从零开始用Python写一个聊天机器人(使用NLTK)

本文为 AI 研习社编译的技术博客,原标题 :
Building a Simple Chatbot from Scratch in Python (using NLTK)
作者 | Parul Pandey
翻译 | Disillusion
校对 | 酱番梨 整理 | 菠萝妹
原文链接:
https://medium.com/analytics-vidhya/building-a-simple-chatbot-in-python-using-nltk-7c8c8215ac6e
注:本文的相关链接请点击文末【阅读原文】进行访问
不要忘记今晚还有Momenta研发工程师周越带来的【AWS 联网汽车参考方案解析】分享哦!
戳右图直接观看!

从零开始用Python写一个聊天机器人(使用NLTK)
来源: eWeek
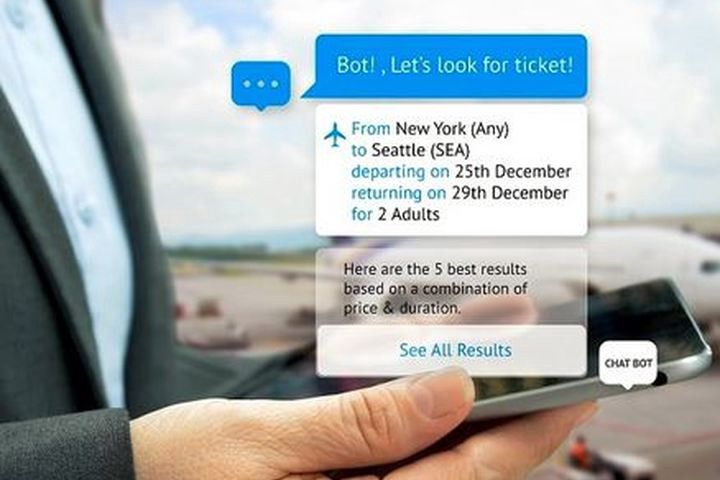
Gartner 估计到2020年聊天机器人将处理85%的客户服务交互;它们现在已经处理了大约30%。
我肯定你听说过 Duolingo :一款流行的语言学习应用,可以通过游戏来练习一门新语言。它因其新颖的外语教学方式而广受欢迎。其概念很简单:每天五到十分钟的互动训练就足以学习一门语言。
然而,尽管Duolingo 正在帮助人们学习一门新的语言,但它的实践者们却有一个担忧。人们觉得自己没有学习到有价值的会话技巧,因为他们是在自学。由于害怕尴尬,人们也害怕与其他语言学习者配对。这成了Duolingo 规划中的一大瓶颈。
因此他们的团队通过在自己的应用程序中构建一个本地聊天机器人来解决这个问题,帮助用户学习会话技能并实践他们所学的知识。
http://bots.duolingo.com/
由于这些机器人被设计成会话型和友好型的,Duolingo 学习者可以在一天中的任何时间与他们选择的角色机器人练习会话,直到他们有足够的勇气与其他说新语言的人一起练习为止。这解决了消费者的一个主要痛点,让通过应用学习变得更加有趣。
所以什么是聊天机器人?
聊天机器人是人造的以智慧为动力的软件(比如Siri,Alexa,谷歌助理等),它们存在于设备中,应用程序,网站或其他网络,试图衡量消费者的需要,然后帮助他们执行一个特定任务,如商业交易,酒店预订,表单提交等等。今天几乎每个公司都 部署聊天机器人与用户交流。公司使用聊天机器人的一些方式是:
提供航班信息
连接客户和他们的财务
作为客户支持
可能性(几乎)是无限的。
聊天机器人的历史可以追溯到1966年,当时韦森鲍姆发明了一种名为“伊丽莎”(ELIZA)的电脑程序。它仅仅从200行代码中模仿一个心理治疗师的言语。你现在仍然可以和它交谈:伊丽莎。
Source: Cognizant
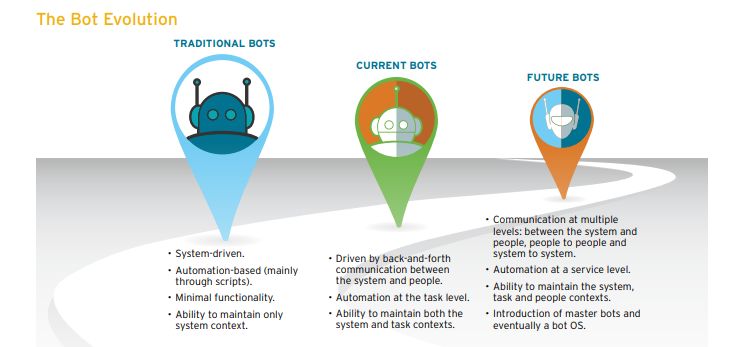
聊天机器人如何工作?
聊天机器人大致有两种变体:基于规则的和自学习的。
基于规则的聊天机器人将根据它所训练的一些规则回答问题。定义的规则可以非常简单,也可以非常复杂。机器人可以处理简单的查询,但无法管理复杂的查询。
自学习机器人使用一些基于机器学习的方法,他们往往比基于规则的机器人更有效。这些机器人进一步分为以下两种类型:基于检索或生成型
在基于检索的模型中,聊天机器人使用一些启发式方法从预定义的响应库中选择响应。聊天机器人使用消息和对话上下文从预定义的聊天机器人消息列表中选择最佳响应。上下文可以包括对话树中的当前位置、对话中的所有先前消息、先前保存的变量(例如用户名)。选择响应的启发式方法可以采用许多不同的方式进行设计,从基于规则的if-else条件逻辑到机器学习分类器等。
生成型机器人可以生成回答,但并不总是用一组答案中的一个来回答。这使他们更聪明,因为他们从查询中逐字提取并生成答案。
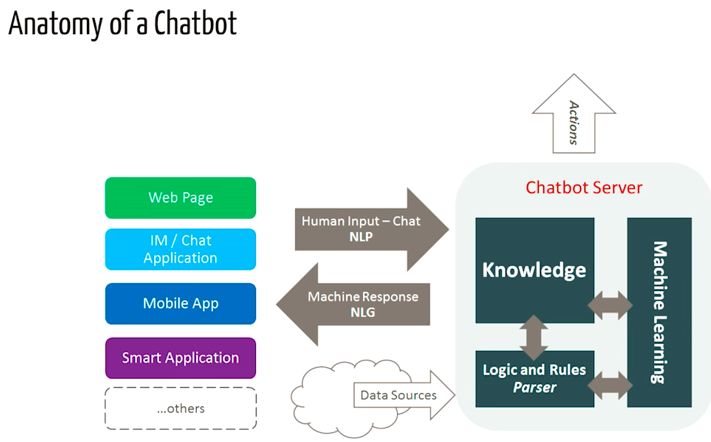
在本文中,我们将在python中基于NLTK库构建一个简单的基于检索的聊天机器人。
开始构建机器人
先决条件
具有scikit库和NLTK的实际操作知识。但是你如果是NLP新手,仍然可以阅读本文,然后参照参考资料。
NLP
研究人类语言和计算机交互的领域称为自然语言处理,简称NLP。它位于计算机科学、人工智能和计算语言学的交汇处(维基百科)。NLP是计算机分析、理解和从人类语言中获取意义的一种聪明且有用的方法。利用NLP,开发人员可以组织和结构化知识来执行诸如自动摘要、翻译、命名实体识别、关系提取、情感分析、语音识别和主题分割等任务。
NLTK: 简要介绍
NLTK(自然语言工具包)是构建Python程序来处理人类语言数据的领先平台。它为超过50个语料库和词汇资源(如WordNet)提供了易于使用的接口,同时提供了一套用于分类、词语切分、词干、标记、解析和语义推理的文本处理库,这些都是工业强度NLP库的封装器。
NLTK被称为“使用Python进行计算语言学教学和工作的一个极好工具”,以及“一个与自然语言打交道的绝佳库”。
Python的自然语言处理提供了语言处理编程的实用介绍。我强烈推荐这本书给使用Python的NLP初学者。
下载及安装NLTK
安装NLTK: 运行 pip install nltk
测试安装: 运行 python 接着输入 import nltk
对特定平台的指令,点这。
安装NLTK包
导入NLTK 然后运行 nltk.download().这将打开NLTK的下载程序,你可以从其中选择要下载的语料库和模型。也可以一次下载所有包。
用NLTK对文本进行预处理
文本数据的主要问题是它都是文本格式(字符串)。然而,机器学习算法需要某种数值特征向量来完成任务。因此,在我们开始任何NLP项目之前,我们都需对其进行预处理。基本文本预处理包括:
将整个文本转换为大写或小写,这样算法就不会将大小写的相同单词视为不同的单词
词语切分:指将普通文本字符串转换为符号列表的过程。也就是我们真正想要的词。句子分词器可用于查找句子列表,单词分词器可用于查找字符串形式的单词列表。
NLTK数据包包括一个用于英语的预训练Punkt分词器。
去除噪声,即所有不是标准数字或字母的东西。
删除停止词。有时,一些在帮助选择符合用户需要的文档方面似乎没有什么价值的常见单词被完全排除在词汇表之外。这些单词叫做停止词。
词干提取:词干提取是将词尾变化词(有时是派生词)还原为词干、词根或词根形式(通常是书面形式)的过程。例如,如果我们要提取下列词:“Stems”, “Stemming”, “Stemmed”, “and Stemtization”,结果将是一个词“stem”。
词形还原:词干提取的一个细微变体是词形还原 。它们之间的主要区别在于,词干提取可以创建不存在的词,而词元是实际的词。所以你的词根,也就是你最终得到的词,在字典里通常是查不到的,但词元你是可以查到的。词形还原的例子如:“run”是“running”或“ran”等词的基本形式,或者“better”和“good”是同一个词元,因此它们被认为是相同的。
单词袋
在初始预处理阶段之后,我们需要将文本转换为有意义的数字向量(或数组)。单词袋是描述文档中单词出现情况的文本表示。它包括两个东西:
•一个已知词汇表。
•一个对已知词存在的量度。
为什么它被称为一个单词袋?这是因为关于文档中单词的顺序或结构的任何信息都会被丢弃,模型只关心已知单词是否出现在文档中,而不关心它们在文档中的位置。
单词袋的直观感受是,如果文档的内容相似,那么文档就相似。此外,我们还可以从文档的内容中了解一些文档的含义。
例如,如果我们的字典包含单词{Learning, is, the, not, great},并且我们想向量化文本“Learning is great”,我们将有以下向量:(1,1,0,0,1)。
TF-IDF 方法
单词袋方法的一个问题是,频繁出现的单词开始在文档中占据主导地位(例如,得分更高),但可能并没有包含太多的“有信息内容”。此外,它将给予较长的文档更多的权重。
一种方法是根据单词在所有文档中出现的频率重新调整单词的频率,以便对“the”等在所有文档中也经常出现的单词适当降低权重。这种评分方法称为检索词频率-逆文档频率,简称TF-IDF,其中:
检索词频率: 是当前文档中单词出现频率的得分。
TF = (Number of times term t appears in a document)/(Number of terms in the document)
逆文档频率:是这个词在文档中罕见度的得分。
IDF = 1+log(N/n), where, N is the number of documents and n is the number of documents a term t has appeared in.
Tf-idf 权重是信息检索和文本挖掘中常用的一种权重。该权重是一种统计度量,用于评估单词对集合或语料库中的文档有多重要
例子:
考虑一个包含100个单词的文档,其中单词“phone”出现了5次。
“phone”的检索词频率就是(5 / 100) = 0.05。现在,假设我们有1000万份文档,其中1000份文档中出现了“电话”这个词。那么逆文档频率就是log(10,000,000 / 1,000) = 4。TF-IDF权重就是这两者的乘积:0.05 * 4 = 0.20。
Tf-IDF 可以在scikit learn中调用:
from sklearn.feature_extraction.text import TfidfVectorizer
余弦相似度
TF-IDF是一种在向量空间中得到两个实值向量的文本变换。然后我们可以通过取点积然后除以它们的范数乘积来得到任意一对向量的余弦相似度。接着以此得到向量夹角的余弦值。余弦相似度是两个非零向量之间相似度的度量。利用这个公式,我们可以求出任意两个文档d1和d2之间的相似性。
Cosine Similarity (d1, d2) = Dot product(d1, d2) / ||d1|| * ||d2||
其中d1,d2是非零向量。
TF-IDF和余弦相似度的详细说明和实际例子参见下面的文档。
Tf-Idf and Cosine similarity
In the year 1998 Google handled 9800 average search queries every day. In 2012 this number shot up to 5.13 billion…janav.wordpress.com
现在我们对NLP过程有了一个基本概念。是我们开始真正工作的时候了。我们在这里将聊天机器人命名为“ROBO🤖”
导入必备库
import nltk
import numpy as np
import random
import string # to process standard python strings
语料库
在我们的示例中,我们将使用聊天机器人的Wikipedia页面作为我们的语料库。从页面复制内容并将其放入名为“chatbot.txt”的文本文件中。然而,你可以使用你选择的任何语料库。
读入数据
我们将阅读corpus.txt文件,并将整个语料库转换为句子列表和单词列表,以便进行进一步的预处理。
f=open('chatbot.txt','r',errors = 'ignore')
raw=f.read()
raw=raw.lower()# converts to lowercase
nltk.download('punkt') # first-time use only
nltk.download('wordnet') # first-time use only
sent_tokens = nltk.sent_tokenize(raw)# converts to list of sentences
word_tokens = nltk.word_tokenize(raw)# converts to list of words
让我们看看sent_tokens 和 the word_tokens的例子
['a chatbot (also known as a talkbot, chatterbot, bot, im bot, interactive agent, or artificial conversational entity) is a computer program or an artificial intelligence which conducts a conversation via auditory or textual methods.',
['a', 'chatbot', '(', 'also', 'known']
预处理原始文本
现在我们将定义一个名为LemTokens 的函数,它将接受符号作为输入并返回规范化符号。
lemmer = nltk.stem.WordNetLemmatizer()
#
def LemTokens(tokens):
return [lemmer.lemmatize(token) for token in tokens]
remove_punct_dict = dict((ord(punct), None) for punct in string.punctuation)
def LemNormalize(text):
return LemTokens(nltk.word_tokenize(text.lower().translate(remove_punct_dict)))
关键字匹配
接下来,我们将通过机器人定义一个问候函数,即如果用户的输入是问候语,机器人将返回相应的回复。ELIZA使用一个简单的关键字匹配问候。我们将在这里使用相同的概念。
GREETING_INPUTS = ("hello", "hi", "greetings", "sup", "what's up","hey",)
GREETING_RESPONSES = ["hi", "hey", "*nods*", "hi there", "hello", "I am glad! You are talking to me"]
def greeting(sentence):
for word in sentence.split():
if word.lower() in GREETING_INPUTS:
return random.choice(GREETING_RESPONSES)
生成回复
为了让我们的机器人为输入问题生成回复,这里将使用文档相似性的概念。因此,我们首先需要导入必要的模块。
从scikit learn库中,导入TFidf矢量化器,将一组原始文档转换为TF-IDF特征矩阵。
from sklearn.feature_extraction.text import TfidfVectorizer
同时, 从scikit learn库中导入cosine similarity模块
from sklearn.metrics.pairwise import cosine_similarity
这将用于查找用户输入的单词与语料库中的单词之间的相似性。这是聊天机器人最简单的实现。
我们定义了一个回复函数,该函数搜索用户的表达,搜索一个或多个已知的关键字,并返回几个可能的回复之一。如果没有找到与任何关键字匹配的输入,它将返回一个响应:“对不起!”我不明白你的意思"
def response(user_response):
robo_response=''
TfidfVec = TfidfVectorizer(tokenizer=LemNormalize, stop_words='english')
tfidf = TfidfVec.fit_transform(sent_tokens)
vals = cosine_similarity(tfidf[-1], tfidf)
idx=vals.argsort()[0][-2]
flat = vals.flatten()
flat.sort()
req_tfidf = flat[-2]
if(req_tfidf==0):
robo_response=robo_response+"I am sorry! I don't understand you"
return robo_response
else:
robo_response = robo_response+sent_tokens[idx]
return robo_response
最后,我们将根据用户的输入来决定机器人在开始和结束对话时说的话。
flag=True
print("ROBO: My name is Robo. I will answer your queries about Chatbots. If you want to exit, type Bye!")
while(flag==True):
user_response = input()
user_response=user_response.lower()
if(user_response!='bye'):
if(user_response=='thanks' or user_response=='thank you' ):
flag=False
print("ROBO: You are welcome..")
else:
if(greeting(user_response)!=None):
print("ROBO: "+greeting(user_response))
else:
sent_tokens.append(user_response)
word_tokens=word_tokens+nltk.word_tokenize(user_response)
final_words=list(set(word_tokens))
print("ROBO: ",end="")
print(response(user_response))
sent_tokens.remove(user_response)
else:
flag=False
print("ROBO: Bye! take care..")
差不多就是这样。我们用NLTK中编写了第一个聊天机器人的代码。你可以在这里找到带有语料库的完整代码。现在,让我们看看它是如何与人类互动的:

尽管聊天机器人在某些问题上不能给出令人满意的答案,但在另一些问题上却表现得很好。
结论
虽然它是一个非常简单的机器人,几乎没有任何认知技能,但它是一个很好的方法来了解NLP和聊天机器人。虽然“ROBO”会对用户输入做出响应。但它愚弄不了你的朋友,对于一个生产系统,你可能希望考虑现有的机器人平台或框架之一,但是这个示例应该能够帮助你思考设计和创建聊天机器人的挑战。互联网充斥着大量的资源,在阅读了这篇文章之后,我相信你会想要创建一个自己的聊天机器人。快乐编程! !
想要继续查看该篇文章相关链接和参考文献?
长按链接点击打开或点击底部【阅读原文】:
https://ai.yanxishe.com/page/TextTranslation/1078
AI研习社每日更新精彩内容,观看更多精彩内容:
自然语言处理中的词表征(第一部分)
自然语言处理中的词表征(第二部分)
图片语义分割深度学习算法要点回顾
特朗普都被玩坏了,用一张照片就能做出惟妙惟肖的 Memoji
等你来译:
强化学习的未来——第一部分
初学者怎样使用Keras进行迁移学习
强化学习:通往基于情感的行为系统
如果你想学数据科学,这 7 类资源千万不能错过
【AI求职百题斩】每日挑战又双叒叕更新啦,赶紧来看题吧!

想知道正确答案?
回公众号聊天界面并发送“1227挑战”即可获取!
点击 阅读原文 查看本文更多内容↙