)可以提升超分辨的性能。然而由于光场图像的高维特性,充分利用并结合空间信息与角度信息非常具有挑战性。
该文提出光场“空间-角度”信息交互网络(LF-InterNet)实现光场图像超分辨:
首先,该文结合光场的结构特性提出空间特征提取子(spatial feature extractor,SFE)与角度特征提取子(angular feature extractor,AFE),分别用于提取光场图像的空间信息与角度信息。
而后,该文设计LF-InterNet对所提取的空间信息与角度信息进行渐进式交互融合。
该文在6个公开数据集上对所提算法进行了测试评估,实验结果表明LF-InterNet的性能达到了领域SOTA水平,同时具有较小的参数量与较高的运行效率。
方法(Method)
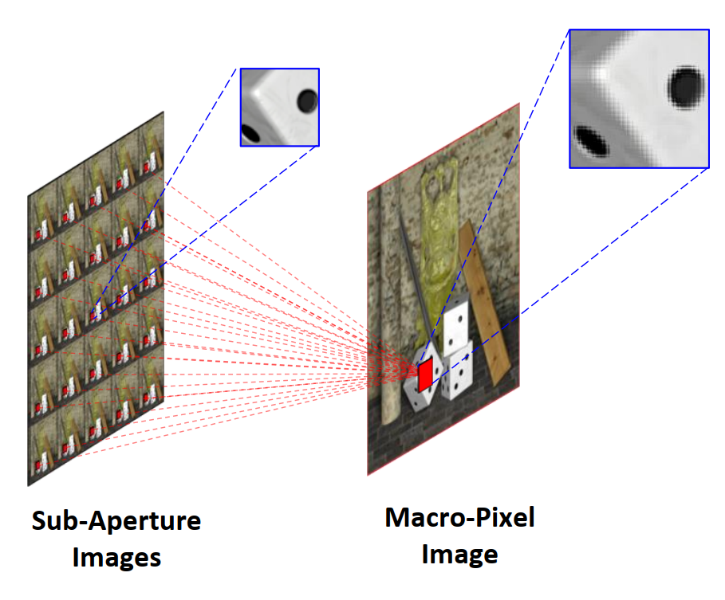
如图1所示,光场图像按照左图方式进行排列可以组成阵列子图像(sub-aperture image,SAI);若将每幅阵列子图像相同空间位置的像元按照视角顺序进行排列,则可以构成宏像元图像(macro-pixel image,MacPI)。该文所提SFE与AFE均以宏像元图像作为输入,如图2所示。
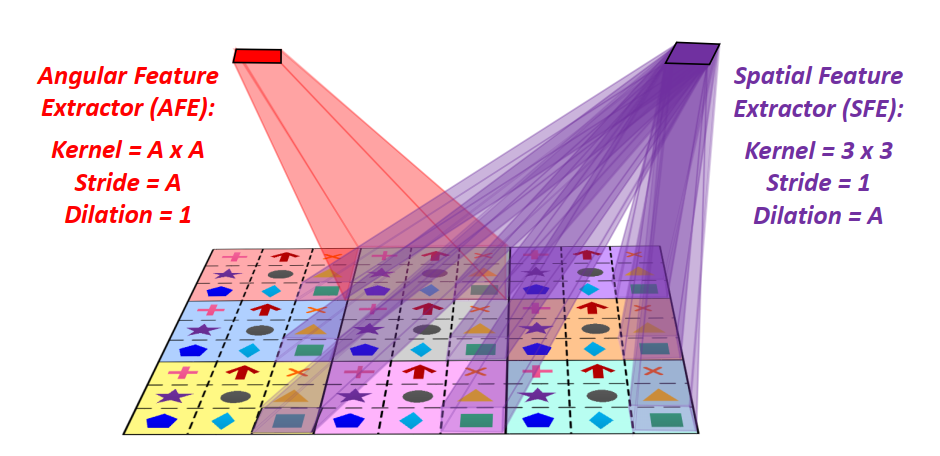
图2 空间特征提取子(SFE)与角度特征提取子(AFE)
图2为简化的光场宏像元图像示意图,其中光场的空间分辨率与角度分辨率均为3*3。图中涂有不同底色的3*3区域表示不同的宏像元,每个宏像元内的3*3像元标有不同的符号(十字、箭头等),表示其属于不同的视角。
AFE定义为kernel size=A*A,stride=A的卷积(其中A为光场的角度分辨率,图2中A=3);SFE定义为kernel size=3*3,stride=1,dilation=A的卷积。注意到,将AFE应用于宏像元图像时,只有单个宏像元内的像元参与卷积运算,而不同宏像元之间的信息不互通。
同理,将SFE应用于宏像元图像时,只有属于相同视角的像元参与卷积运算,而属于不同视角的像元不互通。因此,AFE和SFE可以分别提取光场的角度信息和空间信息,实现信息的解耦。
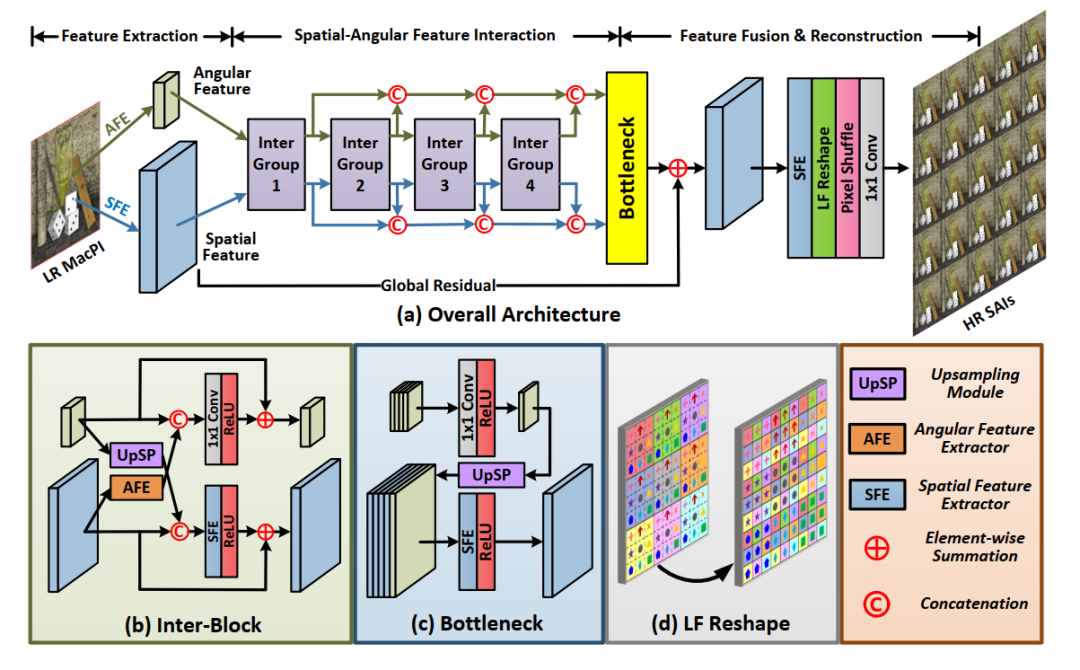
基于AFE与SFE,该文构建了LF-InterNet网络,如图3所示。假设光场图像的空间分辨率为H*W、角度分辨率为A*A,上采样系数为α,网络的输入为低分辨率光场宏像元图像(HA*WA),输出为高分辨率光场阵列子图像(αHA*αWA)。网络可以分为特征提取、空间角度特征交互、特征融合重建三个阶段。
(1)特征提取:将该文所提AFE与SFE应用于输入的光场宏像元图像,可以分别提取光场的角度特征(H*W)与空间特征(HA*WA);
(2)空间角度特征交互:用于实现空间角度特征交互的基本单元为交互块(Inter-Block)。该文将4个交互块级联构成交互组(Inter-Group),再将4个交互组级联构成网络的交互部分。如图3(b)所示,如图3(c)所示,在每个交互块中,输入的空间特征与角度特征进行一次信息交互。一方面,角度特征上采样A倍后与空间特征进行级联,而后通过一个SFE与ReLU实现角度信息引导的空间特征融合;另一方面,空间特征通过AFE卷积提取新一轮的角度特征,并与输入的角度特征进行级联,而后通过一个1*1卷积与ReLU进行角度特征的更新。空间特征分支与角度特征分支均采用局部残差连接。
(3)特征融合与重建:网络的每个交互组输出的空间特征与角度特征分别进行级联,而后通过bottleneck模块进行全局特征融合。如图3(c)所示,在bottleneck模块中,角度特征首先通过1*1卷积与ReLU进行通道压缩,而后通过上采样与空间特征进行级联。所级联的空间特征通过SFE与ReLU进行通道压缩,而后与初始提取的空间特征相加实现全局残差连接。融合所得到的特征通过SFE进行通道扩增,而后通过光场结构转换层(LF reshape,图3(d))将宏像元形式的特征重组为阵列子图像形式,最后通过pixel-shuffle层与1*1卷积层输出高分辨率光场阵列子图像。
该文采用表1所示的6个公开数据集进行训练与测试。网络训练采用L1 loss,评测指标采用峰值信噪比PSNR和结构相似度SSIM。除特殊说明外,输入光场的角度分辨率为5*5,LF-InterNet的通道数设为64,每个场景的评测数值为各视角子图像评测数值的均值,每个数据集的评测数值为该数据集下所有场景评测数值的均值。
实验(Experiments)
(1) 消融学习(Ablation Study):
实验部分首先通过消融学习对网络中不同模块和方案的有效性进行验证:
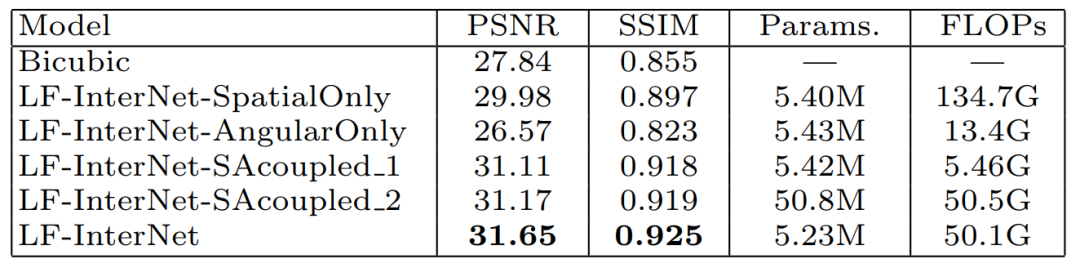
表2实验表明,空间信息与角度信息对超分辨性能均有增益,且该文所提SFE与AFE能够通过对空间信息与角度信息的解耦进一步的提升超分辨性能。
(2)算法对比(Comparison to the State-of-the-arts):
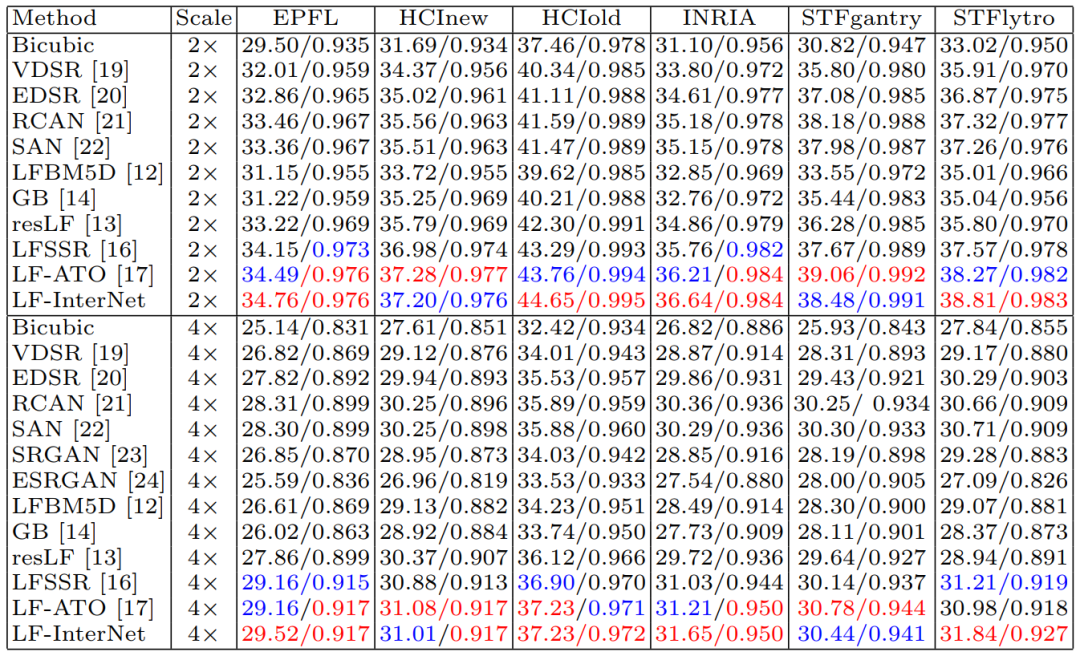
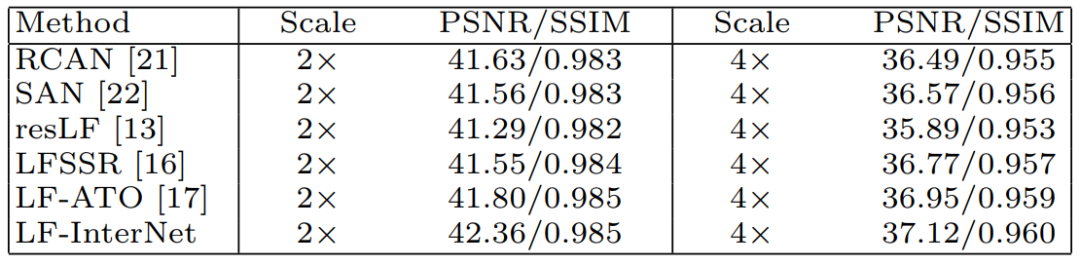
该文在表1所示的6个公开数据集上将LF-InterNet与单图超分辨算法VDSR(CVPR16)、EDSR(CVPRW17)、RCAN(ECCV18)、SAN(CVPR19)、SRGAN(CVPR17)、ESRGAN(ECCVW18)以及光场图像超分辨算法LFBM5D(ICIP18),GB(TIP2018),LFSSR(TIP18),resLF(CVPR19),以及LF-ATO(CVPR20)进行了比较,结果如下。
![]()
图4 不同超分辨算法视觉效果比较
值得一提的是,即使将LF-InterNet的通道数从64减少至32,网络仍然可以达到很好的性能,同时参数量与运算量显著降低。
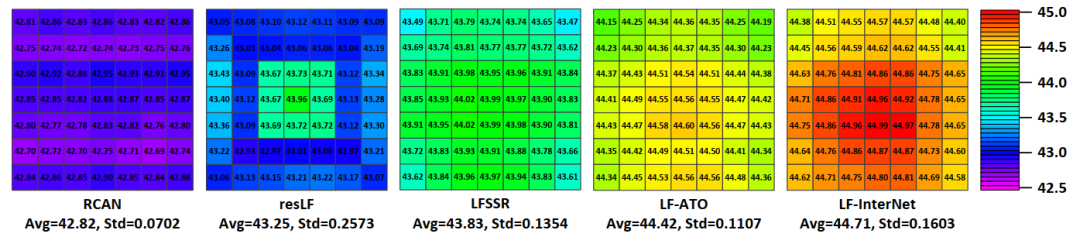
该文在表1所示的6个公开数据集之外的UCSD数据集上对不同算法的泛化性能进行测试。实验结果表明,LF-InterNet算法可以较好地泛化到其他数据集的新场景。
该文在STFlytro数据集原始分辨率的光场图像上对各个算法进行测试,视觉效果对比如图6所示。该文所提LF-InterNet算法在真实降质下可以取得较为理想的超分辨效果。
结论(Conclusion)
该文提出了空间-角度信息交互的光场图像超分辨网络(LF-InterNet),首先设计了空间特征提取子与角度特征提取子分别提取光场图像的空间与角度特征,而后构建LF-InterNet对两类特征进行渐进式交互融合。
实验验证了该文算法的有效性。LF-InterNet巧妙利用光场的结构特性,高效融合光场图像的空间信息与角度信息,解决光场图像空间分辨率与角度分辨率之间的矛盾。
https://arxiv.org/pdf/1912.07849.pdf
代码链接:
https://github.com/YingqianWang/LF-InterNet
推荐阅读
添加极市小助手微信(ID : cv-mart),备注:研究方向-姓名-学校/公司-城市(如:目标检测-小极-北大-深圳),即可申请加入极市技术交流群,更有每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、行业技术交流,一起来让思想之光照的更远吧~
![]()
△长按添加极市小助手
![]()
△长按关注极市平台,获取最新CV干货
觉得有用麻烦给个在看啦~ ![]()