NLP有望迎来书同文,车同轨?新研究发布基于BERT的文本自动生成评价指标|一周最火AI学术

大数据文摘专栏作品
作者:Christopher Dossman
编译:VICKY、Joey、云舟
呜啦啦啦啦啦啦啦大家好,拖更的AIScholar Weekly栏目又和大家见面啦!
AI ScholarWeekly是AI领域的学术专栏,致力于为你带来最新潮、最全面、最深度的AI学术概览,一网打尽每周AI学术的前沿资讯。
每周更新,做AI科研,每周从这一篇开始就够啦!
本周关键词:端到端的语音转译、强化学习的量化应用、文本生成的自动化标准
本周热门学术研究
语音到语音翻译,还不需要转录?
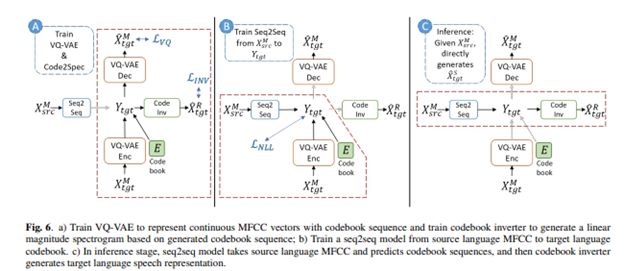
在这项工作中,研究人员探索了一种无需任何转录即可训练语音对语音翻译任务的技术。他们的方法包括两个阶段。在第一阶段,研究人员使用离散量化自动编码器训练并生成了具有无监督术词语发现的离散表示。其次,他们训练了一个序列到序列的模型,将源语言直接映射到目标语言的离散表示。现在,它已经可以对法语——英语和日语——英语进行语音到语音的直译。
史无前例?研究人员称,这是第一项旨在提供未知语言之间的纯语音对语音翻译的工作。该方法能够直接生成目标语音,而无需任何带有源或者目标转录的预训练步骤。
像许多技术进步一样,高效的语言翻译一直以来都是人们梦寐以求的,而现代语音技术正在朝着这个方向前进。考虑到前人的翻译成果以及研究人员在本文中介绍的内容,语音翻译正变得越来越精细。
同时,随着世界一体化进程加快,语音对语音的翻译有其巨大的价值,跨文化交流和全球商务的需求与日俱增。这个方法最好的地方在于,它适用于任何类型的语言,即便是没有书面形式的语言也可以被翻译,因为目标语音的表示都是在无监督的情况下训练和生成的。
原文:
强化学习的量化
研究人员使用量化强化学习(QUARL)对深度强化学习的量化效应进行了第一次研究。QUARL是一种新框架,用来对量化在各种强化学习任务和算法中的影响进行基准测试和分析。
他们将训练后量化和量化感知训练技术应用于一系列强化学习任务和训练算法当中。他们的工作是一项综合性的实验研究,该研究研究了量化对于各种深度强化学习策略的影响,从而有望减少其计算资源的需求。
他们的工作表明,策略可以在不丢失准确度的情况下被量化到6-8位的精度。并且,某些任务和RL算法由于其扩大了模型权重分布而产生了更难以量化的策略,量化感知训练能始终如一地改善训练后的量化结果,甚至在整个精度基线上都能持续产生效益。
这项工作表明,强化学习量化的实际应用与未量化的策略相比,不仅实现了加速,还减少了内存使用。
原文:
机器人的动作分类与编码
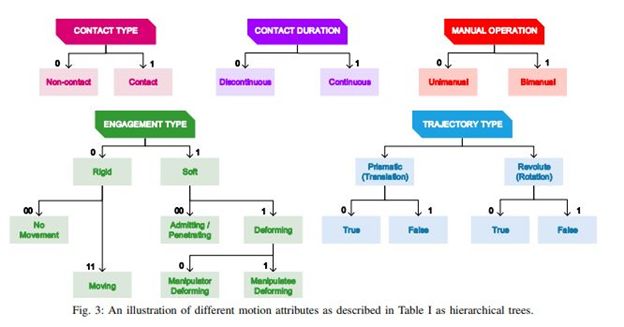
为了从机器人学的角度来表示运动,本文的研究人员引入了一种操作分类法,该分类法考虑了人类操纵的机器人,研究了它们在烹饪活动中的接触类型和轨迹类型这两种属性。特别地,他们专注于在基本烹饪活动中观察到的操纵动作。
本文使用的视频数据主要来源是两组教学视频及其标签。第一组视频来自于公开可用的功能性面向对象网络。
21世纪,工业机器人取得了长足的发展。这些发展已经并且正在不断改变机器人动力学,从而使其在现实世界中有着举足轻重的地位。为了推进机器人研究,本文研究了烹饪中操纵任务的机器人属性,并使用它们来创建了一种操纵运动的有效表示。
研究人员能够基于轨迹和接触属性分配二进制编码的字符串(操作码)来描述特定运动的属性。所得的操作码和分类法可用来确定彼此相似的运动类型,它们还可以允许研究人员从机器人的角度来表示和分组操作。
原文:
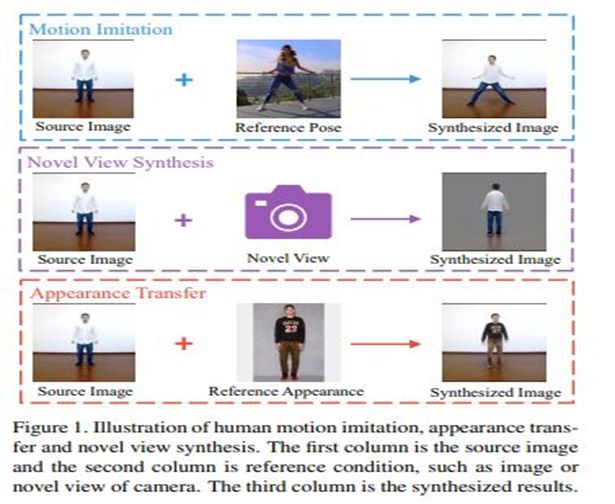
一个统一的人体运动模拟、外观转换和新视角合成框架
在近期的一篇论文中,研究人员提出了一个统一的框架来处理对人体运动的模仿、外观变形和新图像合成。他们提出了一种流动翘曲块(LWB)来从三个方面解决源信息的丢失:
-
去噪卷积自动编码器用于提取有用的功能,以保留源信息,包括纹理,颜色,样式和面部识别 -
将每个局部部分的源要素合并到全局要素流中,以此进一步保留详细的源信息; -
这一框架支持多源变形,例如在外观转换中,从一个源变形头部的特征,到另一个源变形人体的特征,并把这两个特征聚合到全局特征流中。
本文提出的框架采用了一个身体恢复模块来估算3D身体网格,这样的方法比用2D姿势估算更为强大。考虑到现有方法主要使用2D姿势、密集姿势和身体分析来估计人体结构,这是一个很大的飞跃。
另外,这个方法支持多个信息源的、更灵活的变形。除了混合功能之外,研究人员还开发了一个新的数据集,用于评估人体运动模仿、外观变形和新图像合成的效果。
即使是在有遮挡的情况下,该模型也仍然十分有效,它能够保留面部特征、形状一致性和衣服细节。这样,研究人员和开发人员就可以将这些任务提高到一个新水平。
代码和数据集:
原文:
基于BERT的文本自动生成评价指标
在论文中,研究人员引入了BERTSCORE:一种基于预训练的BERT上下文嵌入的语言生成评估指标。BERTScore是通过计算候选语句中每个标记与该句中每个标记的相似性而获得的一个得分。它在设计之初就力求简单、多场景适用性和易用性。
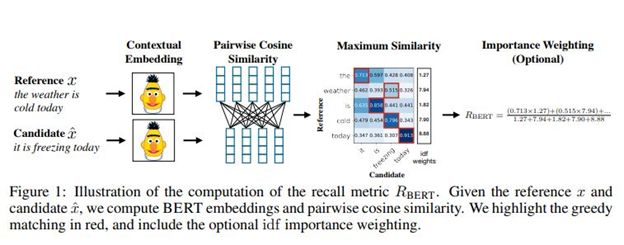
它们使用了363个机器翻译和图像字幕系统的输出来进行这一分数的计算。相比其他模型,BERTSCORE与人为判断的关联性更强,并且相比现有的其他指标,它能提供更强的模型选择性。
实际操作结果表明,研究人员提出的BERTSCORE具有比常用度量方法更好的相关性,因此这一度量方式对于模型筛选是很有帮助的。但是需要注意的是,BERTSCORE并不在所有情况下都胜过现有的其他度量方法。
研究人员希望能够设计新的、用于特定任务的度量指标,这些指标将把BERTSCORE作为“子指标”使用,并在将来满足特定任务的需求。并且,由于BERTSCORE是完全可微的,因此它也可以合并到未来的训练过程中以计算“学习误差”,从而减少优化和评估目标之间的不匹配。
原文:
其他爆款论文
一个可以有效推动多语言语音翻译的研究框架:
一个能将音频序列分解为各种元素的框架(例如语音内容、情绪音调、背景噪音等),它还能使用解缠的音频表示对人脸进行动画处理:
阅读、参与和评论:自动生成新闻评论的深层架构:
利用BERT进行基于语言特征的全文情感分析:
机器人操作系统的容错系统:
数据集
Facebook AI的研究人员们日前创建了基于GitHub和Stack Overflow搜索内容的代码数据集《神经代码搜索评估数据集》:
https://arxiv.org/pdf/1908.09804.pdf
可通过RGB-D视频推动动态变化的真实世界数据集:
一个能提高抗噪和远程语音处理领域的数据集:
eICU重症监护数据集上对机器学习模型进行基准测试:
AI新闻
有关Conjure你需要了解的一切:
富士通的AI和3D传感器技术将用于协助裁判在世界锦标赛中对体操比赛的打分:
如果你想成立一家AI技术主导的公司,你该雇佣谁:
https://www.forbes.com/sites/googlecloud/2019/10/02/want-to-become-an-ai-first-company-hire-these-people/#7a0a72545c72
埃森哲表示,IT落后者可能在未来五年内损失高达200亿美元的收入:
https://www.zdnet.com/article/it-laggards-could-lose-up-to-20-billion-in-revenue-over-the-next-5-years-says-accenture/
微软爸爸:我们愿意为大家提供免费学习Python的机会:

Christopher Dossman是Wonder Technologies的首席数据科学家,在北京生活5年。他是深度学习系统部署方面的专家,在开发新的AI产品方面拥有丰富的经验。除了卓越的工程经验,他还教授了1000名学生了解深度学习基础。
LinkedIn:
https://www.linkedin.com/in/christopherdossman/
志愿者介绍
后台回复“志愿者”加入我们