NLP中的变形金刚
上回讲了当前DNN中较为较为广泛应用的一种算法机制——Attention Mechanisms,此机制在模型可解释性和模型优化方面均取得了不错的效果。那么今天,我们来进一步了解attention算法在自然语言中的更深层次的应用。本次我们介绍下自然语言处理的“变形金刚”——Transformer模型,该算法是近一年都比较热门的bert系列算法的基础。
2.Transformer模型
上回提到的attention机制可以认为是对RNN模型的一种进阶优化,其基础仍为RNN算法,针对RNN模型,存在一些不足的地方:
有一定的长期依赖问题:虽然利用门限等方法得到了有效的缓解,但是此问题依旧存在,并且句子越长,此问题越严重;
RNN有很大的性能问题:主要表现在训练阶段,如在RNN的前向计算中,每个隐藏状态Ht的计算,需要依赖Ht-1,Ht-2,...,无法做到像CNN那样的并行计算,尤其当数据量很大的情况下,此问题更为严重。
所以,如何更好的抽取文本的上下文信息,以及如何更好的提高计算性能,google的大神们在2017年提出了transformer算法,其利用self-attention的方法,完全摒弃掉RNN的结构,仅依赖attention的方式,构建了一种seq2seq的模型,可用于机器翻译等领域,取得了不错的效果,模型基本框架如图1所示:
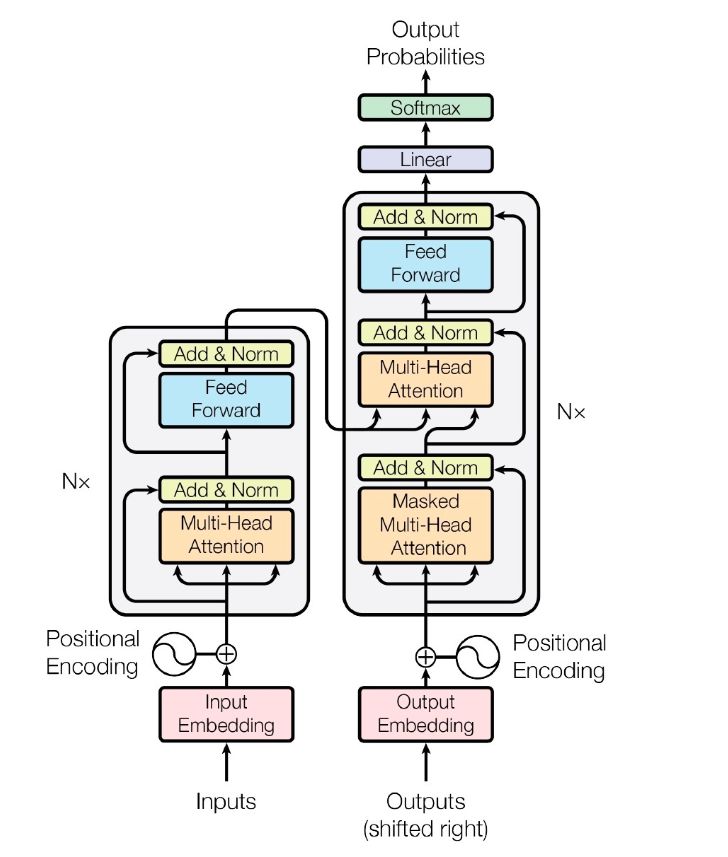
图1 transformer模型架构图
我们来具体看下transformer是如何计算的:
输入层:transformer输入包括两部分:每个词的embedding+位置encoding向量,使用时,将其整合在一起输入到模型中;
encoder和decoder层:encoder和decoder层的核心是利用attention的方式对输入进行编码和解码,此外两者中均加入残差网络的结构。
输出层:输出时,从左到右,先把右侧位置的元素遮挡掉,利用mask的attention方式进行训练预测。
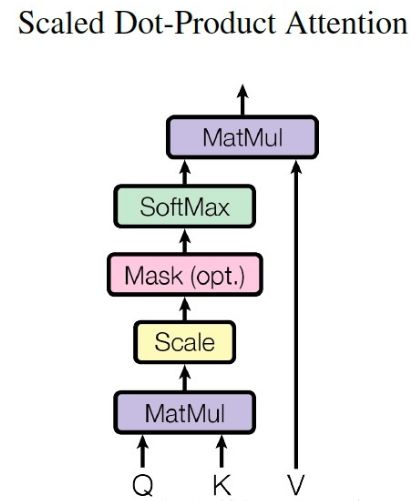
-
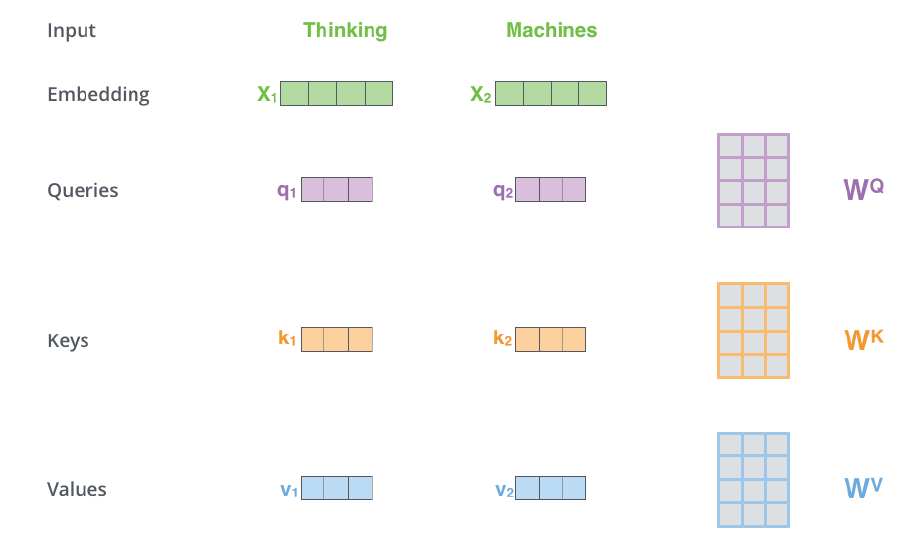
对于每个输入单词X1,X2,给定Wq,Wk,Wv三个矩阵,将x1和x2与这三个矩阵进行相乘,得到六个向量:q1、q2、k1、k2、v1、v2。其中这三个矩阵先随机初始给定,后面随模型训练不断迭代优化。
-
针对每一个单词,如第一个单词thinking,拿其q1与其他输入单词的k向量进行点乘得到各个score,s1=q1 * k1 ,s2=q1 * k2; -
对每个score进行归一化,保证梯度的稳定,同时除以sqrt(dk),其中dk为向量q,k,v的长度; -
利用softmax激活函数将score转化为权重w1,w2 -
加权求和得到各x的输出z,如z1=w1 * v1 + w2 * v2
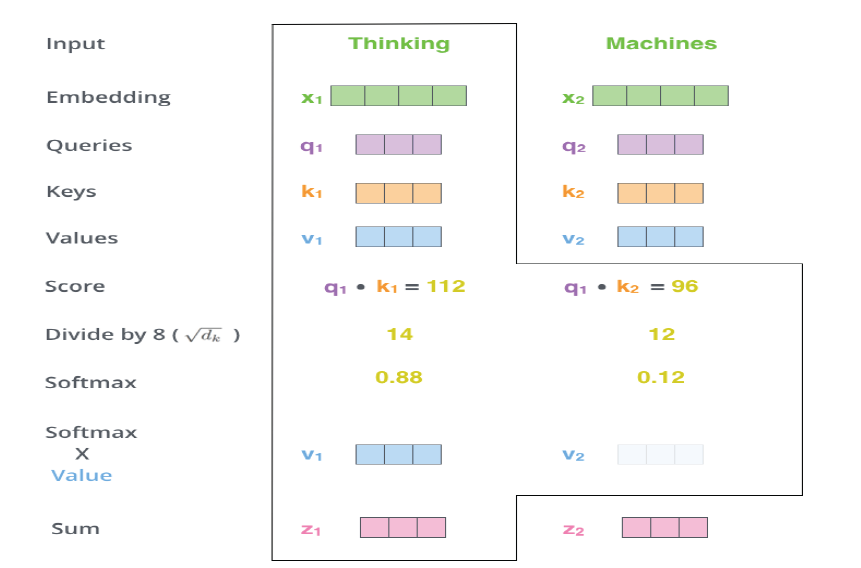

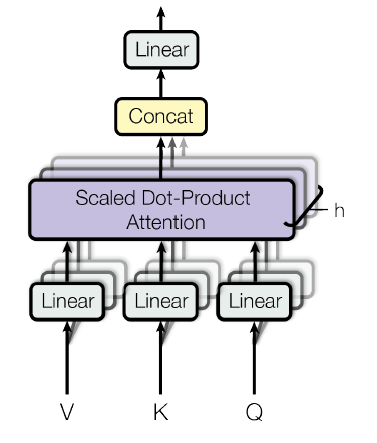
-
Add层:此处采用残差网络的设置,将原输入X与经attention计算得到的Z进行叠加,从而保证梯度不会消失,避免模型退化的发生; -
LayerNorm层:将数据标准化为均值为0,方差为1的数据,这样可以减小数据的偏差,规避训练过程中梯度消失或爆炸的情况。
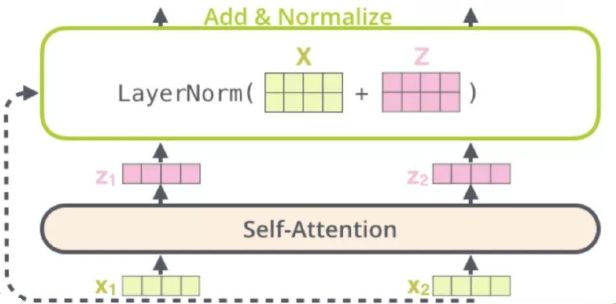
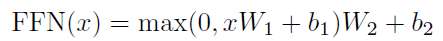
第三部分:Positional encoding
在我们之前使用CNN或者RNN模型进行文本建模时,模型内部已经考虑到序列的序列位置了,而上述的self-attention,仅可以认为是一个词袋模型,未考虑到词的位置信息。为了解决这个问题,此处在input中,除词语的embedding外,再额外添加位置编码信息,具体计算依据以下方式,主要依据sin和cos的方式锁定单词位置:
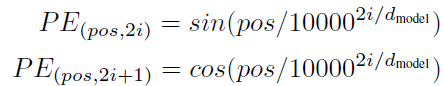
那么上述就是transformer模型的主要核心内容了,模型整体就是依据上述的几个部分进行重复、叠加与拼接。
3.展望
本文是对上次attention的后续,主要介绍了self-attention的基础理论部分,主要内容来源于google的《Attention Is All You Need》,此论文对于后续bert、gpt-2的理解具有极其重要的作用。
后期将介绍如何利用BERT预训练模型,进行文本建模实践。
本文转载自公众号:数据天团,作者丁永兵
推荐阅读
AI界最危险武器 GPT-2 使用指南:从Finetune到部署
T5 模型:NLP Text-to-Text 预训练模型超大规模探索
BERT 瘦身之路:Distillation,Quantization,Pruning
Transformer (变形金刚,大雾) 三部曲:RNN 的继承者
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLP君微信(id:AINLP2),备注工作/研究方向+加群目的。





