初学者系列:基于神经网络的协同过滤(NCF)详解
导读
协同过滤推荐技术是目前推荐领域中应用最广泛的技术,也是当今推荐算法中的研究热点。本文主要介绍《Neural network-based Collaborative Filtering》(基于神经网络的协同过滤)——用神经网络学习用户-项目之间交互函数的协同过滤通用框架。
MF的局限性
00
在众多协同过滤技术中,矩阵分解(MF)是最受欢迎的。矩阵分解(MF)将用户和项目映射到共享潜在空间(shared latent space),使用潜在特征向量(latent features),用以表示用户或项目。尽管MF对于协同过滤有效,但是简单地使用内积结合用户和项目潜在特征可能不足以获取用户交互数据的复杂结构。
原理
01
NCF是在隐式反馈(implicit feedback)数据上提出的基于神经网络的协同过滤的通用框架,用来模拟用户和项目的潜在特征。与MF使用内积估计user-item交互不同的是,NCF是从数据中学习交互函数。
显式反馈:用户直接反映出来的对于产品的喜好(评分)
隐式反馈:用户间接反映出来的对于产品的喜好(购买、浏览、搜索记录)
用户的隐式反馈得到的用户-项目交互矩阵 Y定义为:

Note:值 为0 不代表u不喜欢 i,也有可能是用户根本不知道有这个项目
在隐式反馈上的推荐问题可以表达为估算矩阵 Y 中未观察到的item的分数问题(这个分数被用来评估项目的排名)。NCF框架利用神经网络,参数化相互作用函数 f,从而估计 y^ui。
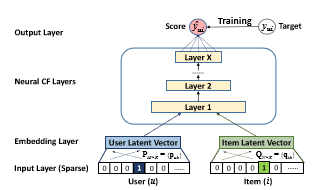
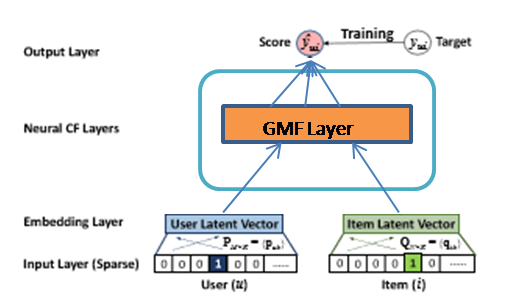
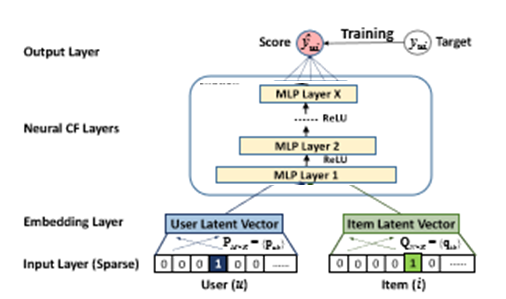
上图为NCF通用框架结构图,主要包括输入层、Embedding层、NCF层以及输出层四部分。下面我们着重介绍一下Embedding层与NCF层。
Embedding Layer
NCF的输入是经过one-hot编码之后的二值化稀疏向量。由于存在数据稀疏的情况,需要经过Embedding将输入层的稀疏表示映射为一个稠密向量(dense vector)。

在这里,Embedding可以理解为输入与潜在因素矩阵的点乘,经过Embedding之后的输出可以表示为:
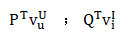
其中:
P、Q 分别表示用户与项目的潜在因素矩阵
v^U_u、v^I_i分别表示输入层输出的用来描述用户u、项目i的特征向量
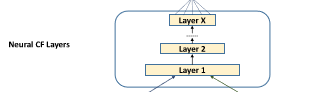
Neural CF Layer
NCF层为多层神经网络,用以发现用户-项目交互的某些潜在结构。
NCF预测模型可以表示为:
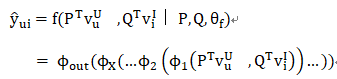
其中:
Θ_f 为交互函数f的模型参数;
ϕ_out表示为输出层映射函数;
ϕ_x表示第 x个神经协作过滤(CF)层映射函数
NCF通用框架可以以不同方式模拟user-item交互,下面主要介绍以下论文中提到的三个实例GMF、MLP以及NeuMF。
GMF
MF(Matrix Factorization)用一个潜在特征向量实值将每个用户和项目关联起来,以用户潜在向量p_u与项目潜在向量q_i的内积作为相互作用的评估。
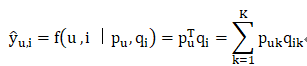
其中:
K 表示潜在空间(latent space)的维度
GMF(Generalized Matrix Factorization)为广义矩阵分解,是矩阵分解(MF)的推广。
定义第一层NCF层的映射函数为:
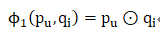
其中:
p_u、q_i分别为用户、项目的潜在向量。
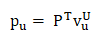
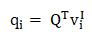
⊙ 表示向量的逐元素乘积
GMF的输出表示为:
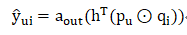
其中:
a_out为输出层的激活函数,选择sigmod函数;
h为输出层的权重,通过训练得到.
MLP
基于NCF框架下的MLP模型,不是像GMF(广义矩阵分解)那样简单的使用逐元素相乘的内积来描述用户和项目之间的潜在交互特征,而是使用标准的多层感知机(MLP)学习用户与项目间的潜在特征。
NCF框架下的MLP每一层输出z_i为:
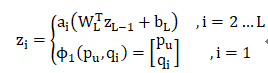
最后模型的输出为:
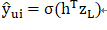
其中:
W_x表示第x层的感知机权重矩阵;
b_x表示第x层的感知机的偏置向量;
a_x为第x层的感知机的激活函数,这里选择为ReLU。
NeuMF
基于NCF框架下的神经矩阵分解模型(Neural collaborative filtering framework,NeuMF)是对GMF与MLP的融合,以便于更好地对复杂用户-项目交互建模。
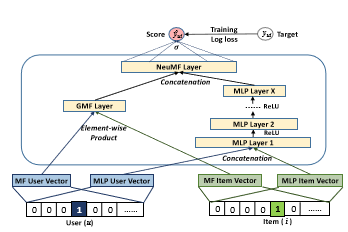
由于两个模型的最佳Embedding尺寸差异很大,因此,允许GMF和MLP学习独立的Embedding,在最后的隐层输出链接两种模型的结果。
GMF部分的输出表示为:
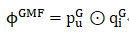
MLP部分的输出表示为:
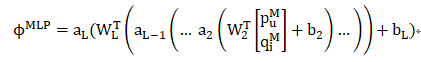
NeuMF模型输出为:
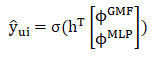
p^G_u、p^M_u分别表示 GMF 部分和 MLP 部分用户在Embedding层的输出;
q^G_i、q^M_i分别表示 GMF 部分和 MLP 部分项目Embedding层的输出
优化
对于隐式数据来说,目标值 y_ui是二进制值1或0,因此可以将隐性反馈的推荐问题当做一个二分类问题来解决,将 y_ui的值作为一个标签(1表示项目 i 和用户 u相关,否则为0)。则预测分数 yˆ_ui代表项目 i 和用户 u相关的可能性大小,因此需要将网络的输出限制在[0.1]之间。
NCF框架的目标函数为交叉熵损失函数:
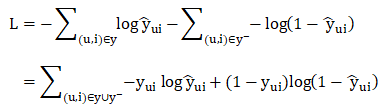
其中:
y 表示交互矩阵 Y中观察到的条目
y−表示负实例(negative instances,可以将未观察的样本全体视为消极实例,或者采取抽样的方式标记为消极实例)
在训练优化时,对于GMF 和 MLP 采用Adam进行优化,可以适应每个参数的学习率;对于NeuMF,需要先随机初始化的 GMF 和 MLP 直到模型收敛。然后,用它们的模型参数初始化 NeuMF 相应部分的参数。在预先训练的参数输入NeuMF之后,用SGD进行优化。
代码详解
02
源码链接:
https://github.com/hexiangnan/neural_collaborative_filtering
作者给出的源码主要包括GMF、MLP以及NeuMF的实现,主要框架如下:
环境:
Python2
keras 1.0.7
Theano 0.8.0
数据
官方给出了经过处理的 MovieLens 1 Million (ml-1m) 和 Pinterest (pinterest-20)两个数据集,源码中使用了MovieLens 1 Million (ml-1m) 数据。
MovieLens 1 Million (ml-1m)数据集包含包含6000个用户在近4000部电影上的100万条评分,源码中给出的经过处理的数据集主要包含训练数据、测试数据以及负实例。
train.rating:每一列分别为userID、 itemID、 rating(1-5的整数)、timestamp (时间 戳)
test.rating:每一列分别为userID、 itemID、 rating(1-5的整数)、timestamp (时间 戳)
test.negative:每一列分别为 (userID,itemID)、negativeItemID1、negativeItemID2...
构造数据集(Dataset.py)
在此部分主要构造了三个数据集,分别为trainMatrix、testRatings、testNegatives。
trainMatrix 包含(用户id,项目id),以及用户与项目的交互情况(若用户对该项目有评分,值为1)。
testRatings 为包含测试集的用户id,项目id的矩阵。
testNegatives 为testRatings中id对应的 negativeItemID(未观察到的项目id)
模型训练
源码中提供了实现了论文中提到的基于NCF框架的三种实例的代码,GMF、MLP只有在构建的模型部分不同,NeuMF除了构建模型不同以外还增加了预训练的部分,用训练好GMF、MLP的参数初始化 NeuMF 相应部分的参数。下面主要介绍这三个模型的构建。
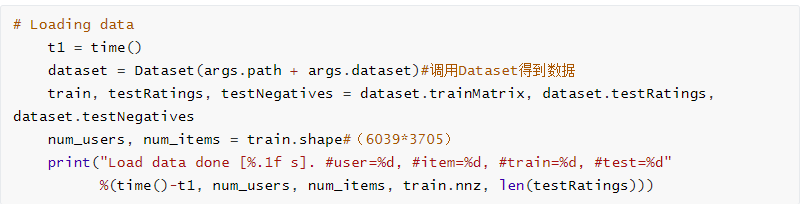
加载数据
构建模型
不同的模型通过get_model()函数实现,损失函数选择交叉熵损失,优化器选择adam。

对于不同模型的get_model()如下所示:
GMF(GMF.py)
在GMF中使用了keras中的Embedding层进行Embedding操作,MF部分直接将经过Flatten层处理后的用户潜在向量(p_u)与项目潜在向量(q_i)经过merge函数用乘积的方式连接。

MLP(MLP.py)
与MF不同的是,MLP层的输入是用户潜在向量(p_i)与项目潜在向量(q_i)经 contract拼接的方式连接起来的向量。MLP层是通过for循环构建的。

NeuMF(NeuMF.py)
在 NeuMF模型中,前面部分是GMF与MLP的模型,在最后的输出层将两个模型的输出通过merge()拼接起来。
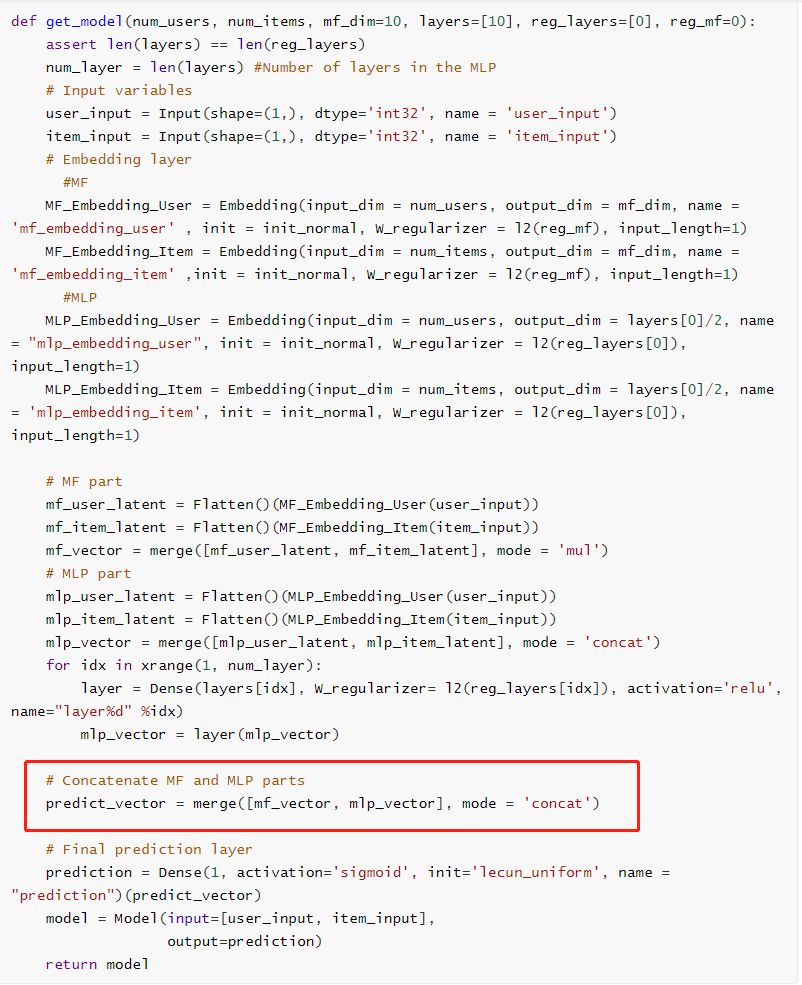
开始训练
在训练时会在训练数据中加入负例(negative instances),通过get_train_instances()函数获得。
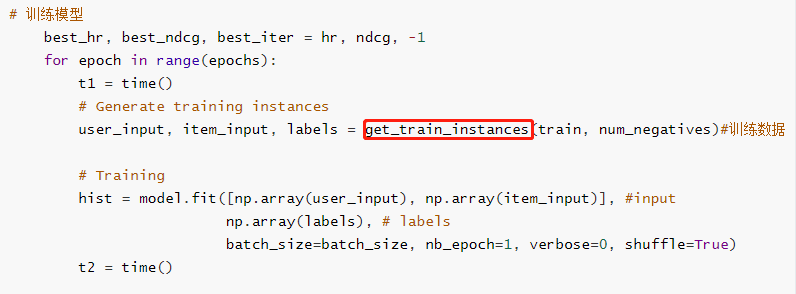
负例直接随机选取用户没有选择的其余的物品,使用num_negatives控制负例的比例(默认值是4)。

测试
在测试中主要通过evaluate_model()函数获得测试集(test.rating)中用户对应的产品是否在top K中(在的话hits的某一位置为1,否则为0)。
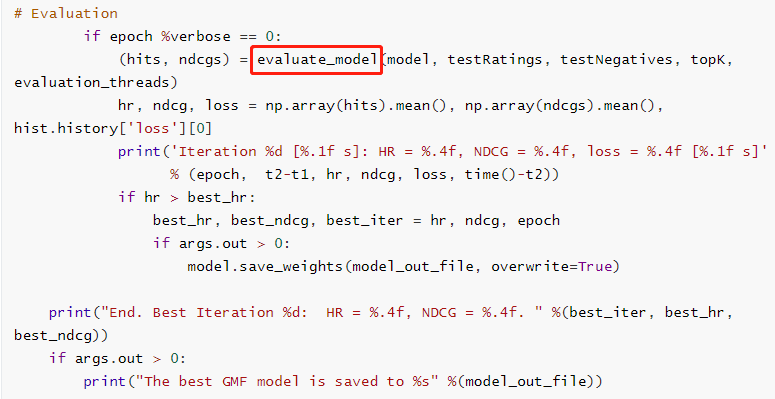
在evaluate_model()函数中主要通过以下三个函数实现,在eval_one_rating中计算得到了测试数据(negativeitem id +testitem id)中Top K的 item id(存放在ranklist中)。通过调用getHitRatio函数得到testitem id是否存在于Top K中(存在的话,hr = 1,否则为0)。


论文链接:
http://staff.ustc.edu.cn/~hexn/papers/www17-ncf.pdf
-END-
专 · 知

欢迎微信扫一扫加入专知人工智能知识星球群,获取最新AI专业干货知识教程视频资料和与专家交流咨询!

请加专知小助手微信(扫一扫如下二维码添加),加入专知人工智能主题群,咨询技术商务合作~

专知《深度学习:算法到实战》课程全部完成!560+位同学在学习,现在报名,限时优惠!网易云课堂人工智能畅销榜首位!

点击“阅读原文”,了解报名专知《深度学习:算法到实战》课程



