
《Auto-Sizing the Transformer Network: Improving Speed, Efficiency, and Performance for Low-Resource Machine Translation》K Murray, J Kinnison, T Q. Nguyen, W Scheirer, D Chiang [University of Notre Dame] (2019)
成为VIP会员查看完整内容

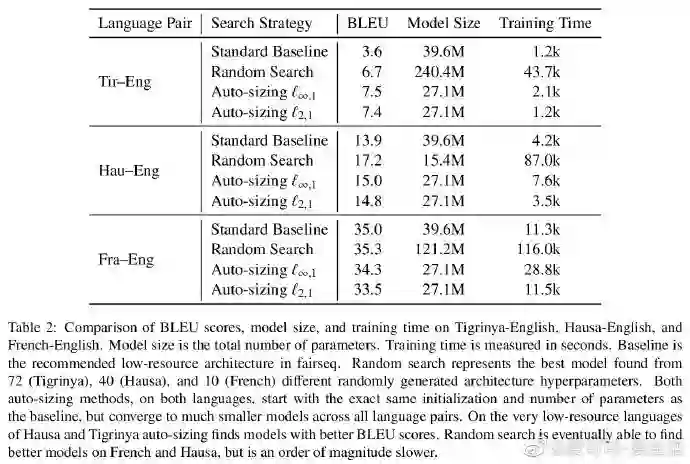
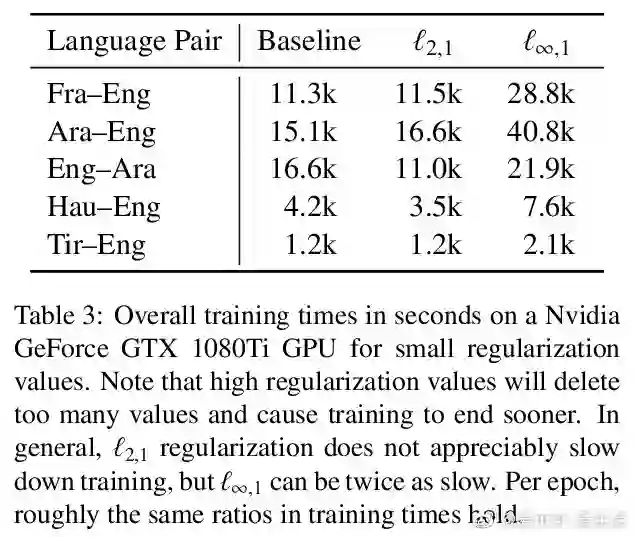

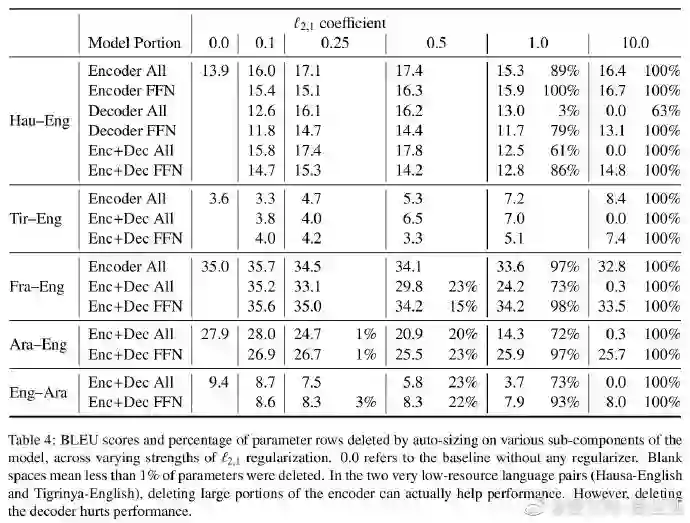
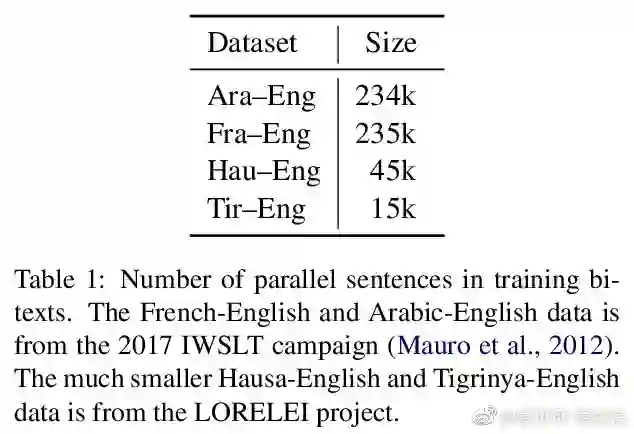
相关内容

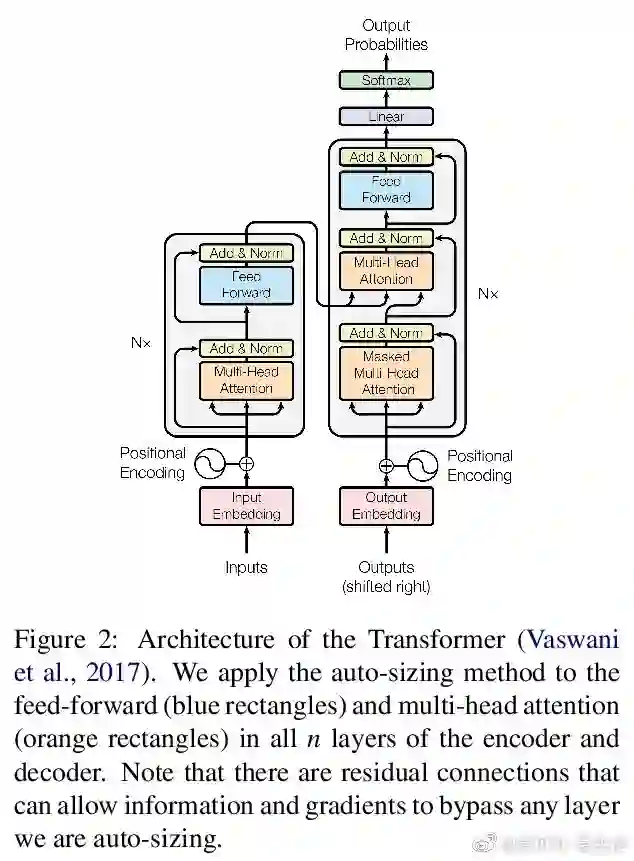
Transformer是谷歌发表的论文《Attention Is All You Need》提出一种完全基于Attention的翻译架构
专知会员服务
54+阅读 · 2020年1月30日
专知会员服务
36+阅读 · 2019年10月17日
相关主题

相关VIP内容
专知会员服务
54+阅读 · 2020年1月30日
专知会员服务
36+阅读 · 2019年10月17日
相关资讯
相关论文