【CVPR2022】任务相关解耦及可控伪样本生成的非生成式广义零样本模型
点击蓝字 关注我们
题目:Non-generative Generalized Zero-shot Learning via Task-correlated Disentanglement and Controllable Samples Synthesis
作 者:冯耀功,黄晓雯*,杨朋波,于剑,桑基韬
单 位:
北京交通大学 计算机与信息技术学院,
北京交通大学 交通数据分析与挖掘北京市重点实验室
邮 箱:
fengyg18@bjtu.edu.cn, pengboyang@bjtu.edu.cn, xwhuang@bjtu.edu.cn,
jianyu@bjtu.edu.cn,
jtsang@bjtu.edu.cn
论 文:https://arxiv.org/abs/2203.05335
*通讯作者
1. 背景
在广义零样本(Generalized Zero-shot Learning,GZSL)问题中,由于其可见类与不可见类的类别相互独立的特性,域偏移问题[1]是研究者面临的主要问题之一。而伪样本生成是目前提升模型在GZSL问题中的性能的最有效的方式。但是这类方式仍然存在以下两个问题:(1)特征混淆. 目前基于整体视觉特征(基于预训练好的CNN网络提取的2048D的高级特征)的GZSL模型中,其视觉特征所包含信息的丰富程度远大于属性语义特征,因此直接构建两者之间的映射并进一步合成伪样本并不符合人类一致认知,虽然有相关工作[2, 3]进行了视觉特征的解耦,但它们采用了生成式模型的方式,难以基于有限的可见类样本去保证有效的解耦和生成。(2)分布不明确. 已有GZSL模型尤其是生成式模型需要大量数据去拟合真实数据的分布,并且生成的伪样本分布是不明确的,这会导致在可见类样本数量有限时,模型表现不佳。
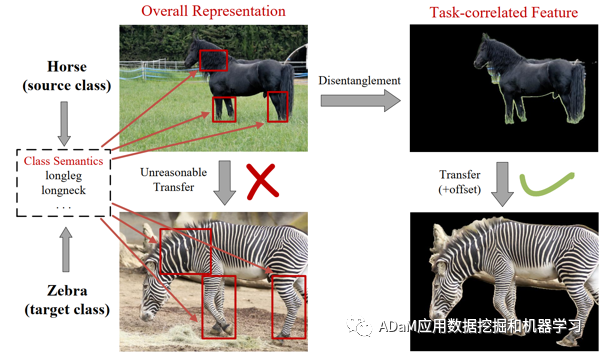
图1 方法核心思想
基于以上描述,我们提出了一种非生成式的任务相关解耦和可控伪样本合成模型(TDCSS)。TDCSS主要由两部分组成:(1)任务相关特征解耦模块. 我们根据视觉特征是否对应类语义,以非生成式的方式将整体特征解耦为任务相关特征和任务无关特征。(2)可控伪样本生成模块. 在任务相关特征的基础上,以非生成的方式合成两种类型的伪样本,即边缘伪样本和中心伪样本。这样既可以保证在不同任务场景下所生成伪样本的多样性,还有助于探索不同特性的伪样本在GZSL任务的知识迁移中所起到的作用。此外
,为了准确描述可见类样本数量受限的情景,我们还形式化了一种新的零样本学习场景“Few-shot Seen class and Zero-shot Unseen class learning”(FSZU)。因为在 GZSL任务中,可见类与不可见类之间具有很强的语义关系。因此我们认为ZSL和Few Shot Learning (FSL)共存的情况是合理的。在多个广泛使用的数据集的实验结果显示,我们的TDCSS模型在GZSL和FSZU任务中,均具备更好的性能。
2. 模型结构
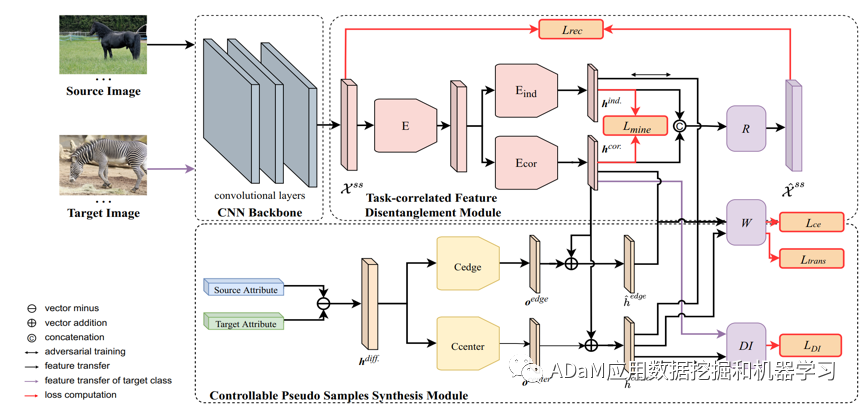
图2 TDCSS模型框架
在模型训练过程中,每个epoch被分为两个阶段的训练。在第一阶段,我们将可见类样本Xs分为源类Xss和目标类Xst。在第二阶段,我们将整个Xs视作源类,将不可见类样本Xu视作目标类。
2.1 任务相关特征解耦模块
这个模块由特征提取网络E、任务相关网络Ecor、任务无关网络Eind,重构网络R、以及线性映射W组成。我们使用基于域适应的对抗训练,将整体视觉特征解耦为任务相关特征hcor和任务无关特征hind。在对抗训练过程中,特征的分类损失是基于双线性兼容函数的交叉熵损失,而特征解耦的独立性和有效性分别使用互信息损失Lmine和重构损失Lrec来约束。
2.2 可控伪样本生成模块
这个模块由特征提取网络E、任务相关网络Ecor、线性映射W,中心变换网络Ccenter,边缘变换网络Cedge,以及域分类器网络DI组成。我们首先将目标类和源类的属性语义之差输入Ccenter和Cedge中分别生成中心偏移量Ocenter和边缘偏移量Oedge。然后与源类样本的hcor进行加和生成中心伪样本\hat{h}_center和边缘伪样本\hat{h}_edge。其中,我们使用域对抗损失LDI以及使用迁移损失Ltrans(该损失基于源类和目标类之间的属性语义相似性软标签构成)来对\hat{h}_center进行约束,使其分布更靠近类中心。对于\hat{h}_edge,我们将其视为特征级别的对抗样本,其中Oedge可以看作是对抗样本中的扰动,因此我们引入了对抗自监督的训练方式来进一步增强模型的鲁棒性和泛化性。
训练完成后,我们使用训练好的E、Ecor和W进行样本的分类操作。
3. 实验
实验采用了四个广泛使用的零样本图像分类数据集AWA1,AWA2,CUB和FLO。
3.1 GZSL任务
表1给出了TDCSS模型与主流方法在GZSL任务中效果对比。如表1所示,TDCSS模型不论是与非生成式模型还是与生成式模型相比,均达到了较好的效果。尤其是与AREN[4]模型相比,TDCSS模型既不依赖Calibrated Stacking (CS)[5]的后处理操作,也没有使用张量级别的特征映射,其GZSL任务性能仍然较为优秀。
表1 GZSL任务准确率
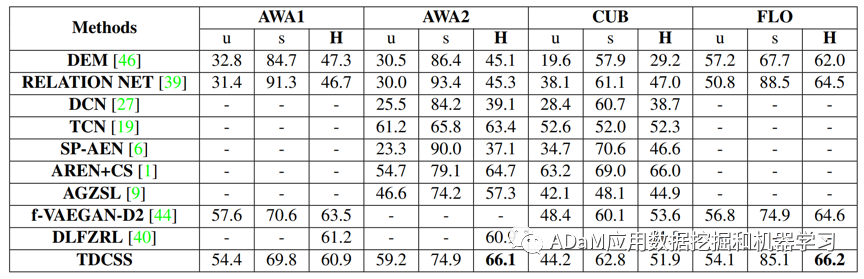
表2给出了TDCSS模型各个模块的消融实验。TDCSS主要由三个模块组成:特征解耦模块(TFD),边缘伪样本生成模块(EPS),中心伪样本生成模块(CPS)。从表2可以看出,特征解耦有助于提升模型在GZSL任务中的知识迁移能力;边缘伪样本有助于提升模型的鲁棒性和泛化性;中心伪样本在从可见类到不可见类的知识迁移过程中起到了主要作用。
表2 消融实验
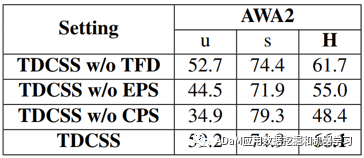
图3和4为模型的定性和定量分析,分别给出了TDCSS模型特征解耦和伪样本生成的可视化效果。这些可视化的实验结果均证明了TDCSS模型能够进行有效的解耦和生成。

图3 任务相关特征的可视化

图4 (a)和(b)为任务相关特征和任务无关特征的分布, (c)和(d)为不同类型的伪样本的分布
3.2 FSZU任务
表3给出了TDCSS模型与同类模型在FSZU任务中的效果对比。我们将每个可见类的样本数量分别限定为10、5、3来模拟FSZU任务。其中,Disentangled-VAE[2]和SDGZSL[3]模型进行了特征的解耦,AGZSL[6]作为一个非生成式模型进行了伪样本的合成。从表3可以看出,TDCSS模型在FSZU任务中依然保持了很好的性能,证明了TDCSS模型构建策略的合理性。
表3 FSZU任务准确率
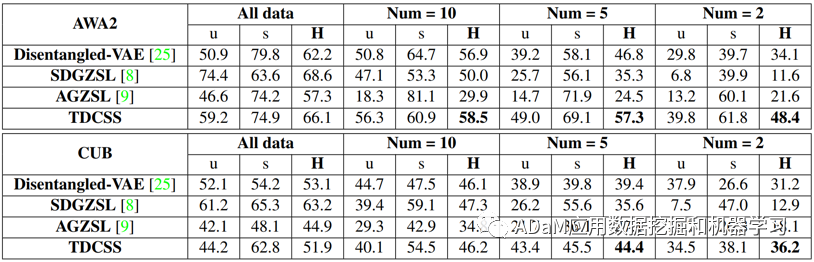
图5给出了TDCSS模型训练过程中的目标类数量影响。在FSZU任务中,我们可以通过提升目标类的数量来增加目标类的样本数量,进而提升模型的效果。从图5中可以看出,在一定范围内,模型性能有一定的提升,但是过多的目标类会导致过量的伪样本生成,进而干扰模型的正常学习导致任务性能下降。
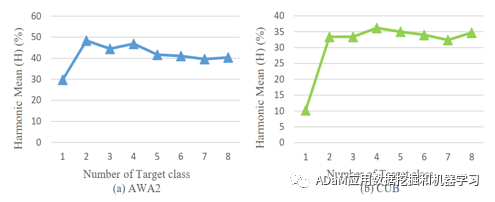
图5 参数敏感分析
4. 结论
本文提出了一种非生成式的任务相关解耦和可控伪样本合成模型TDCSS以及一种新的任务场景FSZU。前者提供了一种全新的非生成式的特征解耦和伪样本生成方法,使得模型在零样本任务场景下的知识迁移过程更加直观。后者进一步完善了目前零样本图像分类领域的任务场景。实验证明,TDCSS模型的性能是具备竞争力的。
参考文献
[1] Fu Z, Xiang T, Kodirov E, et al. Zero-shot learning on semantic class prototype graph[J]. IEEE transactions on pattern analysis and machine intelligence, 2017, 40(8): 2009-2022.
[2] Li X, Xu Z, Wei K, et al. Generalized zero-shot learning via disentangled representation[C]//Proceedings of the AAAI Conference on Artificial Intelligence. 2021, 35(3): 1966-1974.
[3] Chen Z, Luo Y, Qiu R, et al. Semantics disentangling for generalized zero-shot learning[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021: 8712-8720.
[4] Xie G S, Liu L, Jin X, et al. Attentive region embedding network for zero-shot learning[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2019: 9384-9393.
[5] Chao W L, Changpinyo S, Gong B, et al. An empirical study and analysis of generalized zero-shot learning for object recognition in the wild[C]//European conference on computer vision. Springer, Cham, 2016: 52-68.
Chou Y Y, Lin H T, Liu T L. Adaptive and generative zero-shot learning[C]//International Conference on Learning Representations. 2020.
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“GZSL” 就可以获取《【CVPR2022】任务相关解耦及可控伪样本生成的非生成式广义零样本模型》专知下载链接




