Highway Networks For Sentence Classification
声明:本文转载自公众号 黑龙江大学自然语言处理实验室,作者为该实验室研究生刘宗林,已获得授权。
导读:本文讨论了深层神经网络训练困难的原因以及如何使用Highway Networks去解决深层神经网络训练的困难,并且在pytorch上实现Highway Networks。
一 、Highway Networks与Deep Networks的关系
深层神经网络相比于浅层神经网络具有更好的效果,在很多方面都已经取得了很好的效果,特别是在图像处理方面已经取得了很大的突破,然而,伴随着深度的增加,深层神经网络存在的问题也就越大,像大家所熟知的梯度消失问题,这也就造成了训练深层神经网络困难的难题。2015年由Rupesh Kumar Srivastava等人受到LSTM门机制的启发提出的网络结构(Highway Networks)很好的解决了训练深层神经网络的难题,Highway Networks 允许信息高速无阻碍的通过深层神经网络的各层,这样有效的减缓了梯度的问题,使深层神经网络不在仅仅具有浅层神经网络的效果。
二、Deep Networks梯度消失/爆炸(vanishing and exploding gradient)问题
我们先来看一下简单的深层神经网络(仅仅几个隐层)
先把各个层的公式写出来:
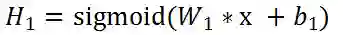
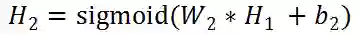
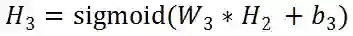
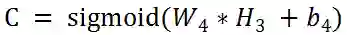
我们对W1求导:
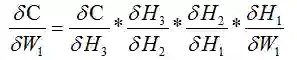
其中:
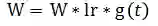
以上公式仅仅是四个隐层的情况,当隐层的数量达到数十层甚至是数百层的情况下,一层一层的反向传播回去,当权值 < 1的时候,反向传播到某一层之后权值近乎不变,相当于输入x的映射,例如,g(t) =〖0.9〗^100已经是很小很小了,这就造成了只有前面几层能够正常的反向传播,后面的那些隐层仅仅相当于输入x的权重的映射,权重不进行更新。反过来,当权值 > 1的时候,会造成梯度爆炸,同样是仅仅前面的几层能更改正常学习,后面的隐层会变得很大。
三、Highway Networks Formula
1. Notation
(.) 操作代表的是矩阵按位相乘
sigmoid函数:
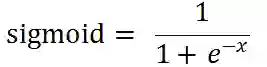
2. Highway Networks formula
对于我们普通的神经网络,用非线性激活函数H将输入的x转换成y,公式1忽略了bias。但是,H不仅仅局限于激活函数,也采用其他的形式,像convolutional和recurrent。
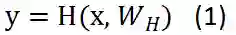
对于Highway Networks神经网络,增加了两个非线性转换层,一个是 T(transform gate) 和一个是 C(carry gate),通俗来讲,T表示输入信息经过convolutional或者是recurrent的信息被转换的部分,C表示的是原始输入信息x保留的部分 ,其中 T=sigmoid(wx + b) 。
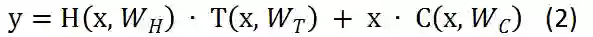
为了计算方便,这里定义了 C = 1 - T。
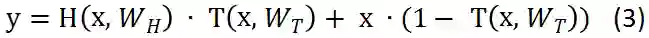
需要注意的是x,y, H, T的维度必须一致,要想保证其维度一致,可以采用sub-sampling或者zero-padding策略,也可以使用普通的线性层改变维度,使其一致。
几个公式相比,公式3要比公式1灵活的多,可以考虑一下特殊的情况,T= 0的时候,y = x,原始输入信息全部保留,不做任何的改变,T = 1的时候,Y = H,原始信息全部转换,不在保留原始信息,仅仅相当于一个普通的神经网络。
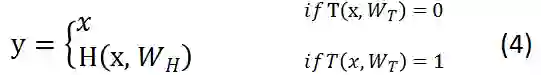
四、Highway BiLSTM Networks
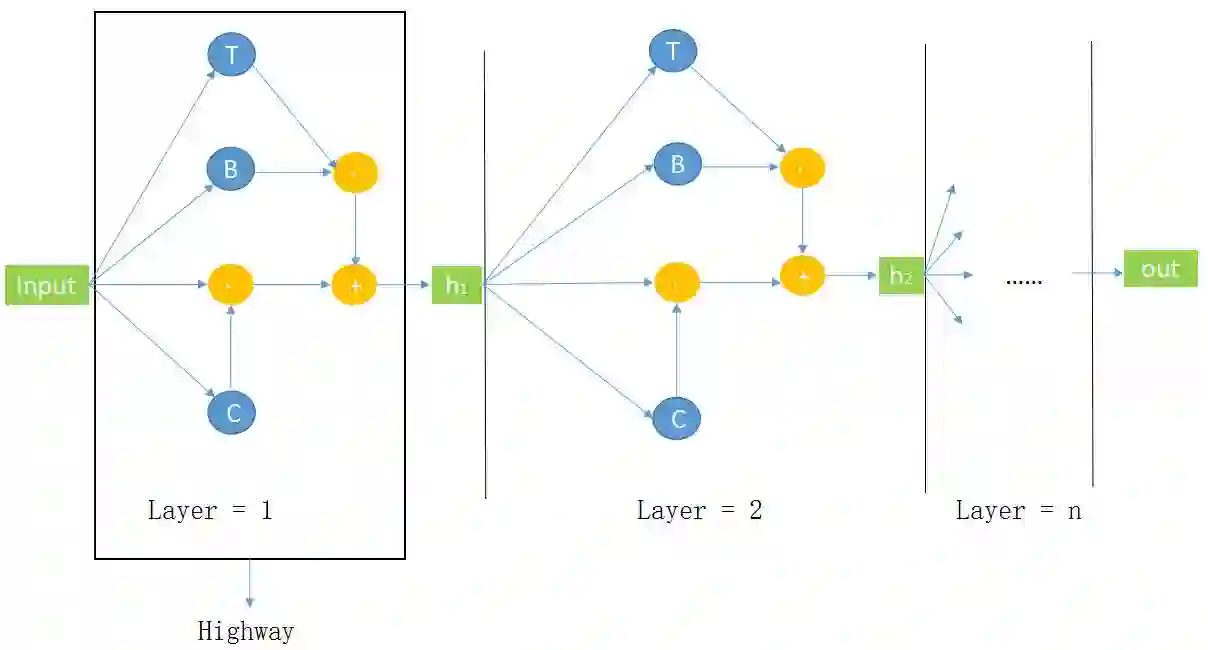
1. Highway BiLSTM Networks Structure Diagram
下图是 Highway BiLSTM Networks 结构图: input:代表输入的词向量;B:在本任务代表bidirection lstm,代表公式(2)中的 H;T:代表公式(2)中的 T,是Highway Networks中的transform gate;C:代表公式(2)中的 C,是Highway Networks中的carry gate;Layer = n,代表Highway Networks中的第n层;Highway:框出来的代表一层Highway Networks。在这个结构图中,Highway Networks第 n - 1 层的输出作为第n层的输入。
2. Highway BiLSTM Networks Demo
pytorch搭建神经网络一般需要继承nn.Module这个类,然后实现里面的forward()函数,搭建Highway BiLSTM Networks写了两个类,并使用nn.ModuleList将两个类联系起来:
class HBiLSTM(nn.Module):
def __init__(self, args):
super(HBiLSTM, self).__init__()
......
def forward(self, x):
# 实现Highway BiLSTM Networks的公式
...... class HBiLSTM_model(nn.Module):
def __init__(self, args):
super(HBiLSTM_model, self).__init__()
......
# args.layer_num_highway 代表Highway BiLSTM Networks有几层
self.highway = nn.ModuleList([HBiLSTM(args)
for _ in range(args.layer_num_highway)])
......
def forward(self, x):
......
# 调用HBiLSTM类的forward()函数
for current_layer in self.highway:
x, self.hidden = current_layer(x, self.hidden)在HBiLSTM类的forward()函数里面我们实现Highway BiLSTM Networks的的公式。首先我们先来计算H,上文已经说过,H可以是卷积或者是LSTM,在这里,normal_fc就是我们需要的H。
x, hidden = self.bilstm(x, hidden)
# torch.transpose是转置操作
normal_fc = torch.transpose(x, 0, 1)上文提及,x,y,H,T的维度必须保持一致,并且提供了两种策略,这里我们使用一个普通的Linear去转换维度。
source_x = source_x.contiguous()
information_source = source_x.view(source_x.size(0)
* source_x.size(1), source_x.size(2))
information_source = self.gate_layer(information_source)
information_source = information_source.view(source_x.size(0),
source_x.size(1), information_source.size(1))也可以采用zero-padding的策略保证维度一致。
# you also can choose the strategy that zero-padding
zeros = torch.zeros(source_x.size(0), source_x.size(1),
carry_layer.size(2) - source_x.size(2))
source_x = Variable(torch.cat((zeros, source_x.data), 2))维度一致之后我们就可以根据我们的公式来写代码了。
# transformation gate layer in the formula is T
transformation_layer = F.sigmoid(information_source)
# carry gate layer in the formula is C
carry_layer = 1 - transformation_layer
# formula Y = H * T + x * C
allow_transformation = torch.mul(normal_fc, transformation_layer)
allow_carry = torch.mul(information_source, carry_layer)
information_flow = torch.add(allow_transformation, allow_carry)最后的information_flow就是我们的输出,但是,还需要经过转换维度保证维度一致。
注:详细代码请参考Github: https://github.com/bamtercelboo/pytorch_Highway_Networks
五、Highway BiLSTM Networks 实验结果
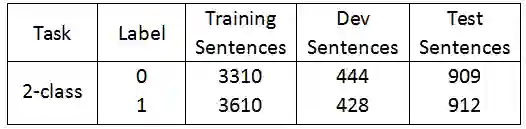
本次实验任务是使用Highway BiLSTM Networks 完成情感分类任务(一句话的态度分成积极或者是消极),数据来源于Twitter情感分类数据集,以下是数据集中的各个标签的句子个数:
下图是本次实验任务在2-class数据集中的测试结果。图中1-300在Highway BiLSTM Networks中表示Layer = 1,BiLSTM 隐层的维度是300维。
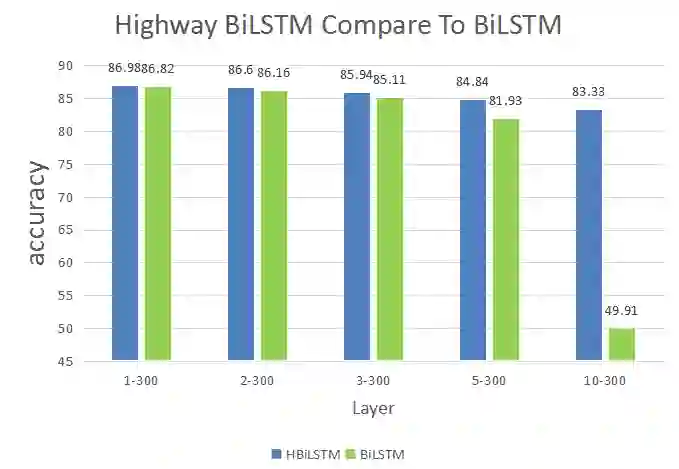
实验结果:从图中可以看出,简单的多层双向LSTM并没有带来情感分析性能的提升,尤其是是到了10层之后,效果有不如随机的猜测。当用上Highway Networks之后,虽然性能也在逐步的下降,但是下降的幅度有了明显的改善。
References
[1] R. K. Srivastava, K. Greff, and J. Schmidhuber. Highway networks. arXiv:1505.00387, 2015.
[2] R. K. Srivastava, K. Greff, and J. Schmidhuber. Training very deep networks. 1507.06228, 2015.
[3] Julian Georg Zilly, Rupesh Kumar Srivastava, Jan Koutník, and Jürgen Schmidhuber. Recurrent highway networks. arXiv preprint arXiv:1607.03474, 2016.
[4] X. Glorot and Y. Bengio. Understanding the difficulty of training deep feedforward neural networks. In AISTATS, 2010.
本期责任编辑: 张伟男
本期编辑: 蔡碧波
“哈工大SCIR”公众号
主编:车万翔
副主编: 张伟男,丁效
责任编辑: 张伟男,丁效,郭江,赵森栋
编辑: 李家琦,赵得志,赵怀鹏,吴洋,刘元兴,蔡碧波
长按下图并点击 “识别图中二维码”,即可关注哈尔滨工业大学社会计算与信息检索研究中心微信公共号:”哈工大SCIR” 。




