uDepth:Pixel 4 上的实时 3D 深度传感
文 / uDepth 软件负责人 Michael Schoenberg 和 uDepth 硬件/系统负责人 Adarsh Kowdle,Google Research

确定场景 3D 信息的能力称为 深度传感 (Depth Sensing),对于开发者和用户而言,这是一种颇具价值的工具。
深度传感是计算机视觉研究中的一个非常活跃领域,近年来实现了大量创新成果,包括人像模式和 AR 等应用,以及透明物体检测等基础传感创新技术。传统的立体深度传感技术基于 RGB,计算成本往往十分高昂,并且在低纹理区域时会受到影响,而在光照极低的条件下会完全失效。
AR
https://developers.googleblog.com/2019/12/blending-realities-with-arcore-depth-api.html
由于 Pixel 4 上的面部解锁功能必须执行快速且支持黑暗环境,因此需要采取不同的解决方案。为此,我们在 Pixel 4 的正面加入了实时红外 (IR) 主动立体深度传感器 uDepth。这项技术是 Pixel 4 的一项关键计算机视觉功能,可帮助身份验证系统识别用户身份,同时防止欺骗攻击。另外,此技术还支持多种新功能,如照片后期调整、基于深度的场景分割、背景虚化、人像效果和 3D 照片等。
面部解锁
https://support.google.com/pixelphone/answer/9517039
最近,我们通过 Camera2 API 提供 uDepth 的访问权限,使用 Pixel Neural Core、两个红外摄像头和一个红外模式投影器并按 30Hz 提供时间同步的深度帧(在 DEPTH16 中)。借助此 API,Pixel 4上的 Google 相机应用可以优化自拍深度功能。在这篇文章中,我们将简述 uDepth 的工作原理,详述底层算法,并探讨 Piexl 4 示例结果的相关应用。
Camera2 API
https://developer.android.com/reference/android/hardware/camera2/package-summaryDEPTH16
https://developer.android.com/reference/android/graphics/ImageFormat.html#DEPTH16自拍深度功能
https://www.blog.google/products/pixel/more-pixel-features-dropping
立体深度传感概述
所有立体摄像头系统均使用 视差 来重建深度。如要观察视差效果,您可以注视一个对象,先闭上一只眼睛,然后睁开,再闭上另一只眼。您会发现对象的位置出现移动,而越靠近的对象看起来移动得更多。uDepth 是 Dense Local Stereo 匹配技术体系的一部分,通过计算来估计每个像素的视差。这些技术会在一个摄像头生成的图像中评估每个像素的周围区域,并尝试在第二个摄像头生成的相应图像中找到相似区域。经正确校准后,生成的重建结果属于 可度量指标,表示实际的物理距离。

主动立体系统示例:Pixel 4 前置传感器设置
为解决无纹理区域的感测问题并适应弱光条件,我们采用“主动立体”设置,将红外模式投射到由立体红外摄像头检测到的场景中。这种方法使得低纹理区域更易识别,从而优化了识别效果并减少了系统的计算量。
uDepth 与众不同之处
立体传感系统的计算量可能非常庞大,因此,对于以 30Hz 频率运行的传感器来说,必须要在保持高质量的同时实现低功耗。而 uDepth 利用多种关键特性实现了这一目标。
其中之一是,在给定一对相似区域的情况下,这些区域的大多数对应子集同样相似。例如,给定两个相似的 8×8 像素块,则每个像素块左上角的 4×4 子区域很可能也相似。这些信息将传达至 uDepth 流水线的初始化程序,该程序会比较每个图像内的非重叠像素块并选择其中最相似的像素块,从而构建深度建议金字塔。此过程从 1×1 像素块开始,并按层累积支持,直到生成初始的低分辨率深度图。
初始化完成后,我们应用一种全新的 神经网络深度细化 技术来支持 Pixel 4 上的规则网格模式照明器。一般的主动立体系统会投射伪随机网格模式来帮助消除场景中的匹配歧义,而 uDepth 还能够支持重复的网格模式。重复结构产生的区域在立体对中看起来十分相似,并可能导致不正确的匹配。针对这个问题,我们采用轻量级(7.5 万个参数)的卷积架构,通过红外亮度和邻近信息来调整不正确的匹配,而每帧耗时不到 1.5 毫秒。
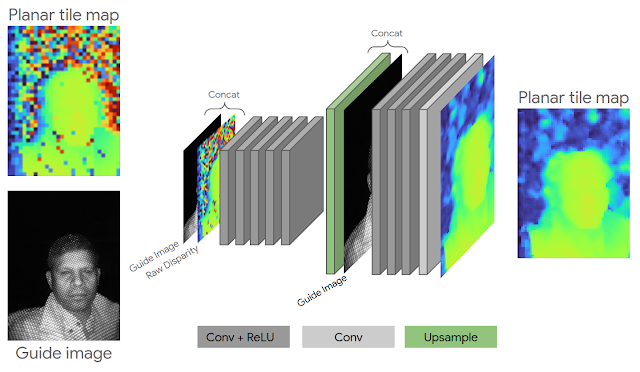
神经网络深度细化架构
在完成神经网络深度细化后,合适的深度估计值将从相邻的像素块开始迭代传播。这个及后续的流水线步骤均利用了造就 uDepth 成功的另一项关键见解——自然场景通常是局部平面,只存在少量的非平面偏差。这让我们能够找到覆盖场景的平面像素块,然后只针对一个像素块中的每个像素细化单个深度,从而大幅减少计算量。
最后,如果找不到理想的匹配,则从相邻平面假设中选出最佳匹配,并进行子像素细化和无效化处理。

简化的深度架构:绿色组件在 GPU 上运行,黄色组件在 CPU 上运行,而蓝色组件在 Pixel Neural Core 上运行
当手机严重跌落后,可能会导致立体摄像头的出厂校准设置 偏离 其实际位置。为了在实际使用中确保高质量的结果,uDepth 系统还支持自校准功能。计分例程评估每个深度图像是否存在误校准的迹象,并建立对设备状态的置信度。如果检测到校准错误,则从当前场景重新生成校准参数。此过程遵循包含特征检测与对应、子像素细化(利用点轮廓)和光束平差的流水线。
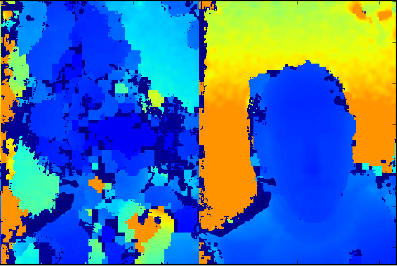
左:不准确校准的立体深度;右:自动校准后的效果
如需了解更多详情,请参阅 uDepth 的构建基础 Slanted O(1) Stereo。
Slanted O(1) Stereo
https://ieeexplore.ieee.org/abstract/document/8593800
计算摄影的深度
uDepth 传感器的原始数据必须准确且可度量,这是面部解锁的基本要求。诸如人像模式和 3D 照片等计算摄影应用则有着大相径庭的需求。在这些用例中,实现视频帧率并不重要,但深度应当平滑、边缘对齐,且在彩色摄像头的整个视场中保持完整。

从左到右:原始深度传感结果,预测深度,3D 照片。请注意墙的平滑旋转,这展示了连续的深度梯度,而不是单个焦平面
为实现这一目标,我们训练了一个端到端的深度学习架构,此架构可增强原始 uDepth 数据,从而推断出完整且密集的 3D 深度图。我们采用 RGB 图像、人像分割和原始深度的组合,并采用 Dropout 方案强制使用每个输入的信息。
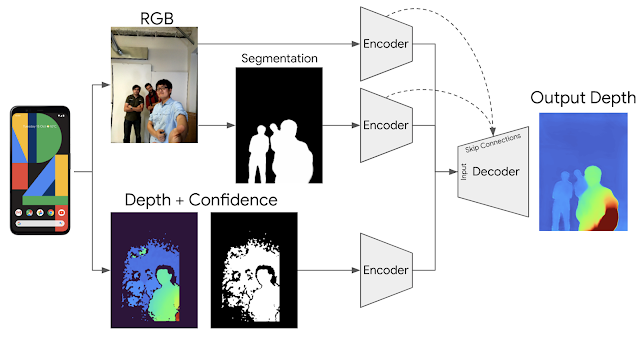
用于计算摄影深度增强的架构
为获取实况数据,我们采用了容积拍摄系统,通过配备 331 个自定义彩色 LED 灯、一系列高分辨率摄像头和一组自定义高分辨率深度传感器的测地线球体来生成接近照片真实感的人像模型。我们在设置中添加了多部 Pixel 4 手机,并将它们与其他硬件(灯光和摄像头)进行同步。由此生成的训练数据既包括 Pixel 4 摄像头视点的真实图像,也包括合成的渲染图像。
容积拍摄系统
https://augmentedperception.github.io/therelightables/

数据获取概览
全面整合
当所有组件整合就绪后,uDepth 既能以 30Hz 的频率产生深度数据流(通过 Camera2 开放访问权限),也能生成平滑的摄影后处理深度图(在启用深度自拍功能时,通过 Google 相机应用开放访问权限)。系统生成的平滑、密集、每像素深度支持启用 Social Media Depth 功能的所有 Pixel 4 自拍照片,并且可用于社交媒体的散焦和 3D 照片等后期捕获效果。


应用示例,请注意观察右侧 3D 照片上的多个焦平面
最后,我们很高兴为您提供一个演示应用,方便您使用 uDepth 提供的实时点云可视化工具进行体验(此应用仅用于演示和研究目的,不用于商业用途;Google 不提供任何支持或更新)。这一演示应用将通过您的 Pixel 4 设备对 3D 点云进行可视化。由于深度图是时间同步的,并且与 RGB 图像位于同一坐标系中,因此可显示 3D 场景的纹理视图,如下方可视化示例所示:

在 Pixel 4 上使用 uDepth 获取的单帧 RGB 点云示例
演示应用
https://storage.googleapis.com/gresearch/pixel4-udepth/udepth.zip
致谢
此项研究的顺利完成离不开大量人员的倾力支持,其中包括但不限于以下人员:Peter Barnum、Cheng Wang、Matthias Kramm、Jack Arendt、Scott Chung、Vaibhav Gupta、Clayton Kimber、Jeremy Swerdlow、Vladimir Tankovich、Christian Haene、Yinda Zhang、Sergio Orts Escolano、Sean Ryan Fanello、Anton Mikhailov、Philippe Bouchilloux、Mirko Schmidt、Ruofei Du、Karen Zhu、Charlie Wang、Jonathan Taylor、Katrina Passarella、Eric Meisner、Vitalii Dziuba、Ed Chang、Phil Davidson、Rohit Pandey、Pavel Podlipensky、David Kim、Jay Busch、Cynthia Socorro Herrera、Matt Whalen、Peter Lincoln、Geoff Harvey、Christoph Rhemann、Zhijie Deng、Daniel Finchelstein、Jing Pu、Chih-Chung Chang、Eddy Hsu、Tian-yi Lin、Sam Chang、Isaac Christensen、Donghui Han、Speth Chang、Zhijun He、Gabriel Nava、Jana Ehmann、Yichang Shih、Chia-Kai Liang、Isaac Reynolds、Dillon Sharlet、Steven Johnson、Zalman Stern、Jiawen Chen、Ricardo Martin Brualla、Supreeth Achar、Mike Mehlman、Brandon Barbello、Chris Breithaupt、Michael Rosenfield、Gopal Parupudi、Steve Goldberg、Tim Knight、Raj Singh、Shahram Izadi,以及设备与服务团队、Google Research、Android 等团队的其他同事。







