【语言模型系列】原理篇一:从one-hot到Word2vec
这次的系列文章将会介绍NLP领域语言模型及词向量表示的发展史,原理篇会从远古时代的one-hot出现讲到时代新星bert及其改进,同时后续的实践篇将会介绍预训练模型在房产领域的工业实践应用,带你填上一个个的大坑。话不多说,操练起来~
语言模型及词向量
何为语言模型?这是一个要贯穿整篇文章的问题。所谓语言模型,就是判断一句话是不是人话的模型,也就判断出是>的模型。当然,计算机并不认识周杰伦,它只知道0和1,所以我们让模型进行判断时,需要将丰富的文字转换成冷冰冰的数字,这样计算机才能帮助我们进行计算,这也就是词向量的由来和存在的意义。
一个好的语言模型就是判断一句人话的概率尽可能的高,判断非人话的概率尽可能的低。那什么是一个好的词向量呢?举个例子,比如当我们人类看到‘woman’和‘female’时,会觉得这两个词应该是相似的意思,那么一个好的词向量表示就是让计算机通过计算这两个词向量,得出这两个词相似的结论。一般就是让计算机通过计算两个向量之间的距离来进行判断。所以如何让计算机看到的词向量和我们看到的词具有相同的意义,这是研究词向量的究极目标。
语言模型往往需要借助词向量进行计算,一个好的语言模型的诞生往往会伴随着质量较高的词向量的出现,因此词向量往往是语言模型的副产品。当然,优秀的事务往往不是一蹴而就的,语言模型和词向量的发展也经历了多个阶段。从词向量的角度来简单分类的话,大致可以分为one-hot表示和分布式表示两个大阶段,下面将从这个角度进行介绍。
一、one-hot表示
one-hot的想法简单粗暴,目的单纯,在我们的大脑和计算机之间架起了第一道桥梁。one-hot将每一个词表示成一个固定维度的向量,维度大小是词表大小,向量中单词所在位置为1,其他位置为0。举个栗子,假设我们的词库里只有如下7个词
my,on,the,bank,river,woman,female那么bank这个单词就可以表示为[0,0.0,1,0,0,0],on可以表示为[0,1,0,0,0,0,0],以此类推。
但是想法过于简单总是会出问题的,one-hot存在的两个明显问题:维度灾难和语义鸿沟。
所谓维度灾难就是one-hot的向量维度是和词库大小一致的,一般我们的词库会很大,比如当我们的词库里有100000个词,那么一个词向量的维度就是 ,这就导致one-hot表征的向量维度很大,使得数据样本稀疏,距离计算困难,造成维度灾难。当维度灾难发生时,一个样本的特征就会过于多,导致模型学习过程中极其容易发生过拟合。
所谓语义鸿沟的问题是因为one-hot生成的词向量都是彼此正交的,体现不出任何语义上的联系。比如on表示为[0,1,0,0,0,0,0],woman表示为[0,0.0,0,0,1,0],female表示为[0,0.0,0,0,0,1],on和woman这两个向量相乘结果是0,female和woman这两个向量相乘也是0,所以无法表现出on和woman不相似,female和woman相似这种语义上的联系。
二、分布式表示
鉴于one-hot表示的缺点,我们希望能有低维稠密的词向量出现,同时这些向量之间能够存在语义上的联系,所以分布式表示就带着历史使命出现了。分布式表示描述的是将文本分散嵌入到另一个空间,一般是将高维映射到低维稠密的向量空间。分布式表示依据的理论是Harris在1954年提出的分布式假说,即:上下文相似的词,其语义也相似。
2.1 基于SVD
这一类方法的一般操作是将共现矩阵 进行SVD分解,即 ,然后取分解后的 的作为词向量矩阵(一般取U的子矩阵)。所以啥是共现矩阵,啥是SVD呢?
2.1.1 共现矩阵
共现矩阵一般有两种,第一种叫Window based Co-occurrence Matrix,是通过统计指定窗口大小的单词共现次数构成的矩阵,举个栗子,假设我们的语料库中只有三个句子
I like deep learning.I like NLP.I enjoy flying.
选取窗口大小为3,那么构成的共现矩阵 如下图所示
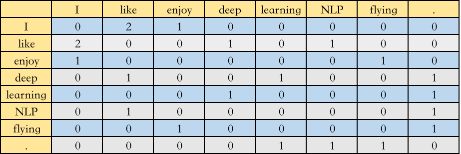
第二种叫Word-Document Matrix,是将单词在文档中出现的频率构成矩阵,再举个栗子,假设我们一共有三篇文档
document1: I like deep learning. I enjoy deep learningdocument2: I like NLP.document3: I enjoy flying.
那么构成的共现矩阵 如下图所示
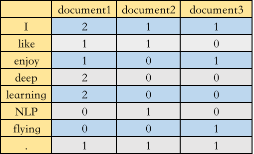
2.1.2 SVD
前面提到,SVD是将矩阵 进行分解, ,其中 是 的矩阵, 是 的矩阵, 是 的矩阵, 是 的矩阵,如何求解得到这三个矩阵呢?
首先回顾一下特征值和特征向量的定义:
其中,A是 的实对称矩阵, 是一个 维向量,则称 是一个特征值, 是矩阵 的特征值 对应的一个特征向量。如果我们求出了 个特征值 及其对应的特征向量 ,如果这 个特征向量线性无关,那么矩阵 就可以表示为
其中, 是有 个特征向量组成的 的矩阵, 是由 个特征值为主对角线的 维矩阵。一般会将 进行标准化,即 , , ,也就是得到了 ,那么 就可以表示为
需要注意的是,直接进行特征分解的矩阵 是方阵,而在SVD中的矩阵 不一定是方阵,这时需要再做一些推导。
由于 ,所以
因为 是一个 的方阵,所以通过求解 的特征向量,就可以得到矩阵 。同理,通过求解 的特征向量,就可以得到矩阵 ,通过对 的特征值矩阵求平方根,就可以得到矩阵 的奇异值矩阵\Sigma$。至此,我们得到了矩阵A的分解。
值得注意的是,奇异值是从大到小排列的,通常前10%甚至1%的奇异值的和就占了所有奇异值和的99%以上,奇异值在集合意义上代表了特征的权重,所以我们一般不会选择将整个 矩阵作为词向量矩阵,而是选择前k维,最终的词向量表大小就是 , 是词表大小, 是词向量维度。
基于SVD的方法得到了稠密的词向量,相比于之前的one-hot有了一定提升,能够表现单词之间一定的语义关系,但是这种方法也存在很多问题:
-
矩阵过于稀疏。因为在构建共现矩阵时,必然有很多词是没有共现的 -
分解共现矩阵的复杂度很高 -
高频无意义的词影响共现矩阵分解的效果,如is,a -
一词多义问题,即同一个词具有不同含义却被表示为一个向量,比如bank既有银行的意思,也有岸边的意思,但在这里被表示为统一的向量
2.2 基于语言模型
基于语言模型的方法抛弃了共现矩阵这种问题重重的东西,转而通过构建语言模型来产生词向量。so,啥是语言模型呢?
标准定义:对于语言序列 ,语言模型就是计算该序列出现的概率,即
通俗理解:构建一个模型,使得看起来像人话的句子序列出现的概率大,非人话的句子序列出现的概率小,也就是>
语言模型一般包括统计语言模型和神经网络语言模型,统计语言模型一般就是指N-gram语言模型,神经网络语言模型包括NNLM、Word2vec等。
2.2.1 N-gram
N-gram就是一个语言模型,其目的并非产生词向量,一般用于判断语句是否合理或者搜索sug推荐,这里简单一提。
前面说了,语言模型计算一句人话的概率,也就是 ,利用链式法则可知
直接计算上式计算量太大,所以N-gram模型引入马尔科夫假设,即当前词出现的概率只与其前n-1个词有关
当语料足够大时
真正常用的N-gram的n不会超过3,一般为n=2。当n=2时,利用上式计算一句话的概率
2.2.2 NNLM
使用语言模型产生词向量的一个里程碑论文是Bengio在2003年提出的NNLM,该模型通过使用神经网络训练得到了一个语言模型,同时产生了副产品词向量。模型的总体架构如下图所示,表达的思想是利用前n-1个词去预测第n个词的概率,所以这里的输入是n-1个词,输出是一个维度为词表大小的向量,代表每个词出现的概率。
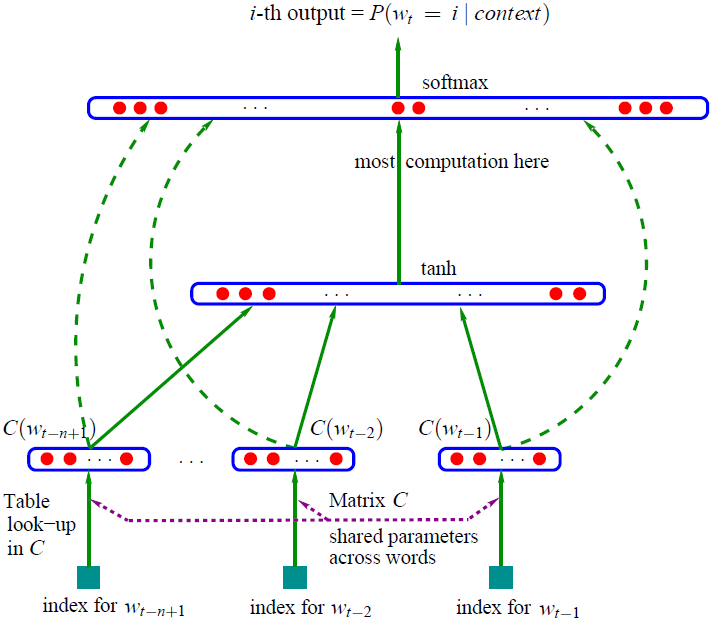
这个结构在现在看起来是很简单
-
首先输入层将当前词 的前 个词 作为上文,通过对词向量表 进行look-up得到词向量表示 ,每个词的维度是
-
然后将这 个词向量进行拼接,得到一个维度是 的长向量 ,然后经过隐层计算,得到一个 的向量 ,模型训练过程中最大的运算量就在这一层
参数 ,其中 和 是偏置,是参数矩阵, 是将词向量直连到输出时的参数,可以置为0, 是超参数。
利用softmax对输出概率进行归一化
-
使用交叉熵作为损失函数,所以对于单个样本,其优化目标是就是最大化 ,利用随机梯度下降进行优化
优化结束后,得到了一个语言模型,同时得到了词向量矩阵 。
NNLM模型在获取词向量上的工作是奠基性的,但是其模型训练的复杂度还是过高,后续很多算法都是在NNLM的基础上进行改进,比如耳熟能详的Word2vec对其训练的复杂度进行了针对性的改进。
前面所讲的都是一些开胃小菜,建立该系列文章的核心概念--词向量。接下来我们将会对经典算法Word2vec单独拿出来进行详细的原理介绍~
三、word2vec
Word2vec是谷歌团队在2013年开源推出的一个专门用于获取词向量的工具包,其核心算法是对NNLM运算量最大的那部分进行了效率上的改进,让我们来一探究竟。
3.1 Word2vec原理解析
word2vec有两种模型--CBOW和Skip-gram,这两个模型目的都是通过训练语言模型任务,得到词向量。CBOW的语言模型任务是给定上下文预测当前词,Skip-gram的语言模型任务是根据当前词预测其上下文。
Word2vec还提供了两种框架--Hierarchical Softmax和Negative-Sampling,所以word2vec有四种实现方式,下面将对其原理进行介绍。
3.1.1 CBOW
3.1.1.1 结构
CBOW的核心思想就是利用给定上下文 ,预测当前词 ,其结构表示为
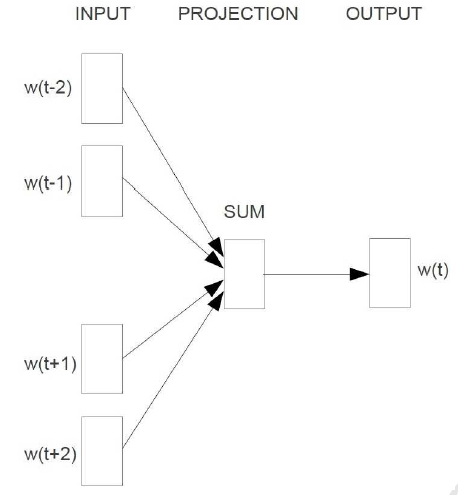
我们知道基于神经网络的语言模型的目标函数通常是对数似然函数,这里CBOW的目标函数应该就是
其中 是单词 的上下文, 是词典。所以我们关注的重点应该就是 的构造上,NNLM和Word2vec的本质区别也是在于该条件概率函数的构造方式不同。
3.1.1.2 原理
3.1.1.2.1 基于Hierarchical Softmax
CBOW模型的训练任务是在给定上下文 ,预测当前词 。基于Hierarchical Softmax的CBOW结构相当于在NNLM上的改进,如下图所示
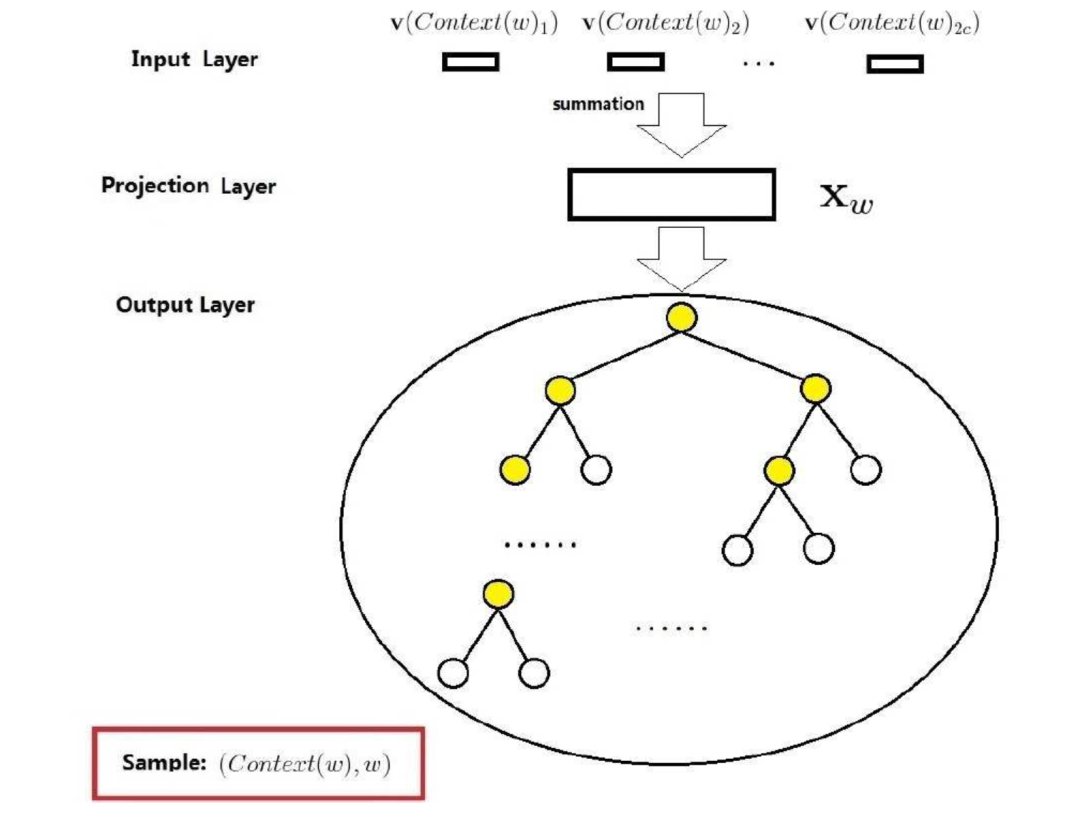
CBOW模型一共是有三层,分别是输入层(input layer),投影层(projection layer)和输出层(output layer)。
输入层:输入是当前词的上下文,共 个词向量
投影层:投影层将 个词向量进行累加,得到 ,即,这里不包含当前词的向量表示
输出层:输出是一个用语料中出现的词为叶子结点构建的Huffman树,结点的权值是各词在语料中出现的次数。图中的Huffman树共 个结点,对应语料中的 个词,非叶子结点 个,即图中标黄的。
基于Hierarchical Softmax的CBOW模型和之前介绍的NNLM的主要区别:
-
从输入层到投影层,CBOW采用的是求和,而NNLM是拼接 -
CBOW没有隐藏层 -
输出层,基于Hierarchical Softmax的CBOW是树形结构,NNLM是线性结构
之前说过,NNLM的主要运算量就是在于隐藏层和输出层的softmax的计算量,基于Hierarchical Softmax的方法通过对这些关键点进行了针对性的优化,去掉了隐藏层,更改了输出结构,大大提升了运算效率。下面介绍基于Hierarchical Softmax的CBOW是如何利用树结构训练得到词向量的。
对于huffman的某个叶子结点,假设该结点对应词典 中的词 ,定义以下符号
-
:从根结点出发到达 对应的叶子结点的路径 -
:路径 中包含的结点个数 -
:路径 中的 个结点,其中 代表根结点, 代表词 对应的结点 -
:词 的Huffman编码,由 位编码构成,即根结点不对应编码 -
:路径 中非叶子结点对应的向量, 代表路径 中第 个非叶子结点对应的向量
下面通过一个示例说明运算原理,如下图所示,考虑当前词 =“足球”,那么图中的红色边串起来的5个结点就构成路径 ,其长度 ,是路径 的5个结点,其中 对应的是根结点, 分别是1,0,0,1,即当前词“足球”的Huffman编码为1001, 分别是路径 上4个非叶子结点对应的向量。
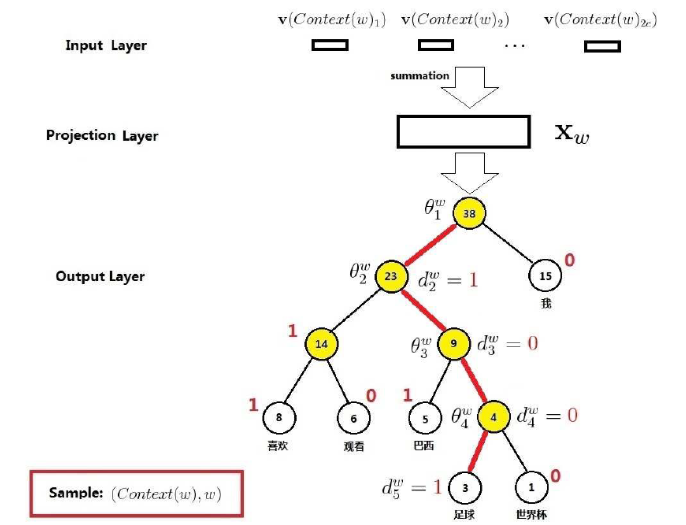
所以,讲了这么多,我们的重点 究竟是怎么构建的呢?
我们知道词库里的每一个词都可以被表示为一个Huffman编码,如果把Huffman树每一个结点都看成一次二分类,那么这个语言模型的任务就变成输入上下文,使得当前词的Huffman编码对应的路径的概率最大。这里约定将一个结点进行二分类时,分到左边为负类,分到右边为正类(主要为了和源码对应),即
由前面介绍的逻辑回归可以知道,结点分为正类的概率是
所以分为负类的概率就是 。这里的 就是当前词 的上下文通过求和得到的, 就是每一个结点的 ,是待训练参数。
举个栗子,还是前面说的当前词是“足球”,从根结点出发到达这个词一共需要经过4次二分类
-
第一次: -
第二次: -
第三次: -
第四次:
所以对于当前词“足球”,我们的条件概率函数为
由上面的小例子,我们可以扩展出一般的条件概率公式
其中
写成整体表达式
所以我们要优化的目标函数就是
令
使用随机梯度上升法进行目标函数优化,下面推导一下梯度的计算
所以,更新参数 时
其中, 是学习率。
同理可以计算得到
我们最终想优化的向量是词表中的每一个词向量,而 是当前词上下文的累加,那么该如何更新每个词的向量表示呢?word2vec中的做法很简单直接,就是将 的梯度变化等效于每个词的梯度变化,即
至此,基于Hierarchical Softmax的CBOW模型的原理就介绍完了,通过不断训练就可以得到我们想要的词向量表。
3.1.1.2.2 基于Negative-Sampling
基于Negative-Sampling(负采样,NEG)的方法的目的是进一步提升训练速度,同时改善词向量的质量。NEG不再使用相对复杂的huffman树,而是使用简单的随机负采样,大幅度提升性能。
CBOW是利用上下文预测当前词,那么将当前词替换为其他词时,就构成了一个负样本。
书面一点,对于给定的 ,词 就是一个正样本,其他词就是负样本,假设我们通过负采样方法选取好一个关于 的负样本子集 。得到样本集后,我们的目标是最大化
其中
所以
这里, 还是代表上下文 的词向量之和, 表示词 对应的一个待训练辅助向量。直观上看,这就是最大化 的同时,最小化 ,其中 ,也就是最大化正样本的概率的同时最小化负样本的概率。
对于给定的语料库C,最终的目标函数是
为了推导梯度更新的过程,令
所以
同理
3.1.2 Skip-gram
3.1.2.1 结构
Skip-gram的核心思想就是利用给定的当前词 ,预测上下文 ,其结构表示为
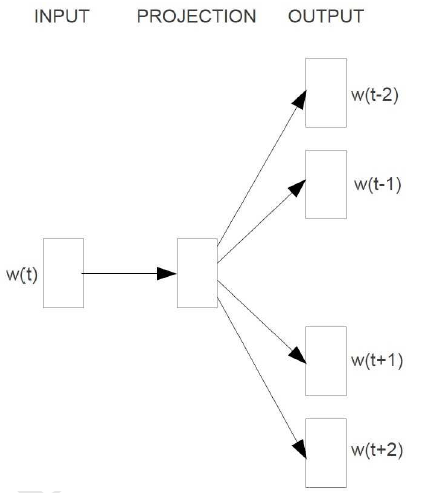
我们知道基于神经网络的语言模型的目标函数通常是对数似然函数,这里Skip-gram的目标函数应该就是
其中 是单词 的上下文, 是词典。所以我们关注的重点应该就是 的构造上。
3.1.2.2 原理
3.1.2.2.1 基于Hierarchical Softmax
前面说了,Skip-gram的语言模型任务是根据当前词预测其上下文,原理上和CBOW很相似,基于Hierarchical Softmax的Skip-gram的结构如下图所示
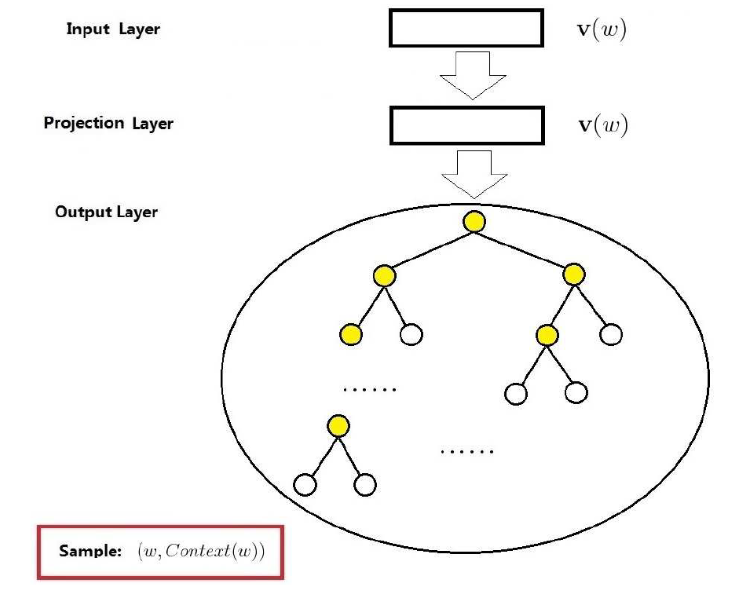
输入层:中心词 的词向量
投影层:恒等投影,只是为了和CBOW模型进行对称类比
输出层:和CBOW一样,是一颗huffman树
Skip-gram的重点是条件概率函数 的构造,SKip-gram中对于该条件概率函数的定义为
所以,Skip-gram的目标函数为
令
则
所以
同理
3.1.2.2.2 基于 Negative-Sampling
基于负采样的skip-gram模型基本与前面基于负采样的CBOW推导的类似,目标函数为
也就是当给定当前词 时,希望其上下文 出现的概率最大,其中
这里 代表的就是上下文 中某个词 出现的概率, 表示处理词 时生成的负样本子集, 是输入的当前词, 是待训练的辅助向量。
所以
可以看出来,这里需要对上下文 中的每一个词做一次负采样。实际上,作者在源码实现过程中并没有这么做,而是针对 进行了 次负采样,这样依赖,我们的目标函数变成
其中
这里 表示处理词 时生成的负采样子集。
最终的目标函数变成
考虑梯度更新,令
所以
同理
3.2 Word2vec不可忽视的问题
Word2vec算法虽然在前些年取得了良好的效果,但是也有不足之处,其中最不可忽视的问题就是一词多义的问题。Word2vec中最后对每一个词生成一个固定的向量表示,那么对于相同单词有多个含义时,就不能很好的解决。比如bank,既有银行的意思,也有岸边的意思,当算法的结果只有一个固定向量对其进行表征时,必然导致这个词的表征不够准确。
既然存在问题,那就存在解决问题的方法,现在比较火的预训练相关的算法就解决了这个问题。具体咋回事呢?下一篇文章见~
作者介绍
李东超,2019年6月毕业于北京理工大学信息与电子学院,毕业后加入贝壳找房语言智能与搜索部,主要从事自然语言理解等相关工作。
下期精彩
【语言模型系列】原理篇二:从ELMo到ALBERT
招贤纳士

推荐阅读
数学之美中盛赞的 Michael Collins 教授,他的NLP课程要不要收藏?
From Word Embeddings To Document Distances 阅读笔记
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
可解释性论文阅读笔记1-Tree Regularization
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。



