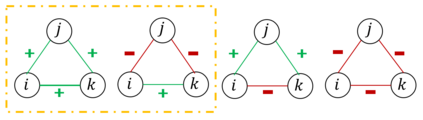
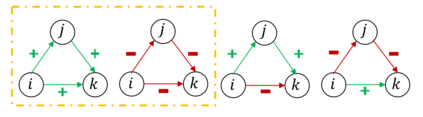
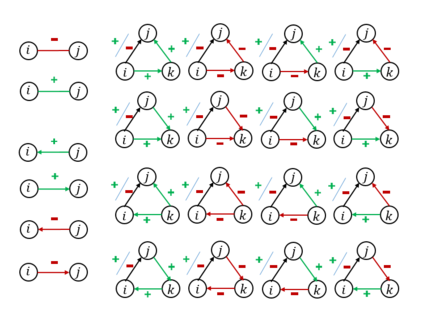
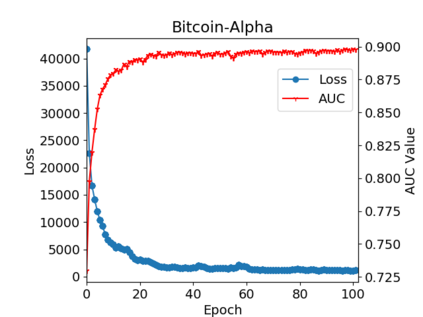
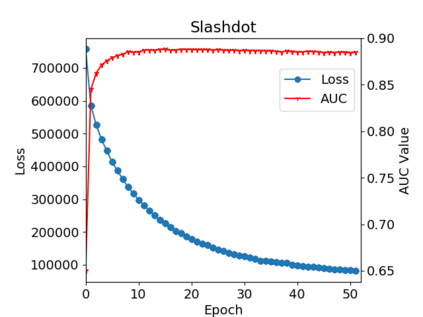
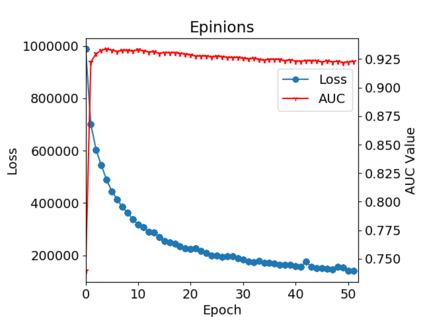
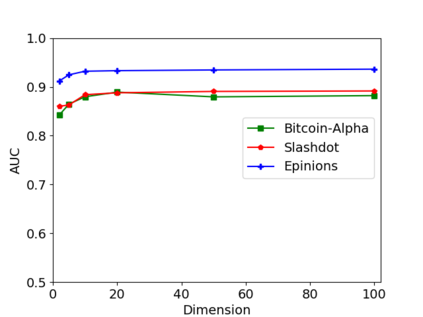
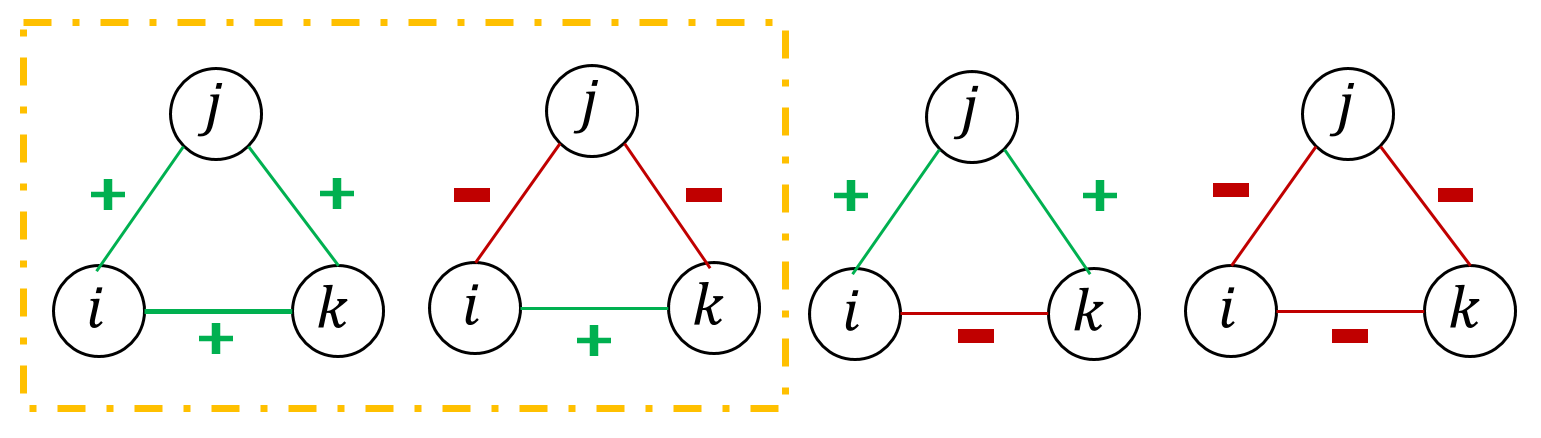
Graph or network data is ubiquitous in the real world, including social networks, information networks, traffic networks, biological networks and various technical networks. The non-Euclidean nature of graph data poses the challenge for modeling and analyzing graph data. Recently, Graph Neural Network (GNNs) are proposed as a general and powerful framework to handle tasks on graph data, e.g., node embedding, link prediction and node classification. As a representative implementation of GNNs, Graph Attention Networks (GATs) are successfully applied in a variety of tasks on real datasets. However, GAT is designed to networks with only positive links and fails to handle signed networks which contain both positive and negative links. In this paper, we propose Signed Graph Attention Networks (SiGATs), generalizing GAT to signed networks. SiGAT incorporates graph motifs into GAT to capture two well-known theories in signed network research, i.e., balance theory and status theory. In SiGAT, motifs offer us the flexible structural pattern to aggregate and propagate messages on the signed network to generate node embeddings. We evaluate the proposed SiGAT method by applying it to the signed link prediction task. Experimental results on three real datasets demonstrate that SiGAT outperforms feature-based method, network embedding method and state-of-the-art GNN-based methods like signed graph convolutional network (SGCN).
翻译:图表或网络数据在现实世界中无处不在,包括社交网络、信息网络、交通网络、生物网络和各种技术网络。但是,图形数据的非欧化性质对建模和分析图形数据构成挑战。最近,提出了图表神经网络(GNN)作为处理图形数据任务的一般和强大的框架,例如节点嵌入、链接预测和节点分类。作为GNNS、图关注网络(GATs)在真实数据集上成功应用的多种任务的代表性实施。然而,GAT是设计给网络的,只有已签字的正链接,无法处理含有正和负链接的已签字网络。在本文件中,我们提议签署图形关注网络(SiGATs),将GATs向已签字的网络概括化。SiGAT将图形模型模型纳入GAT,以在已签字的网络研究中捕捉到两个众所周知的理论,即平衡理论和现状理论。在SiGATAT中,我们用已签字的网络的缩略图模式向我们提供了一个灵活的结构模式,在已签字的网络上将SiSGAT 格式转换为不显示实际任务状态。