深度学习下的医学图像分析(四)

欢迎大家参与在留言区交流
本周内(截止至7月23日晚24点)
本公众号本周发布的所有文章,留言获赞最多者
AI研习社送西瓜书
AI研习社 按:本文由图普科技编译自《Medical Image Analysis with Deep Learning Part4》,是最近发表的《深度学习下的医学图像分析(三)》的后续文章。
对与深度学习相关的医疗保障工作而言,2017 年的 “Nvidia GTC 大会” 绝对是一个绝佳的信息来源。在大会上,有诸如 Ian GoodFellow 和 Jeremy Howard 的深度学习专家分享了他们对深度学习的见解;还有一些顶级医学院(例如西奈山医学院、纽约大学医学院、麻省综合医院等)和 Kaggle 在大会上介绍他们的建模战略。
在上一篇文章中,我们谈论了深度学习相关的基本内容。本文,我们将关注于医学图像及其格式。
本文分为三个部分——医学图像及其组成、医学图像格式和医学图像的格式转换。本文希望通过对深度学习的相关知识的介绍,最终达到医学图像分析的目的。
医学图像及其组成
由 Michele Larobina 和 Loredana Murino 发表的论文,对本文即将展开的讨论来说是一个很好的信息参考。Michele Larobina 和 Loredana Murino 二人是意大利 “生物架构和生物成像协会”(IBB)的成员。IBB 是意大利 “国家研究委员会” 的组成部分,同时也是意大利最大的公共研究机构。我们的另一个参考信息资源是一篇题为《Working with the DICOM and NIfTI data standards in R》的论文。
什么是医学图像?
医学图像是反映解剖区域内部结构或内部功能的图像,它是由一组图像元素——像素(2D)或立体像素(3D)——组成的。医学图像是由采样或重建产生的离散性图像表征,它能将数值映射到不同的空间位置上。像素的数量是用来描述某一成像设备下的医学成像的,同时也是描述解剖及其功能细节的一种表达方式。像素所表达的具体数值是由成像设备、成像协议、影像重建以及后期加工所决定的。
医学图像的组成
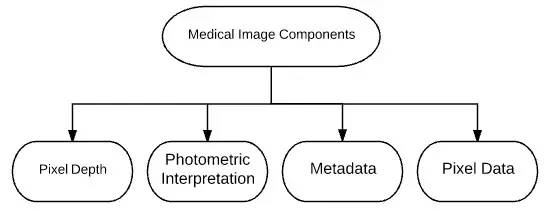
医学图像组成 医学图像有四个关键成分——像素深度、光度表示、元数据和像素数据。这些成分与图像大小和图像分辨率有关。
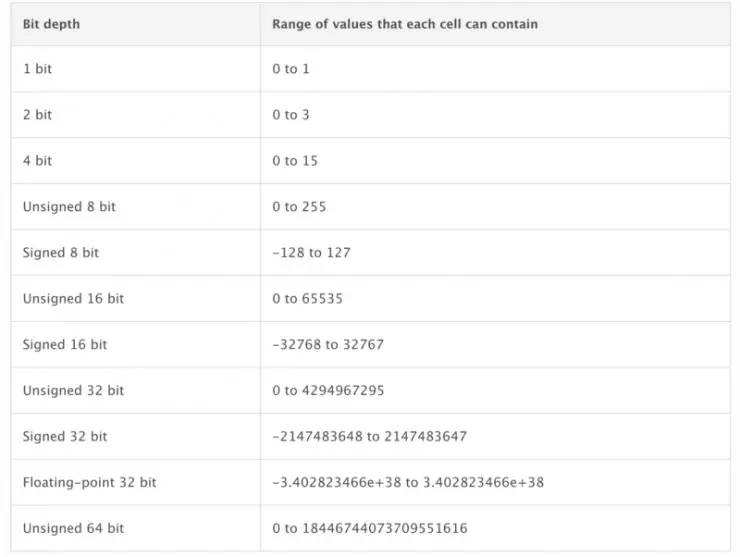
图像深度(又称比特深度或颜色深度)是用来编码每个像素信息的比特数。比如说,一个 8 比特的光栅可以有 256 个从 0 到 255 数值不等的图像深度。
“光度表示” 解释了像素数据如何以正确的图像格式(单色或彩色图片)显示。为了说明像素数值中是否存在色彩信息,我们将引入 “每像素采样数” 的概念。单色图像只有一个 “每像素采样”,而且图像中没有色彩信息。图像是依靠由黑到白的灰阶来显示的,灰阶的数目很明显取决于用来储存样本的比特数。在这里,灰阶数与像素深度是一致的。医疗放射图像,比如 CT 图像和磁共振(MR)图像,是一个灰阶的 “光度表示”。而核医学图像,比如正电子发射断层图像(PET)和单光子发射断层图像(SPECT),通常都是以彩色映射或调色板来显示的。
“元数据” 是用于描述图形象的信息。它可能看起来会比较奇怪,但是在任何一个文件格式中,除了像素数据之外,图像还有一些其他的相关信息。这样的图像信息被称为 “元数据”,它通常以 “数据头” 的格式被储存在文件的开头,涵盖了图像矩阵维度、空间分辨率、像素深度和光度表示等信息。
“像素数据” 是储存像素数值的位置。根据数据类型的不同,像素数据使用数值显示所需的最小字节数,以整点或浮点数的格式储存。 图像大小 = 数据头大小(包括元数据)+ 行数 栏数 * 像素深度 *(图像帧数)
医学图像格式
放射图像有 6 种主要的格式,分别为 DICOM(医学数字成像和通讯)、NIFTI(神经影像信息技术)、PAR/REC(Philips 磁共振扫描格式)、ANALYZE(Mayo 医学成像)、NRRD(近原始栅格数据)和 MNIC。
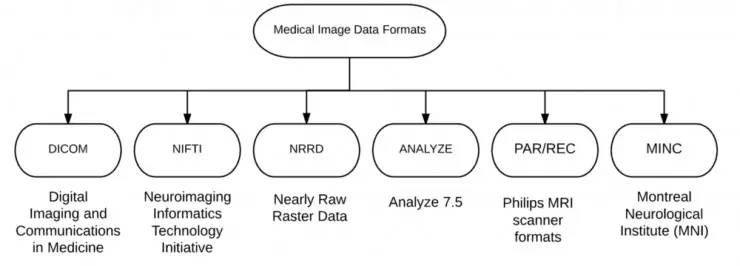
在上图的五个格式中,DICOM 和 NIFTI 是接受度最高的。
DICOM 格式的基本内容
DICOM 表示 “医学数字成像和通讯”。DICOM 是由 “美国国家电气制造商协会”(NEMA)发布的标准,这一标准规范了医学成像的管理、储存、打印和信息传输,这些都是扫描仪或医院 “医疗影像储传系统”(PACS)中的文件格式。 DICOM 包括了一个文件格式和一个网络通讯协议,其中的网络通讯协议是医疗实体间使用 TCP/IP 进行沟通的一个规范和准则。 一个 DICOM 文件由一个数据头和图像数据组成的。数据头的大小取决于数据信息的多少。数据头中的内容包括病人编号、病人姓名等等。同时,它还决定了图像帧数以及分辨率。这是图片查看器用于显示图像的。即使是一个单一的图像获取,都会有很多 DICOM 文件。
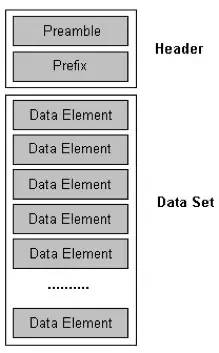
来源: https://www.leadtools.com/sdk/medical/dicom-spec1
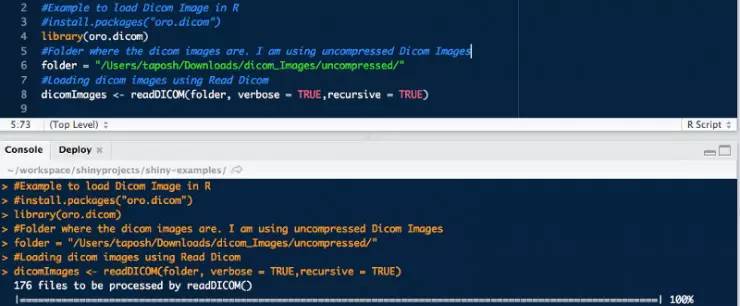
Pydicom 是用于读取 DICOM 文件的 Python 库,详情请参阅文本第一部分的代码示例。 “oro.dicom” 是用于读取 DICOM 数据的 R-package。
NIFTI 格式的基本内容
“神经成像信息技术创新” 将 NIFTI 格式视为 ANALYZE7.5 格式的替代品。NIFTI 最初是用于神经成像的,但它也适用于一些其他的领域。NIFTI 中一个主要的特点在于它包含了两个仿射坐标定义,这两个仿射坐标定义能够将每个立体元素指标(i,j,k)和空间位置(x,y,z)联系起来。 Nibabel 是用于读取 nifti 文件的一个朋友 Python 库,“oro.nifti” 是用于读取 nifti 数据的一个 R 工具包。
DICOM 和 NIFTI 间的区别
DICOM 和 NIFTI 之间最主要的区别在于 NIFTI 中的原始图像数据是以 3D 图像的格式储存的,而 DICOM 是以 3D 图像片段的格式储存的。这就是为什么在一些机器学习应用程序中 NIFTI 比 DICOM 更受欢迎,因为它是 3D 图像模型。处理一个单个的 NIFTI 文件,与处理上百个 DICOM 文件相比要轻松得多。NIFTI 的每一张 3D 图像中只需储存两个文件,而在 DICOM 中则要储存更多文件。
NRRD 格式的基本内容
灵活的 NRRD 格式中包含了一个单个的数据头文件和既能分开又能合并的图像文件。一个 NRRD 数据头能够为科学可视化和医学图像处理准确地表示 N 维度的栅格信息。“国家医学图像计算联盟”(NA-MIC)开发了一种用 NRRD 格式来表示 “扩散加权图像”(DWI)和 “扩散张量图像”(DTI)的方法。NRRD 的 “扩散加权图像” 和 “扩散张量图像” 数据可以被解读为一个 “3D 切片机”,能够直观地确定张量图像的方向与神经解剖的预期是一致的。 一个 NRRD 文件的大致格式(带有数据头)如下图所示:

来源 http://teem.sourceforge.net/nrrd/format.html#general.1
MINC 格式的基本内容
MINC 代表的是 “医学成像 NetCDF 工具包”。MINC 文件格式的开发始于 1992 年 “蒙特利神经研究所”(MNI)。目前,McGill 的 “脑成像中心”(BCI)正积极地对 MINC 进行进一步开发。MINC 格式的第一个版本(Minc1)是建立在标准的 “网络常见格式”(NetCDF)之上的;而第二个版本的 MINC 格式,即 Minc2,则是以 “分级数据格式第五版”(HDF5)为基础建立的。HDF5 支持无限制的多种数据类型,它适用于灵活高效的 I/O 和高容量、复杂的数据。正是有了这些新的特性和功能,Minc2 才能处理大量的、复杂的数据库。 以下是一些研究性论文针对这些格式数据头所作的比较:
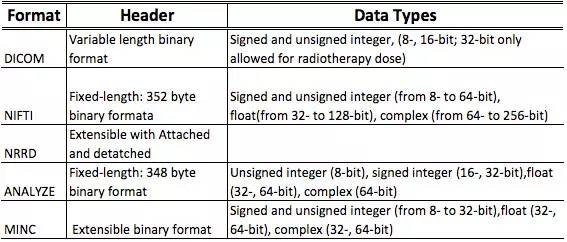
来源:出版于 2014 年的《医学图像格式》
格式转换
从 DICOM 格式转换为 NIFTI 格式
dicom2nii 是将 DICOM 格式转换为 NIFTI 格式的常见工具。一个读取和编写 NIFTI 文件的 Python 库是 nibabel。如果想要将 DICOM 格式转换为 NIFTI 格式,有很多自动转换的工具,比如 dcm2nii。Python2 的 “dcmstack” 能让一系列 DICOM 图像堆叠成多维度的数组,这些数组能够被编写为带有 “数据头扩展”(DcmMeta 扩展)的 NIFTI 文件,其中的 “数据头扩展” 其实就是一份 DICOM 文件元数据的摘要。
由 DICOM 格式转换为 MINC 格式
BIC 的 MINC 团队开发了一种将 DICOM 转换为 MINC 图像的工具,这个程序是用 C 语言编写的,点击此链接查看 github 报告。 由 NIFTI 或 ANALYZE 转换为 MINC 格式 在 BIC 的 MINC 团队开发了另外一种能够将 NIFTI 或 ANALYZE 图像转换为 MINC 图像的工具,这个程序叫做 nii2mnc。点击此链接查看包括 nii2mnc 在内的一系列转换工具。
总结
我们在本文介绍了好几种可以用于储存成像和深度学习的格式。我们的目标就是利用最佳的格式,让我们的卷积神经网络作出准确的预测。
在下一篇文章中,我们将讨论如何利用其中一种格式从 CT 扫描图像中进行肺部切割。
---------------------------
福利
关注 AI 研习社(okweiwu)
回复「1」立即领取
【超过 1000G 神经网络/AI/大数据、教程、论文!】
推荐阅读
《手把手教你如何用 Python 做情感分析》
话题讨论
图像分析在哪些领域会有大规模应用?
欢迎在评论区分享
↓↓↓


