开发 | 一文详解 Word2vec 之 Skip-Gram 模型(实现篇)
300 + 明星创业公司,3000 + 行业人士齐聚全球人工智能与机器人峰会 GAIR 2017,一 同见证 AI 浪潮之巅!峰会抢票火热进行中。
今天特放出 直减 700 元的无条件优惠码(见文末,优惠幅度逐天减小),感谢各位读者对雷锋网的支持,打开链接即可使用。
AI 科技评论按:这是一个关于 Skip-Gram 模型的系列教程,依次分为结构、训练和实现三个部分,本文为最后一部分:实现篇。原文作者天雨粟,原载于作者知乎专栏,AI 科技评论已获授权。
前言
上一篇的专栏介绍了Word2Vec中的Skip-Gram模型的结构和训练,如果看过的小伙伴可以直接开始动手用TensorFlow实现自己的Word2Vec模型,本篇文章将利用TensorFlow来完成Skip-Gram模型。还不是很了解Skip-Gram思想的小伙伴可以先看一下上一篇的专栏内容。
本篇实战代码的目的主要是加深对Skip-Gram模型中一些思想和trick的理解。由于受限于语料规模、语料质量、算法细节以及训练成本的原因,训练出的结果显然是无法跟gensim封装的Word2Vec相比的,本代码适合新手去理解与练习Skip-Gram模型的思想。
工具介绍
● 语言:Python 3
● 包:TensorFlow(1.0版本)及其它数据处理包(见代码中)
● 编辑器:jupyter notebook
● 线上GPU:floyd (https://www.floydhub.com/)
● 数据集:经过预处理后的维基百科文章(英文)
正文部分
文章主要包括以下四个部分进行代码构造:
- 数据预处理
- 训练样本构建
- 模型构建
- 模型验证
1 数据预处理
关于导入包和加载数据在这里就不写了,比较简单,请参考git上的代码。
数据预处理部分主要包括:
替换文本中特殊符号并去除低频词
对文本分词
构建语料
单词映射表
首先我们定义一个函数来完成前两步,即对文本的清洗和分词操作。

上面的函数实现了替换标点及删除低频词操作,返回分词后的文本。
下面让我们来看看经过清洗后的数据:

有了分词后的文本,就可以构建我们的映射表,代码就不再赘述,大家应该都比较熟悉。

我们还可以看一下文本和词典的规模大小:

整个文本中单词大约为1660万的规模,词典大小为6万左右,这个规模对于训练好的词向量其实是不够的,但可以训练出一个稍微还可以的模型。
2 训练样本构建
我们知道skip-gram中,训练样本的形式是(input word, output word),其中output word是input word的上下文。为了减少模型噪音并加速训练速度,我们在构造batch之前要对样本进行采样,剔除停用词等噪音因素。
采样
在建模过程中,训练文本中会出现很多“the”、“a”之类的常用词(也叫停用词),这些词对于我们的训练会带来很多噪音。在上一篇Word2Vec中提过对样本进行抽样,剔除高频的停用词来减少模型的噪音,并加速训练。
我们采用以下公式来计算每个单词被删除的概率大小:
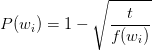
其中 f(wi) 代表单词 wi 的出现频次。t为一个阈值,一般介于1e-3到1e-5之间。

上面的代码计算了样本中每个单词被删除的概率,并基于概率进行了采样,现在我们手里就拿到了采样过的单词列表。
构造batch
我们先来分析一下skip-gram的样本格式。skip-gram不同于CBOW,CBOW是基于上下文预测当前input word。而skip-gram则是基于一个input word来预测上下文,因此一个input word会对应多个上下文。我们来举个栗子“The quick brown fox jumps over lazy dog”,如果我们固定skip_window=2的话,那么fox的上下文就是[quick, brown, jumps, over],如果我们的batch_size=1的话,那么实际上一个batch中有四个训练样本。
上面的分析转换为代码就是两个步骤,第一个是找到每个input word的上下文,第二个就是基于上下文构建batch。
首先是找到input word的上下文单词列表:

我们定义了一个get_targets函数,接收一个单词索引号,基于这个索引号去查找单词表中对应的上下文(默认window_size=5)。请注意这里有一个小trick,我在实际选择input word上下文时,使用的窗口大小是一个介于[1, window_size]区间的随机数。这里的目的是让模型更多地去关注离input word更近词。
我们有了上面的函数后,就能够轻松地通过input word找到它的上下文单词。有了这些单词我们就可以构建我们的batch来进行训练:

注意上面的代码对batch的处理。我们知道对于每个input word来说,有多个output word(上下文)。例如我们的输入是“fox”,上下文是[quick, brown, jumps, over],那么fox这一个batch中就有四个训练样本[fox, quick], [fox, brown], [fox, jumps], [fox, over]。
3 模型构建
数据预处理结束后,就需要来构建我们的模型。在模型中为了加速训练并提高词向量的质量,我们采用负采样方式进行权重更新。
输入层到嵌入层
输入层到隐层的权重矩阵作为嵌入层要给定其维度,一般embeding_size设置为50-300之间。

嵌入层的 lookup 通过 TensorFlow 中的 embedding_lookup 实现,详见:
http://t.cn/RofvbgF
嵌入层到输出层
在skip-gram中,每个input word的多个上下文单词实际上是共享一个权重矩阵,我们将每个(input word, output word)训练样本来作为我们的输入。为了加速训练并且提高词向量的质量,我们采用negative sampling的方法来进行权重更新。
TensorFlow中的sampled_softmax_loss,由于进行了negative sampling,所以实际上我们会低估模型的训练loss。详见:http://t.cn/RofvS4t

请注意代码中的softmax_w的维度是vocab_size x embedding_size,这是因为TensorFlow中的sampled_softmax_loss中参数weights的size是[num_classes, dim]。
4 模型验证
在上面的步骤中,我们已经将模型的框架搭建出来,下面就让我们来训练训练一下模型。为了能够更加直观地观察训练每个阶段的情况。我们来挑选几个词,看看在训练过程中它们的相似词是怎么变化的。
训练模型:

在这里注意一下,尽量不要经常去让代码打印验证集相似的词,因为这里会多了一步计算步骤,就是计算相似度,会非常消耗计算资源,计算过程也很慢。所以代码中我设置1000轮打印一次结果。

从最后的训练结果来看,模型还是学到了一些常见词的语义,比如one等计数词以及gold之类的金属词,animals中的相似词也相对准确。
为了能够更全面地观察我们训练结果,我们采用sklearn中的TSNE来对高维词向量进行可视化。详见:http://t.cn/Rofvr7D
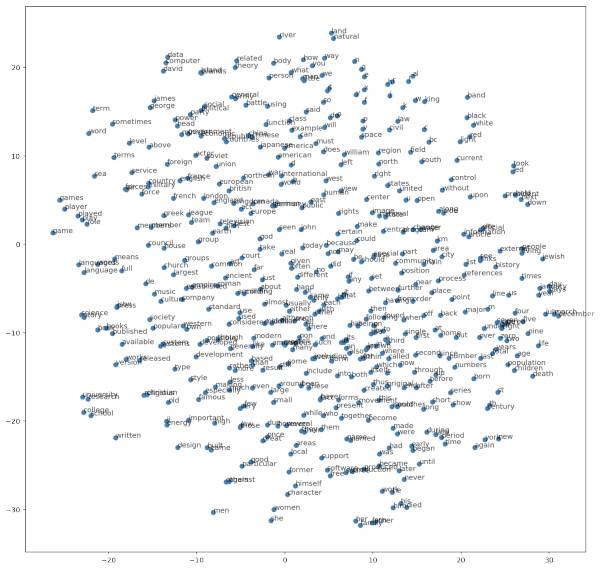
上面的图中通过TSNE将高维的词向量按照距离远近显示在二维坐标系中,该图已经在git库中,想看原图的小伙伴去git看~
我们来看一下细节:

上面是显示了整张大图的局部区域,可以看到效果还不错。
关于提升效果的技巧:
增大训练样本,语料库越大,模型学习的可学习的信息会越多。
增加window size,可以获得更多的上下文信息。
增加embedding size可以减少信息的维度损失,但也不宜过大,我一般常用的规模为50-300。
附录:
git代码中还提供了中文的词向量计算代码。同时提供了中文的一个训练语料,语料是我从某招聘网站上爬取的招聘数据,做了分词和去除停用词的操作(可从git获取),但语料规模太小,训练效果并不好。

上面是我用模型训练的中文数据,可以看到有一部分语义被挖掘出来,比如word和excel、office很接近,ppt和project、文字处理等,以及逻辑思维与语言表达等,但整体上效果还是很差。一方面是由于语料的规模太小(只有70兆的语料),另一方面是模型也没有去调参。如果有兴趣的同学可以自己试下会不会有更好的效果。
完整代码请见:
http://t.cn/RofPq2p
相关阅读:
一文详解 Word2vec 之 Skip-Gram 模型(结构篇)
一文详解 Word2vec 之 Skip-Gram 模型(训练篇)
25 行 Python 代码实现人脸检测——OpenCV 技术教程
6月25日门票直减 700 优惠券
手慢过期
https://gair.leiphone.com/gair/coupon/s/594fb39fb1081
优惠券仅限「参会门票」。赠送的优惠劵额度每天递减 50 元,有效期为 1 天,可供多人使用。长按复制链接在浏览器打开,或点击文末阅读原文立即使用。
点击文末阅读原文立即使用

AI科技评论招人啦!
作为国内顶尖人工智能学术媒体,AI科技评论一直秉承“洞悉学术前沿,连结产业未来”的理念,为读者奉上来自国内外的深度报道。
AI科技评论期待你的加入,和我们一起见证未来!现诚招学术主编(外聘)、学术编辑、外翻编辑等岗位,详情请 点这里
欢迎投递简历到:guoyixin@leiphone.com,AI 科技评论等你哦!





