强化学习:Policy-based方法 Part 1
【导读】在前面两篇文章中,我们完成了基于值的(value-based)强化学习算法,可以在给定的环境下选择相应动作,并根据最高的Q-value来确定下一步的动作(最大化未来奖励期望)。可以看到,策略主要来源于对动作价值的估计过程。
作者:Thomas Simonini
编译:专知
整理:Yongxi
本次,我们将学习一种被称为策略梯度(Policy Gradients)的基于策略的(policy-based)强化学习技术。Part1部分,我们将着重讨论基于值方法的局限性,以及基于策略方法的优势。在part2部分中,我们将具体介绍基于策略方法的实现过程,届时我们将实现两个agent,第一个将学习如何保持木棍的平衡;
第二个将学习如何在Doom的敌对环境中,通过收集体力生存下去。
在policy-based方法中,实际上并没有学习到一个值函数,来帮助我们了解某一状态下各动作的奖励是多少。而是直接学习策略函数,将状态映射为动作。
这意味着我们将直接尝试优化策略函数π,而不需要考虑值函数。当然,仍然可以使用值函数去优化策略参数,但值函数将不会用于动作的选择过程。
在本文章中,你将学到:
Part1:什么是策略梯度,以及优势、劣势是什么
Part2:如何在Tensorflow中实现它
为什么使用基于策略的方法?
两种策略:确定的与随机的。确定策略将状态映射为动作。输入一个状态,函数将返回一个动作。
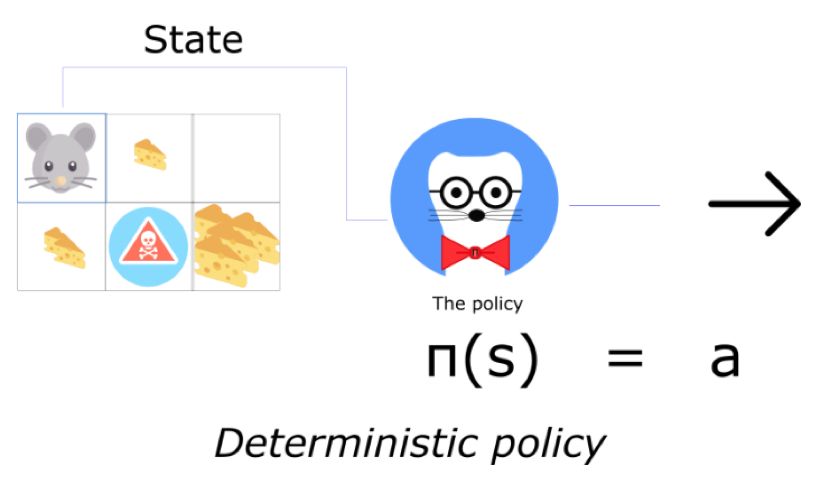
确定策略被用于确定的环境中。这些环境中,所选择的动作决定了结果。一切都是确定性的。例如,当你玩国际象棋游戏,并且将士兵从A2移动到A3,可以预期到,士兵一定会移动到A3的。
而另一方面,一个随机策略会输出一个动作上的可能性分布。
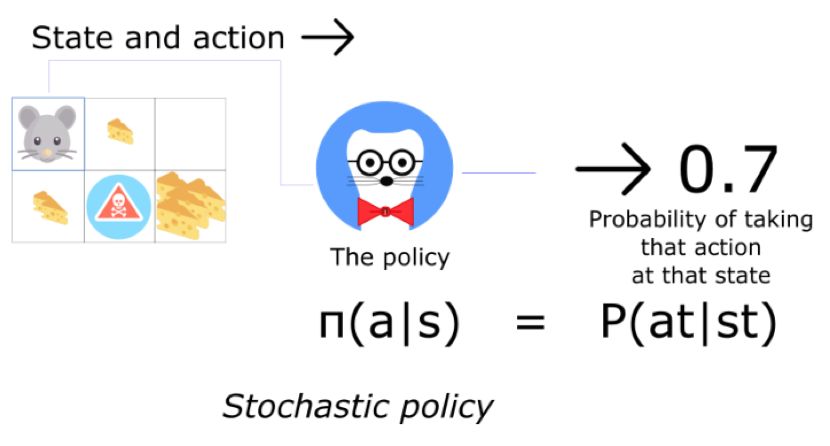
这意味着与确定动作不同,有一定的可能采取一个相反的动作(在这个案例中,有30%的概率朝南走)。这个随机的策略将使用在不确定的环境中。我们称这种过程为部分可观测的马尔可夫过程(Partially Observable Markov Decision Process,POMDP)。大多数时间,我们使用第二种策略。
三个主要优势
趋同性(Convergence):
基于策略的方法有更好的趋同特点。基于值的方法在训练时可能产生非常大的波动。这是由于动作估计价值的微小变化,也有可能对动作选择产生极大影响。
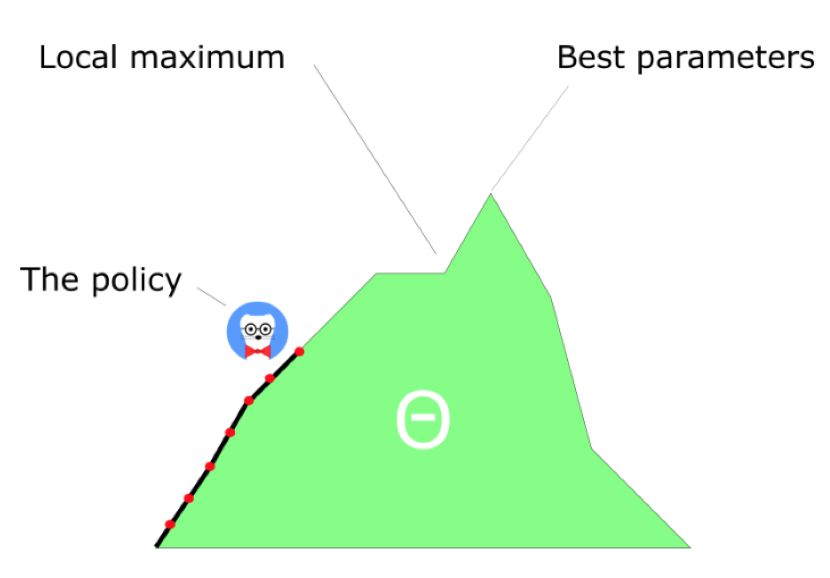
另一方面,策略梯度中,仅仅跟随梯度去寻找最好的参数值,可以看到每一步的更新过程都非常平滑。由于我们跟随梯度寻找参数,所以可以保证找到局部最优解(不好的结果)或全局最优解(好的结果)。
策略梯度在高维动作空间内更加高效:
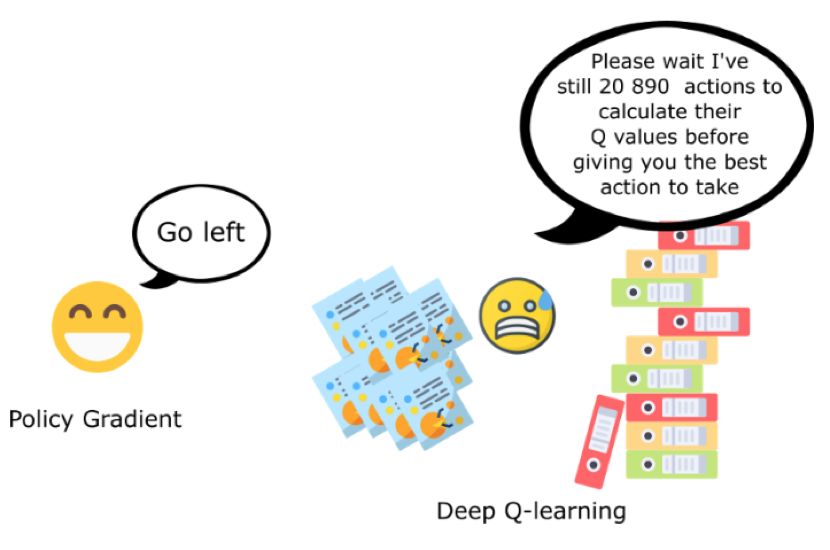
第二个优势是策略梯度在高维动作空间中,或存在连续动作时更加的高效。
深度Q学习的问题是,模型为每一种可能的动作,每一个时间步,每一种给定的状态都计算了一个分数(最大未来期望)。但如果动作空间是无限的怎么办?
例如,在自动驾驶中,每一个状态都有接近无限的可选动作(轮子角度旋转15°、17.2°、按喇叭。。。),我们需要为每一个行为输出一个Q值。
另一方面,基于策略的方法中,仅直接调整参数,以帮助模型理解什么是最大化,而不是在每一步计算(估算)最大值。
策略梯度算法可以学习到随机策略
第三个优势是策略梯度可以学到随机策略,而值函数无法学习,这有两个推论:
第一个是我们不需要实现探索与开发(exploration/exploitation)的平衡。随机策略允许我们的agent不依赖于相同动作探索状态空间。这是由于输出是一个动作的可能分布情况,这一点可以很轻松的通过代码来实现。
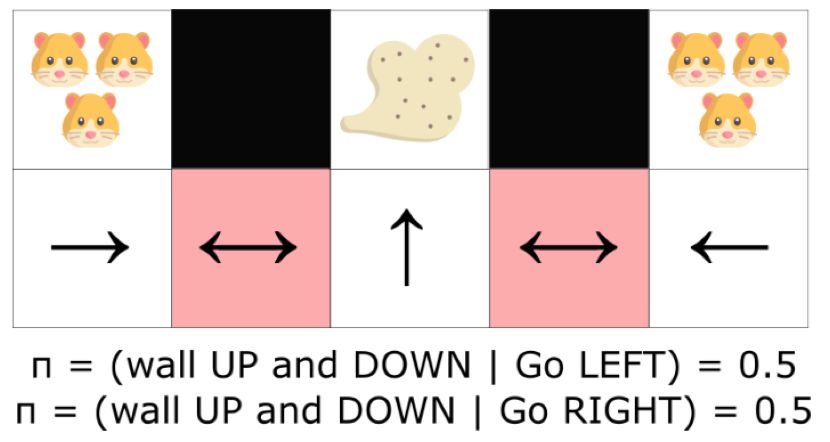
我们也可以摆脱掉感知混淆(perceptualaliasing)的问题。感知混淆是说当我们有两个状态,看起来非常像,但却需要采取不同动作时的情况。
例子如下,我们有一个扫地机器人,目标是打扫灰尘并避免杀死仓鼠。
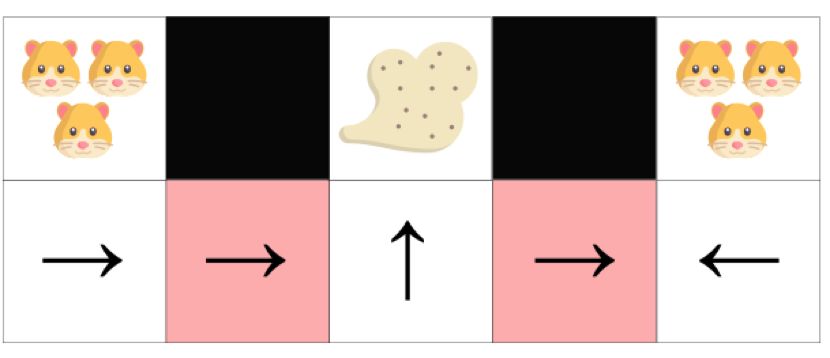
在基于值的RL算法中,我们学习一个准确定性模型(epsilon贪婪策略),这样做的话,agent可能需要很长时间才能找到目标灰尘。
另一方面,一个最优化随机策略将随机向左或向右移动,这将使得agent有很高的概率快速到达目标状态。
劣势:
策略梯度有一个很大的劣势,很多次,它们收敛于局部最优解,而不像是深度Q学习,总是尝试到达全局最优解。
不过,对于这些劣势有一些可选的解决方案。具体的实现方法,将在后续的Part2部分:如何在Tensorflow中实现它,进行详细讲解,敬请期待。
原文链接:
https://medium.freecodecamp.org/an-introduction-to-policy-gradients-with-cartpole-and-doom-495b5ef2207f
-END-
专 · 知
人工智能领域主题知识资料查看与加入专知人工智能服务群:
【专知AI服务计划】专知AI知识技术服务会员群加入与人工智能领域26个主题知识资料全集获取。欢迎微信扫一扫加入专知人工智能知识星球群,获取专业知识教程视频资料和与专家交流咨询!

请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请加专知小助手微信(扫一扫如下二维码添加),加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等)交流~

请关注专知公众号,获取人工智能的专业知识!
点击“阅读原文”,使用专知

