机器之心 & ArXiv Weekly Radiostation
本周主要论文包括MSU 联合 MIT-IBM 提出首个黑箱防御框架;CMU 提出首个快速知识蒸馏的视觉框架等研究。
目录
-
How to Robustify Black-Box ML Models? A Zeroth-Order Optimization Perspective
-
Language Models as Knowledge Embeddings
-
HorNet: Efficient High-Order Spatial Interactions with Recursive Gated Convolutions
-
Practical Lossless Federated Singular Vector Decomposition over Billion-Scale Data
-
No Free Lunch Theorem for Security and Utility in Federated Learning
-
Software-defined network assimilation: bridging the last mile towards centralized network configuration management with NAssim
-
A Fast Knowledge Distillation Framework for Visual Recognition
-
ArXiv Weekly Radiostation:NLP、CV、ML 更多精选论文(附音频)
论文 1:How to Robustify Black-Box ML Models? A Zeroth-Order Optimization Perspective
-
-
论文地址:https://openreview.net/forum?id=W9G_ImpHlQd
摘要:
这是密歇根州立大学 (Michigan State University) 和 MIT-IBM AI 实验室的一篇关于黑箱防御工作的文章,本文被 ICLR 2022 接收为 spotlight paper, 代码和模型均已开源。
本文主要研究了在只使用目标模型的输入和输出的情况下,如何进行黑箱防御。为了解决黑箱防御这个难题,本文将降噪平滑与零阶优化结合起来,提出了有效的且可扩展的 ZO-AE-DS 黑箱防御框架,这个框架有效地减少了零阶梯度估计的方差,进而缩减了零阶优化与一阶优化性能上的差距。
推荐
:MSU 联合 MIT-IBM 提出首个黑箱防御框架。
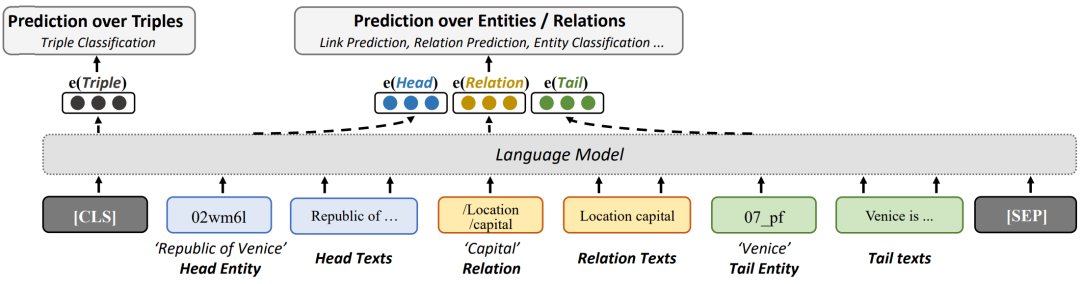
论文 2:Language Models as Knowledge Embeddings
-
-
论文地址:https://www.ijcai.org/proceedings/2022/0318.pdf
摘要:
本文提出了一个将语言模型用作知识嵌入的方法 LMKE(Language Models as Knowledge Embeddings),同时利用结构信息和文本信息,并首次将基于文本的知识嵌入学习建模在对比学习框架下,从而在提升长尾实体表示的同时解决了现有基于文本的知识嵌入方法在表现、效率等方面的不足。相关研究成果现已被 IJCAI 2022 录用。
推荐:
将语言模型用作知识嵌入:链接预测、三元组分类全部 SOTA,超越基于结构的传统方法。
论文 3:HorNet: Efficient High-Order Spatial Interactions with Recursive Gated Convolutions
-
-
论文地址:https://arxiv.org/abs/2207.14284
摘要:
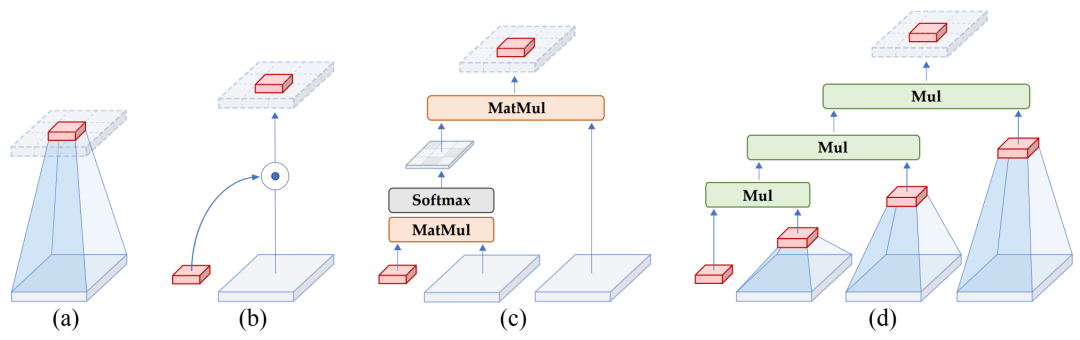
视觉 Transformer 的最新进展表明,在基于点积自注意力的新空间建模机制驱动的各种任务中取得了巨大成功。在本文中,作者证明了视觉 Transformer 背后的关键成分,即输入自适应、长程和高阶空间交互,也可以通过基于卷积的框架有效实现。作者提出了递归门卷积
![]() ,它用门卷积和递归设计进行高阶空间交互。新操作具有高度灵活性和可定制性,与卷积的各种变体兼容,并将自注意力中的二阶交互扩展到任意阶,而不引入显著的额外计算。
推荐:
用即插即用模块来改进各种视觉 Transformer 和基于卷积的模型。
论文 4:Practical Lossless Federated Singular Vector Decomposition over Billion-Scale Data
,它用门卷积和递归设计进行高阶空间交互。新操作具有高度灵活性和可定制性,与卷积的各种变体兼容,并将自注意力中的二阶交互扩展到任意阶,而不引入显著的额外计算。
推荐:
用即插即用模块来改进各种视觉 Transformer 和基于卷积的模型。
论文 4:Practical Lossless Federated Singular Vector Decomposition over Billion-Scale Data
-
-
论文地址:https://dl.acm.org/doi/abs/10.1145/3534678.3539402
摘要:
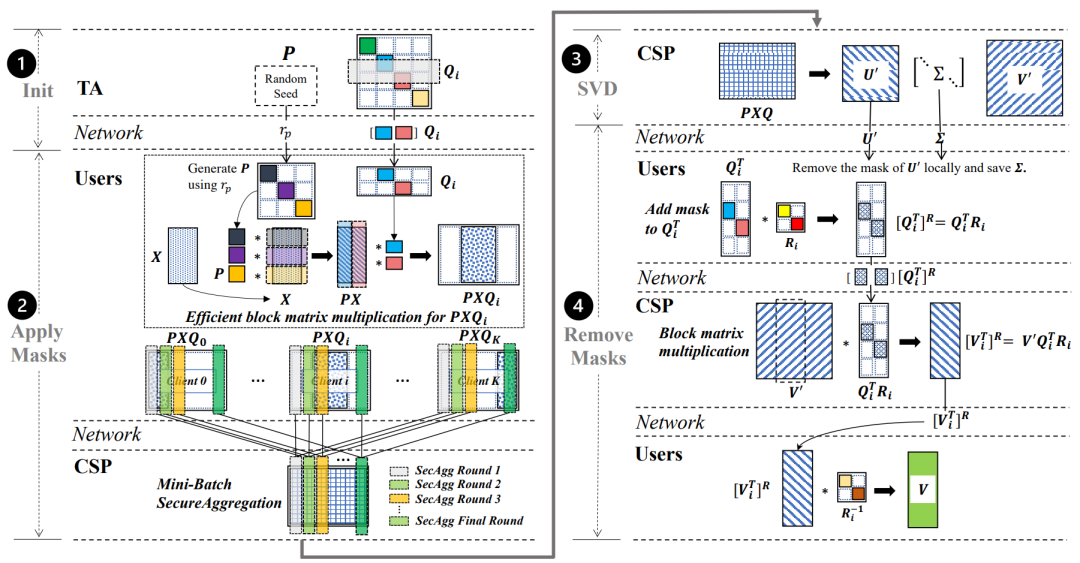
文章提出了基于随机掩码的奇异值分解方案,应用于多方生物数据分析、多方金融数据建模等场景,在 SVD 任务中,该方案的效率比同态加密提高 10000 倍,误差比差分隐私方案小 10 个数量级,同时提供了安全性分析和实验验证。
论文 5:No Free Lunch Theorem for Security and Utility in Federated Learning
-
-
论文地址:https://arxiv.org/pdf/2203.05816.pdf
摘要:
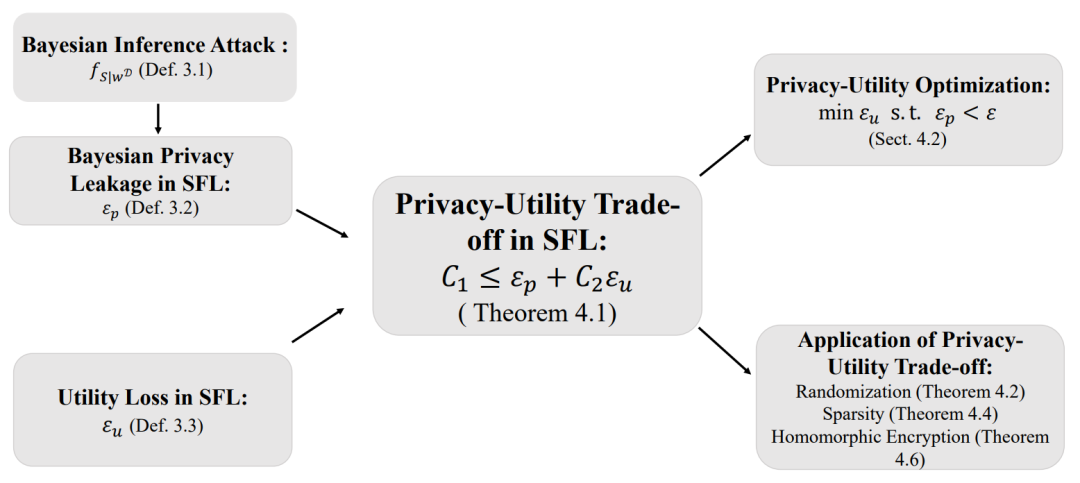
从信息论的角度为联邦学习中隐私泄漏和效用损失的分析提供了一个通用的框架,量化了隐私和效用之间的约束关系,揭示了隐私效用的无免费午餐场景,该论文阐述的框架及分析可以为设计可信联邦学习算法提供有效的指导。
基于贝叶斯推理攻击和隐私效用权衡的 SFL 框架概览。
推荐:
联邦学习中隐私与模型性能没有免费午餐定理。
论文 6:Software-defined network assimilation: bridging the last mile towards centralized network configuration management with NAssim
-
-
论文地址:https://dl.acm.org/doi/10.1145/3544216.3544244
摘要:
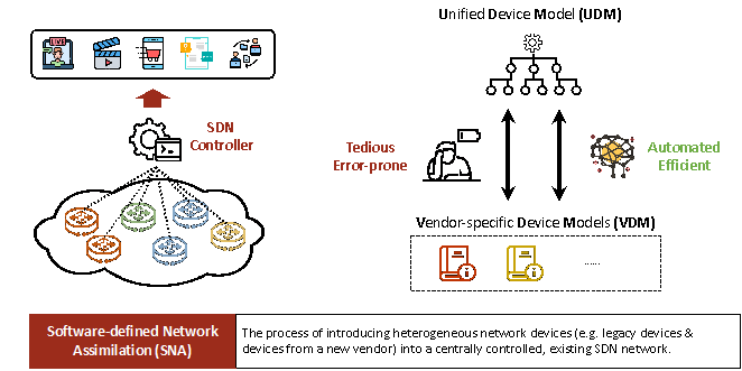
面向网络基础设施需要吸纳新设备的长期而持续的需求,高效准确获取设备原生配置模型和网络统一配置管理模型的映射关系是一个核心挑战。在 8 月 22 日 - 26 日举办的第 36 届 SIGCOMM 2022 会议上,华为的研究者针对这一难题提出了崭新的思路, 受生物学里的同化作用 Assimilation 的启发,首次提出了 SNA (Software-defined Network Assimilation)的概念。
研究者推出了助力网络配置管理最后一公里的辅助框架 NAssim,把一个现有网络 “消化、理解、吸收” 新设备的过程尽可能进行了自动化,并提出用网络配置语义模型 NetBERT 直接 “读懂” 配置说明书,把运维工程师从繁琐易出错的工作中解放出来,大幅提升网络运维的效率。目前该工作正在华为数通产品线进行落地试点。
推荐:
理论用于实践,华为配置管理研究获 SIGCOMM 2022 最佳论文奖。
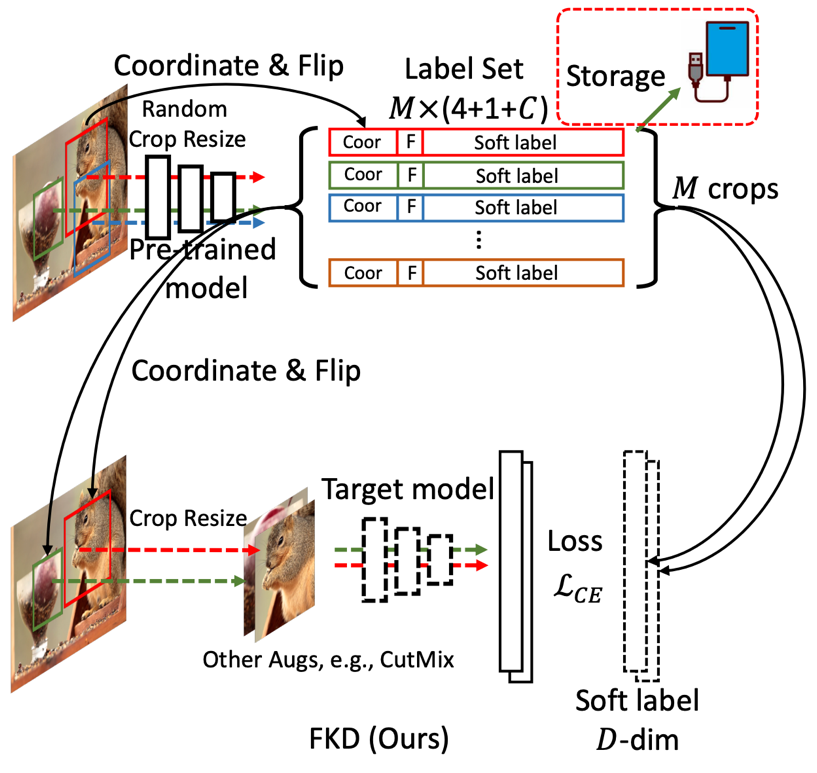
论文 7:A Fast Knowledge Distillation Framework for Visual Recognition
-
作者:Zhiqiang Shen、Eric Xing
-
论文地址:https://arxiv.org/pdf/2112.01528.pdf
摘要:
这是一篇来自卡耐基梅隆大学等单位 ECCV 2022 的一篇关于快速知识蒸馏的文章,用基本的训练参数配置就可以把 ResNet-50 在 ImageNet-1K 从头开始 (from scratch) 训练到 80.1% (不使用 mixup,cutmix 等数据增强),训练速度(尤其是数据读取开销)相比传统分类框架节省 16% 以上,比之前 SOTA 算法快 30% 以上,是目前精度和速度双双最优的知识蒸馏策略之一,代码和模型已全部开源!
推荐:
CMU 提出首个快速知识蒸馏的视觉框架:ResNet50 80.1% 精度,训练加速 30%。
ArXiv Weekly Radiostation
机器之心联合由楚航、罗若天发起的ArXiv Weekly Radiostation,在 7 Papers 的基础上,精选本周更多重要论文,包括NLP、CV、ML领域各10篇精选,并提供音频形式的论文摘要简介,详情如下:
1. A Survey on Text-to-SQL Parsing: Concepts, Methods, and Future Directions. (from Jian Sun)
2. Searching for Structure in Unfalsifiable Claims. (from Serge Belongie)
3. Debiasing Word Embeddings with Nonlinear Geometry. (from Huan Liu)
4. Incorporating Task-specific Concept Knowledge into Script Learning. (from ChengXiang Zhai)
5. StoryTrans: Non-Parallel Story Author-Style Transfer with Discourse Representations and Content Enhancing. (from Minlie Huang)
6. Streaming Intended Query Detection using E2E Modeling for Continued Conversation. (from Tara N. Sainath)
7. Turn-Taking Prediction for Natural Conversational Speech. (from Tara N. Sainath)
8. Bayesian Neural Network Language Modeling for Speech Recognition. (from Xunying Liu)
9. Optimizing Bi-Encoder for Named Entity Recognition via Contrastive Learning. (from Jianfeng Gao)
10. AutoQGS: Auto-Prompt for Low-Resource Knowledge-based Question Generation from SPARQL. (from Xiaodong He)
1. Synthetic Latent Fingerprint Generator. (from Anil K. Jain)
2. CounTR: Transformer-based Generalised Visual Counting. (from Andrew Zisserman)
3. Visual Prompting via Image Inpainting. (from Trevor Darrell, Alexei A. Efros)
4. Uncertainty-Induced Transferability Representation for Source-Free Unsupervised Domain Adaptation. (from Liang Chen, Yang Liu)
5. Grounded Affordance from Exocentric View. (from Dacheng Tao)
6. Learning Continuous Implicit Representation for Near-Periodic Patterns. (from Martial Hebert, Srinivasa G. Narasimhan)
7. Compound Figure Separation of Biomedical Images: Mining Large Datasets for Self-supervised Learning. (from Agnes B. Fogo)
8. Probing Contextual Diversity for Dense Out-of-Distribution Detection. (from Thomas Brox)
9. GaitFi: Robust Device-Free Human Identification via WiFi and Vision Multimodal Learning. (from Lihua Xie)
10. Towards In-distribution Compatibility in Out-of-distribution Detection. (from Deng Cai, Xiaofei He, Wei Liu)
1. A Self-supervised Riemannian GNN with Time Varying Curvature for Temporal Graph Learning. (from Philip S. Yu)
2. Learning with Few Labeled Nodes via Augmented Graph Self-Training. (from Huan Liu)
3. NeurIPS'22 Cross-Domain MetaDL competition: Design and baseline results. (from Isabelle Guyon)
4. RUAD: unsupervised anomaly detection in HPC systems. (from Luca Benini)
5. Autoinverse: Uncertainty Aware Inversion of Neural Networks. (from Hans-Peter Seidel)
6. Dynamic Regret of Online Markov Decision Processes. (from Zhi-Hua Zhou)
7. Super-model ecosystem: A domain-adaptation perspective. (from Dacheng Tao)
8. Trading Off Privacy, Utility and Efficiency in Federated Learning. (from Kai Chen)
9. Overparameterized (robust) models from computational constraints. (from Somesh Jha)
10. Fundamentals of Task-Agnostic Data Valuation. (from Ramesh Raskar)
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com

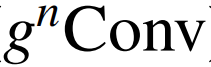 ,它用门卷积和递归设计进行高阶空间交互。新操作具有高度灵活性和可定制性,与卷积的各种变体兼容,并将自注意力中的二阶交互扩展到任意阶,而不引入显著的额外计算。
,它用门卷积和递归设计进行高阶空间交互。新操作具有高度灵活性和可定制性,与卷积的各种变体兼容,并将自注意力中的二阶交互扩展到任意阶,而不引入显著的额外计算。