范式大学|迁移学习实战:从算法到实践
第一部分:背景介绍
本部分首先介绍迁移学习的背景,其次介绍为何要开发大规模分布式的迁移学习算法,最后简要介绍第四范式大规模分布式机器学习框架 GDBT 的特性。
简单来说,迁移学习是把一个领域(即源领域)的知识,迁移到另外一个领域(即目标领域),使得目标领域能够取得更好的学习效果。通常,源领域数据量充足,而目标领域数据量较小,迁移学习需要将在数据量充足的情况下学习到的知识,迁移到数据量小的新环境中。但是,如何形式化的描述所要迁移的知识,使用何种方法迁移知识,以及何时迁移是有效的、何时是有副作用的,是使用者所要关注的重点和难点,本次分享主要集中在前两个方面。至于如何保证迁移的有效性,目前并没有很好的理论来支持。
我们知道,近年来数据量的迅猛增长和计算能力的提升是推动这一波人工智能热潮的主要原因之一。但在实际业务中,我们会发现在很多情况下,数据量较小,不足以支撑 AI 去解决实际问题。而迁移学习能够通过发现大数据和小数据问题之间的关联,把知识从大数据中迁移到小数据问题中,从而打破人工智能对大数据的依赖。那么我们是否还需要大规模分布式机器学习平台呢?答案是肯定的。
因为即使目标领域数据量较小,我们也不能简单的将迁移学习视为小数据学习问题。一方面,源领域的数据量可能是巨大的,为了更好的学习到数据内在的结构等信息,需充分利用所有的数据;另一方面,迁移学习所涉及的领域可能有多个,当领域较多,即使每个领域的数据比较少,所有领域数据累计起来,数据量也可能是巨大的;再者,目标领域本身可能也需要较大的计算量,如一些基于深度学习的迁移学习场景。因此,我们在验证不同的迁移学习算法效果时,是基于第四范式的大规模分布式机器学习框架 GDBT,实现的多机分布式并行计算版本,而非单机。
GDBT(General Distributed Brilliant Technology)是一个为分布式大规模机器学习设计的计算框架,兼顾开发效率和运行效率,使算法工程师可以基于 GDBT 开发各种传统或者创新算法的分布式版本,而不用过多地关心分布式底层细节。它针对机器学习任务在计算、通讯、存储、灾备等方面做了深入的优化,定制了通信框架、算法框架以及参数服务器,为进行大规模机器学习训练提供了基石。GDBT 还有一个很大的特性是对算法开发者友好。它提供的是工业级的开发者易用性,从语言级别上,GDBT 整体基于 C++14 标准,为算法的开发提供了更大的自由;从功能抽象上,GDBT 提供了对参数服务器和算子的良好包装。在 GDBT 上,只需要数百行代码就可以实现像对数几率回归(LR)、矩阵分解(MF)等算法的分布式版本。
接下来,我们将结合赛题,重点介绍基于 GDBT,对一些经典的迁移学习算法进行的尝试与心得。需要说明的是,以下所提及的算法,均是我们基于 GDBT,自主研发,暂未使用开源工具。
第二部分:基于GDBT的迁移学习实践
比赛主办方为平安旗下前海征信,是国内首个迁移学习赛题:给定 4 万条业务 A 数据及 4 千条业务 B 数据,建立业务 B 的信用评分模型。其中业务 A 为信用贷款, 其特征是债务人无需提供抵押品,仅凭自己的信誉就能取得贷款,并以借款人信用程度作为还款保证;贷款期限为 1-3 年,平均贷款金额为几千至几万的中等额度信用贷款业务。业务 B 为现金贷,即发薪日贷款,贷款期限为 7-30 天,平均贷款金额为一千的小额短期贷款业务。业务 A、B 对应的数据特征完全一致。由于业务 A、B 存在关联性,如何将业务 A 的知识迁移到业务 B,以此增强业务 B 的信用评分模型,是比赛的重点。比赛评测指标是模型在 B 的测试集合上的 AUC。(注:AUC 是业界较为常用的一个模型评测指标,AUC 越高表示模型预测性能越好。)
为和比赛保持一致,本次分享在描述相关算法时,仅考虑两个领域间的迁移学习,即将一个源领域(记为 Ds)中的知识,迁移到一个目标领域(记为 Dt)中。源领域和目标领域分别对应的学习任务记为 Ts 和 Tt。以比赛为例,业务 A 对应源领域 Ds 和学习任务 Ts,业务 B 对应目标领域 Dt 和学习任务 Tt。
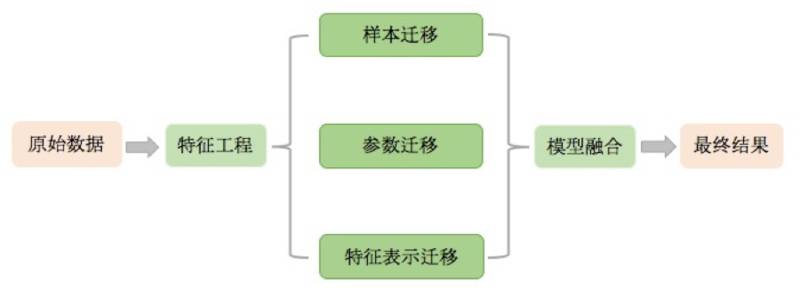
本次比赛的解题流程如下图所示:首先,我们对原始数据预处理并提取特征,然后运用迁移学习模型对问题建模,最后将不同的模型结果融合,得到最终的预测结果。因特征工程和业务强相关,不同的问题对应的特征提取方法可能相差很大,为了最大化本次解决方案的可扩展性,在参赛过程中,我们并未在特征工程上花费较多精力,仅是简单的将所有特征作为连续值特征处理和缺失值填充。
根据 Sinno Jialin Pan 和 Qiang Yang 在 TKDE 2010 上的文章,可将迁移学习算法,根据所要迁移的知识表示形式(即 “what to transfer”),分为四大类:
1)基于样本的迁移学习(instance-transfer);
2)基于参数的迁移学习(parameter-transfer);
3)基于特征表示的迁移学习(feature-representation-transfer);
4)基于关系知识的迁移(relational-knowledge-transfer)。
其中,基于关系知识的迁移认为样本之间具有相关性,而非独立同分布,如知识图谱,主要应用统计关系学习的方法如马尔科夫逻辑网(markov logic network),不在我们本次分享的范围内。我们将结合比赛,重点阐述前三类方法。
转自:第四范式



