R语言数据清洗实战——世界濒危遗产地数据爬取案例

最近重复新翻阅R语言领域唯一一本关于网络数据采集的参考书——《基于R语言的自动数据收集》,开篇就是一个数据爬取的案例。
尽管之前已经粗略的看过一遍,但是仍感书中诸多细节不甚理解,还有平时过于眼高手低,第一遍看的时候只是动眼却不动手,案例几乎很少做过,准备刷第二遍,案例也打算仔仔细细的过一遍,做的时候才发现作者书中代码有些部分已经无法运行,还是需要自己去一点儿一点儿倒腾。
library("XML") library("stringr") library("RCurl") library("dplyr") library("rvest")以下是书中案例引用的世界濒危文化遗产名录的维基百科地址。
url<-"https://en.wikipedia.org/wiki/List_of_World_Heritage_in_Danger"经过自己尝试,作者书中的代码已经无法运行,这里我借助RCurl结合readHTMLTable函数完成了数据抓取,当然你也可以使用rvest会更方便一些。
heritage_parsed <- getURL(url,.encoding="utf-8") %>% readHTMLTable(stringAsFactors=FALSE)仔细查看第一部分内容的结构(是一个list体),里面嵌套有所有表格(数据框 ),确定我们需要的表格是第2、4两个。
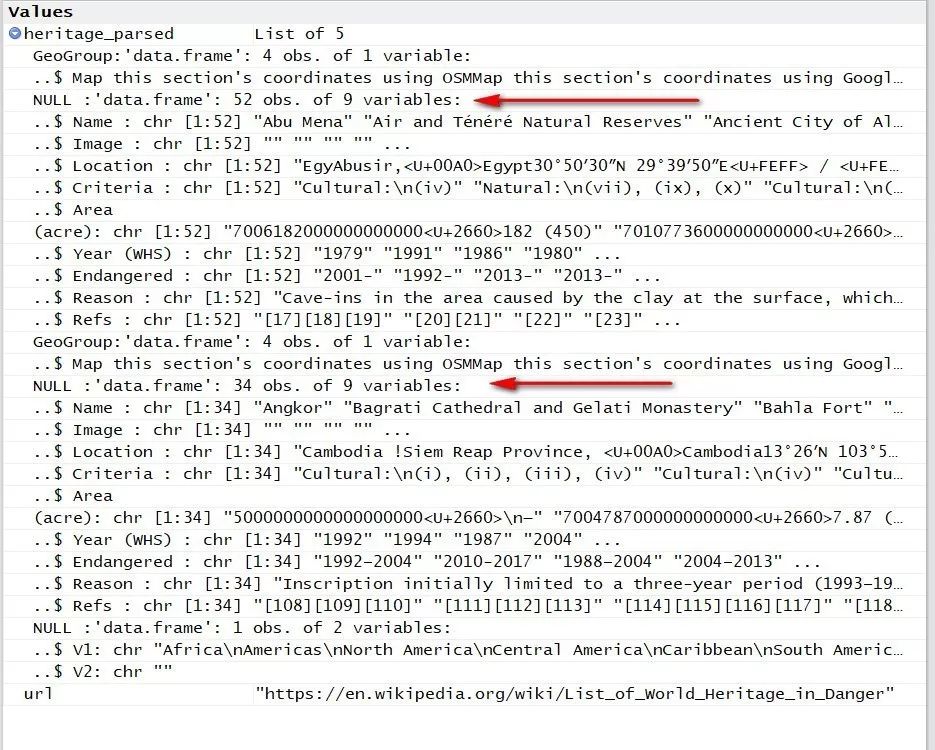
因为该网页有两份目标数据,所以需要分别提取,并直接剔除我们不需要的列。
heritage_Current<-heritage_parsed[[2]] %>% .[,setdiff(1:ncol(.),c(2,5,7,9))] heritage_Previous<-heritage_parsed[[4]] %>% .[,setdiff(1:ncol(.),c(2,5,7,9))]原始数据非常混乱,我使用stringr结合sapply函数,分别提取了遗产的所在地址、经纬度信息、类别信息等。以下函数除了sapply之外,我都在最近几篇的推送中有所涉及,特别是正则表达式在本次数据清洗中起到了很大的作用,如果你对正则还不太熟悉,可以参考这篇文化文章。
heritage_Current$Address<-heritage_Current$Location %>% strsplit(",") %>% sapply("[[",1) heritage_Current$lat<-heritage_Current$Location %>% str_extract("-?\\d{1,2}\\.\\d{1,}; -?\\d{1,3}\\.\\d{1,}") %>% strsplit(";") %>% sapply("[[",1) %>% as.numeric heritage_Current$long<-heritage_Current$Location %>% str_extract("-?\\d{1,2}\\.\\d{1,}; -?\\d{1,3}\\.\\d{1,}") %>% strsplit(";") %>% sapply("[[",2) %>% as.numeric heritage_Current$Criteria<-heritage_Current$Criteria %>% strsplit(":") %>% sapply("[[",1) heritage_Current<-heritage_Current[,c("Name","Criteria","Address","Year (WHS)","long","lat","Reason")] %>% rename("Year"="Year (WHS)") heritage_Current$Year<-as.numeric(heritage_Current$Year)因为两张表格内容格式一致,所以只是修改了表名,其他的没有任何改动。
heritage_Previous$Address<-heritage_Previous$Location %>% strsplit(",") %>% sapply("[[",1) heritage_Previous$lat<-heritage_Previous$Location %>% str_extract("-?\\d{1,2}\\.\\d{1,}; -?\\d{1,3}\\.\\d{1,}") %>% strsplit(";") %>% sapply("[[",1) %>% as.numeric heritage_Previous$long<-heritage_Previous$Location %>% str_extract("-?\\d{1,2}\\.\\d{1,}; -?\\d{1,3}\\.\\d{1,}") %>% strsplit(";") %>% sapply("[[",2) %>% as.numeric heritage_Previous$Criteria<-heritage_Previous$Criteria %>% strsplit(":") %>% sapply("[[",1) heritage_Previous<-heritage_Previous[,c("Name","Criteria","Address","Year (WHS)","long","lat","Reason")] %>% rename("Year"="Year (WHS)") heritage_Previous$Year<-as.numeric(heritage_Previous$Year)分列之后,是一个与原始向量等长的列表,每个列表对象是长度为2的向量。sapply函数在这里起到批量提取列表中单个对象第n个子对象的作用,因为strsplit函数按照“;”作为分隔符分列,这里“[[”其实是一个函数,详细用法参考?sapply文档说明。
列表是R里面最为自由、最为包容和灵活的数据对象,是R与外部非结构化数据通讯的唯一窗口,所以熟悉列表操作,是进阶R语言的必经阶段。
这里预览一下两个表格信息:
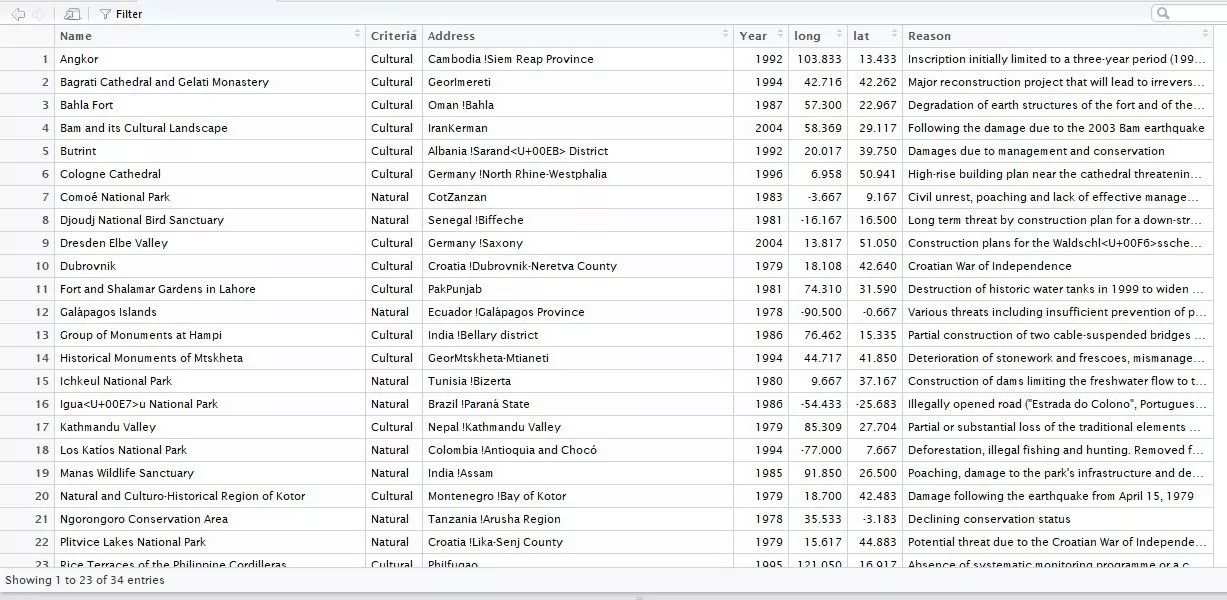

word<-"EgyAbusir,<U+00A0>Egypt30°50′30″N 29°39′50″E<U+FEFF> / <U+FEFF>30.84167°N 29.66389°E<U+FEFF> / 30.84167; 29.66389<U+FEFF> (Abu Mena)"针对上文中一处较长的正则表达式,我觉得这里有必要解析一下,我提取了原始字符串,这个字符串中末尾有一个“;”分割的两个浮点数值分别代表维度和经度,而且每一个文化遗产该项都是如此,也就是说符合模式匹配的需求,仔细观察最后的那两个数值间的模式。
左侧是维度,右侧是经度,维度取值范围-90~90,经度取值范围-180~180,小数点后保留的位数不确定,但是都大于1位数,经纬度之间间隔了分号和一个空格。
那么正则就应该写成 “-”(可能有可能没有)+1~2位数字+“.”+至少一位数字+“;”+空格+负号(可能有可能没有)+1~3位数字+“.”+至少一位数字。
使用正则表达式写出之后即为:
”-?\d{1,2}\.\d{1,}; -?\d{1,3}\.\d{1,}”
其中-?代表“-”可能存在可能不存在(?是一个限定符,限定左侧对象出现0次或者1次),\\.对“.”进行转义,因为“.”是一个具有特殊意义的元字符,可以指代任何一个对象。
str_extract(word,"-?\\d{1,2}\\.\\d{1,}; -?\\d{1,3}\\.\\d{1,}") [1] "30.84167; 29.66389"完美的匹配出来了,之后再做一次分列,然后分别提取经纬度就OK了。
原数书作者也是通过正则匹配的经纬度信息,不过使用的预留关键词,而是分了较多步骤,使用正则表达式做字符串清洗的过程就是这样,有无数种方式任你选择,只要达到目的即可,在目标达到的情况下,适当的选择自己熟悉并高效的方式。

可视化:
两个表格刚好有经纬度信息,还有遗产类别信息,可以借助这些信息进行可视化呈现,原书中使用maps包做的地图,我个人用惯了ggplot2,所以直接套用了老代码。
library("RColorBrewer") library("ggthemes") library("maps") library("ggplot2") world_map<-map_data("world")
#从maps包中提取世界地图。当前濒危遗产分布:
ggplot()+ geom_polygon(data=world_map,aes(x=long,y=lat,group=group),col="grey60",fill="white",size=.2,alpha=.4)+ geom_point(data=heritage_Current,aes(x=long,y=lat,shape=Criteria,fill=Criteria),size=3,colour="white")+ scale_shape_manual(values=c(21,22))+ scale_fill_wsj()+ labs(title="世界濒危文化遗产分布图(当前)",caption="数据来源:维基百科")+ theme_void(base_size=15) %+replace% theme( plot.title=element_text(size=25,hjust=0), plot.caption=element_text(hjust=0), legend.position = c(0.05,0.55), plot.margin = unit(c(1,0,1,0), "cm") )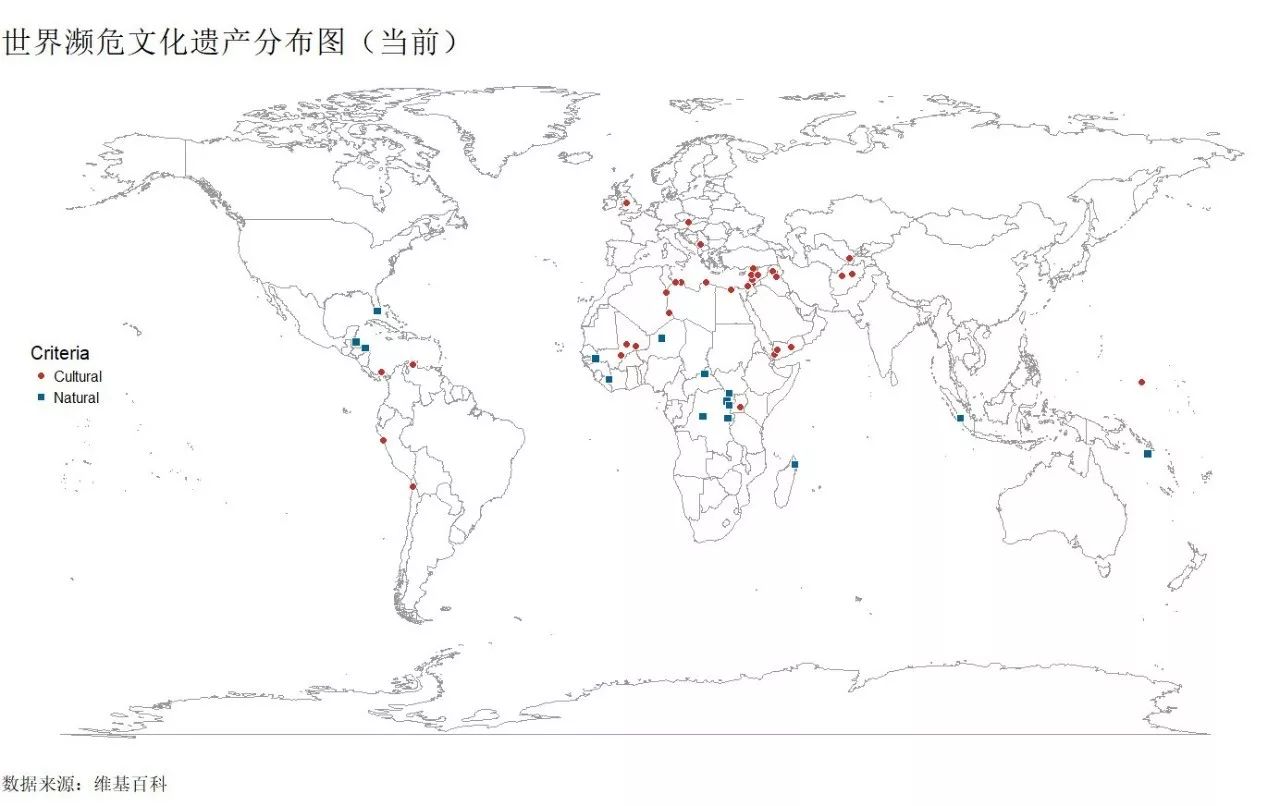
先前濒危遗产(后期经过保护又被从濒危遗产中除名了)。
ggplot()+ geom_polygon(data=world_map,aes(x=long,y=lat,group=group),col="grey60",fill="white",size=.2,alpha=.4)+ geom_point(data=heritage_Previous,aes(x=long,y=lat,shape=Criteria,fill=Criteria),size=3,colour="white")+ scale_shape_manual(values=c(21,22))+ scale_fill_wsj()+ labs(title="世界濒危文化遗产分布图(先前)",caption="数据来源:维基百科")+ theme_void(base_size=15) %+replace% theme( plot.title=element_text(size=25,hjust=0), plot.caption=element_text(hjust=0), legend.position = c(0.05,0.55), plot.margin = unit(c(1,0,1,0), "cm") )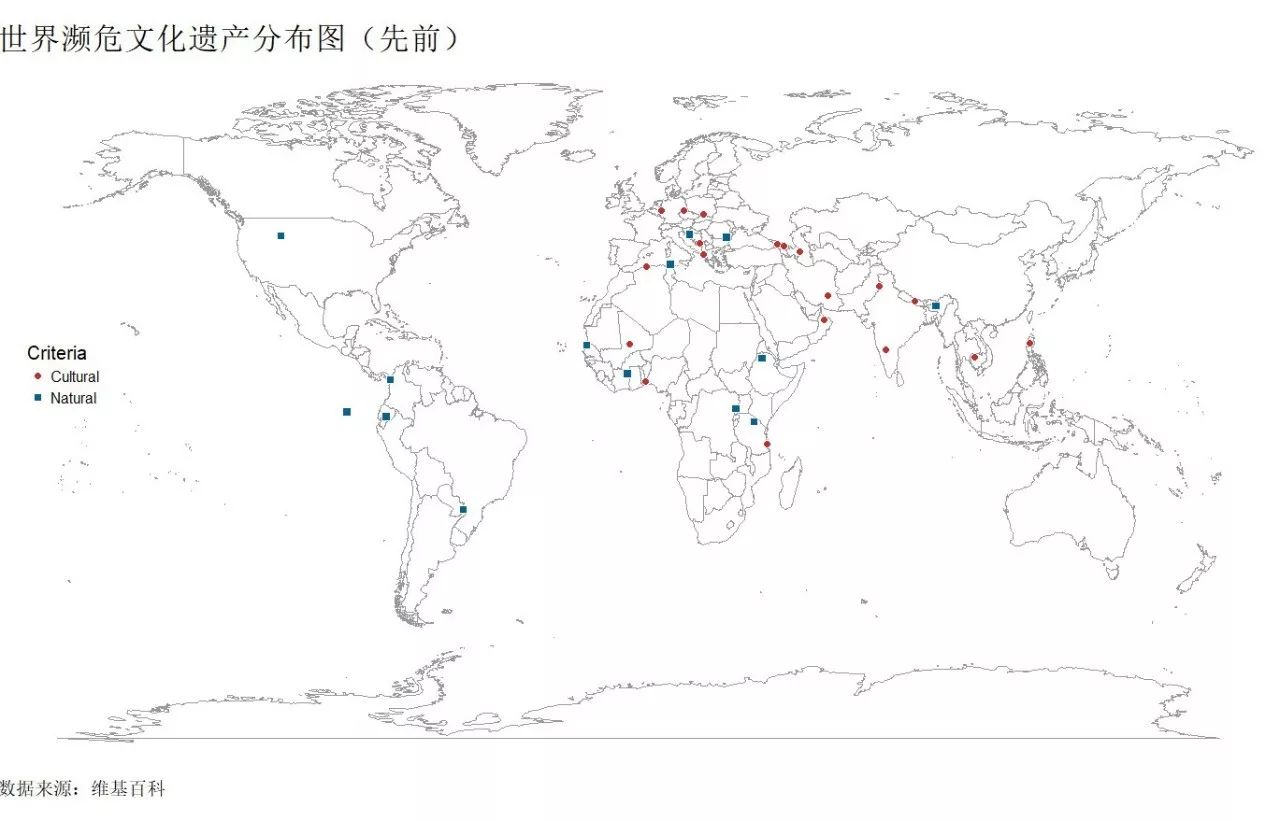
奇怪哦!怎么没有大天朝,难到我们的遗产全部都不濒危了,记得上次做的中国世界文化遗产分布图,有将近52除自然文化遗产,肯定维基百科给搞漏了。
相关课程推荐
R语言爬虫实战案例分享:
网易云课堂、知乎live、今日头条、B站视频
分享内容:本次课程所有内容及案例均来自于本人平时学习练习过程中的心得和笔记总结,希望借此机会,将自己的爬虫学习历程与大家分享,并为R语言的爬虫生态改善以及工具的推广,贡献一份微薄之力,也是自己爬虫学习的阶段性总结。

☟☟☟ 猛戳阅读原文,即刻加入课程。



