
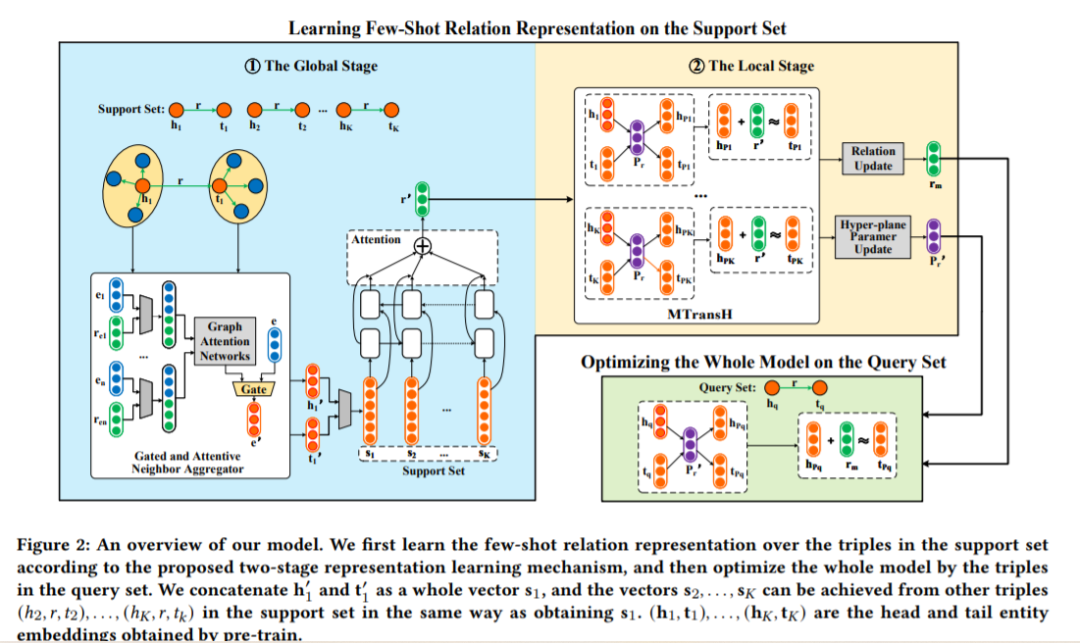
为了扩大知识图谱中少样本关系的覆盖范围,近年来少样本知识图谱补全(FKGC)得到了越来越多的研究兴趣。现有的模型利用了一种多跳关系的邻居信息来增强其语义表示。但是,当邻域过于稀疏,没有邻域来表示少射关系时,噪声邻域信息可能会被放大。此外,以往的知识图谱补全方法对多对多(1-N)、多对一(N-1)、多对多(N-N)等复杂关系进行建模和推断需要较高的模型复杂度和大量的训练实例。因此,由于训练实例有限,FKGC模型很难在少样本场景下推断复杂关系。本文提出了一种全局-局部框架下的少样本关系学习方法来解决上述问题。在全局阶段,构建了一种新颖的门控和专注邻居聚合器,用于精确集成几个样本关系的邻域的语义,这有助于过滤噪声邻域,即使一个KG包含非常稀疏的邻域。对于局部阶段,我们设计了一种基于元学习的TransH (MTransH)方法来建模复杂关系,并以少量学习的方式训练模型。大量实验表明,我们的模型在常用的基准数据集NELL-One和Wiki-One上的性能优于先进的FKGC方法。与强基线模型MetaR相比,我们的模型通过度量Hits@10在NELL-One上实现了8.0%的5次FKGC性能改进,在Wiki-One上实现了2.8%
https://www.zhuanzhi.ai/paper/94d6afca9acf028db665ffb6575b7c34
成为VIP会员查看完整内容
相关内容

知识图谱(Knowledge Graph),在图书情报界称为知识域可视化或知识领域映射地图,是显示知识发展进程与结构关系的一系列各种不同的图形,用可视化技术描述知识资源及其载体,挖掘、分析、构建、绘制和显示知识及它们之间的相互联系。
知识图谱是通过将应用数学、图形学、信息可视化技术、信息科学等学科的理论与方法与计量学引文分析、共现分析等方法结合,并利用可视化的图谱形象地展示学科的核心结构、发展历史、前沿领域以及整体知识架构达到多学科融合目的的现代理论。它能为学科研究提供切实的、有价值的参考。
Arxiv
19+阅读 · 2019年11月20日
相关主题

相关VIP内容
相关资讯
相关论文
Arxiv
19+阅读 · 2019年11月20日