谷歌最强NLP模型BERT官方中文版来了!多语言模型支持100种语言

新智元报道
新智元报道
来源:GitHub
作者:Google Research 编辑:肖琴
【新智元导读】今天,在开源最强NLP模型BERT的TensorFlow代码和预训练模型的基础上,谷歌AI团队再次发布一个多语言模型和一个中文模型。
上周,谷歌AI团队开源了备受关注的“最强NLP模型”BERT的TensorFlow代码和预训练模型,不到一天时间,收获3000多星!
今天,谷歌再次发布BERT的多语言模型和中文模型!
BERT,全称是Bidirectional Encoder Representations from Transformers,是一种预训练语言表示的新方法。
BERT有多强大呢?它在机器阅读理解顶级水平测试SQuAD1.1中表现出惊人的成绩:全部两个衡量指标上全面超越人类!并且还在11种不同NLP测试中创出最佳成绩,包括将GLUE基准推至80.4%(绝对改进7.6%),MultiNLI准确度达到86.7% (绝对改进率5.6%)等。
新智元近期对BERT模型作了详细的报道和专家解读:
NLP历史突破!谷歌BERT模型狂破11项纪录,全面超越人类!
如果你已经知道BERT是什么,只想马上开始使用,可以下载预训练过的模型,几分钟就可以很好地完成调优。
戳这里直接使用:
https://github.com/google-research/bert/blob/master/multilingual.md
目前有两种多语言模型可供选择。我们不打算发布更多单语言模型,但可能会在未来发布这两种模型的BERT-Large版本:
BERT-Base, Multilingual: 102 languages, 12-layer, 768-hidden, 12-heads, 110M parameters
BERT-Base, Chinese: Chinese Simplified and Traditional, 12-layer, 768-hidden, 12-heads, 110M parameters
多语言模型支持的语言是维基百科上语料最大的前100种语言(泰语除外)。多语言模型也包含中文(和英文),但如果你的微调数据仅限中文,那么中文模型可能会产生更好的结果。
为了评估这些系统,我们使用了XNLI dataset,它是MultiNLI的一个版本,其中dev集和test集已经(由人类)翻译成15种语言。需要注意的是,训练集是机器翻译的(我们使用的是XNLI提供的翻译,而不是Google NMT)。
以下6种主要语言的评估结果:
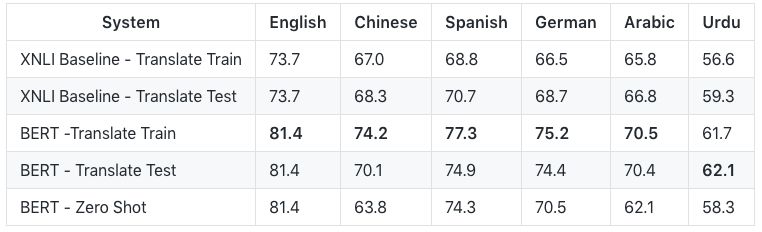
前两行是XNLI baseline的结果,后三行是使用BERT的结果。
Translate Train 表示MultiNLI的训练集是从英语用机器翻译成外语的。所以训练和评估都是用外语完成的。遗憾的是,由于是用机器翻译的数据进行训练,因此无法量化较低的精度在多大程度上归因于机器翻译的质量,多大程度上归因于预训练模型的质量。
Translate Test 表示XNLI测试集是从外语用机器翻译成英语的。因此,训练和评估都是用英语进行的。但是,由于测试评估是在机器翻译的英语上进行的,因此准确性取决于机器翻译系统的质量。
Zero Shot 表示多语言BERT模型在英语MultiNLI上进行了微调,然后在外语XNLI测试集上进行了评估。在这种情况下,预训练和微调的过程都不涉及机器翻译。
请注意,英语的结果比MultiNLI baseline的84.2要差,因为这个训练使用的是Multilingual BERT模型,而不是English-only的BERT模型。这意味着对于语料资源大的语言,多语言模型的表现不如单语言模型。但是,训练和维护数十种单语言模型是不可行的。因此,如果你的目标是使用英语和中文以外的语言最大限度地提高性能,那么从我们的多语言模型开始,对你感兴趣的语言数据进行额外的预训练是有益的。
对于中文来说,用Multilingual BERT-Base和Chinese-only BERT-Base训练的中文模型的结果比较如下:
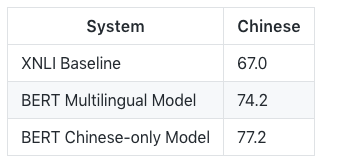
跟英语类似,单语言模型比多语言模型好3%。
多语言模型不需要任何特殊考虑或更改API。我们在tokenization.py中更新了BasicTokenizer的实现以支持汉字的tokenization,但没有更改 tokenization API。
为了测试新模型,我们修改了run_classifier.py以添加对XNLI数据集的支持。这是MultiNLI的15种语言版本,其中dev/test 集已经经过人工翻译的,训练集已经经过机器翻译。
要运行 fine-tuning 代码,请下载XNLI dev/test set和XNLI机器翻译的训练集,然后将两个.zip文件解压缩到目录$XNLI_DIR中。
在XNLI上运行 fine-tuning。该语言被硬编码为run_classifier.py(默认为中文),因此如果要运行其他语言,请修改XnliProcessor。
这是一个大型数据集,因此在GPU上训练需要花费几个小时(在Cloud TPU上大约需要30分钟)。要快速运行实验以进行调试,只需将num_train_epochs设置为较小的值(如0.1)即可。
export BERT_BASE_DIR=/path/to/bert/chinese_L-12_H-768_A-12 # or multilingual_L-12_H-768_A-12export XNLI_DIR=/path/to/xnli
python run_classifier.py \
--task_name=XNLI \
--do_train=true \
--do_eval=true \
--data_dir=$XNLI_DIR \
--vocab_file=$BERT_BASE_DIR/vocab.txt \
--bert_config_file=$BERT_BASE_DIR/bert_config.json \
--init_checkpoint=$BERT_BASE_DIR/bert_model.ckpt \
--max_seq_length=128 \
--train_batch_size=32 \
--learning_rate=5e-5 \
--num_train_epochs=2.0 \
--output_dir=/tmp/xnli_output/
使用 Chinese-only 模型,结果应该是这样的:
***** Eval results *****
eval_accuracy = 0.774116
eval_loss = 0.83554
global_step = 24543
loss = 0.74603数据源和采样
我们选择的语言是维基百科上语料最大的前100种语言。将每种语言的整个Wikipedia转储数据(不包括用户页和讨论页)作为每种语言的训练数据。
然而,对于特定语言,维基百科的语料大小差异很大,而在神经网络模型中,低资源语言可能是“代表性不足”的(假设语言一定程度上在有限的模型容量中“竞争”)。
维基百科的语料大小也与该语言的使用者人数有关,而且我们也不想为了一种特定语言在很小的数据集上执行数千个epochs,造成过度拟合模型。
为了平衡这两个因素,我们在训练前数据创建(以及WordPiece词汇创建)期间对数据进行了指数平滑加权。换句话说,假设一种语言的概率是P(L),例如P(English) = 0.21,表示在将所有维基百科总合在一起之后,21%的数据是英语的。我们通过某个因子S对每个概率求幂,然后重新规范化,并从这个分布中进行采样。
在这个示例中,我们使S = 0.7。因此,像英语这样的高资源语言会被抽样不足,而像冰岛语这样的低资源语言会被过度采样。比如说,在原始分布中,英语比冰岛语采样率高1000倍,但在平滑后,英语的采样率只高100倍。
Tokenization
对于Tokenization,我们使用110k共享的WordPiece词汇表。单词计数的加权方式与数据相同,因此低资源语言的加权会增大。 我们故意不使用任何标记来表示输入语言(以便zero-shot训练可以工作)。
因为中文没有空白字符,所以在使用WordPiece之前,我们在CJK Unicode范围内的每个字符周围添加了空格。这意味着中文被有效地符号化了。请注意,CJK Unicode block仅包含汉字字符,不包括朝鲜文/韩文或日语片假名/平假名,这些与其他语言一样使用空格+ WordPiece进行标记化。
对于所有其他语言,我们应用与英语相同的方法:(a)字母小写+重音删除,(b)标点符号分割,(c)空白标记化。 我们知道口音标记在某些语言中具有重要意义,但认为减少有效词汇的好处可以弥补这一点。一般来说,BERT强大的上下文模型应该能弥补删除重音标记而引入的歧义。
支持的语言
多语言模型支持维基百科上语料量最大的前100种语言。
但我们不得不排除的唯一一种语言是泰语,因为它是唯一一种不使用空格来划分单词的语言(除了汉语),而且每个单词的字符太多,不能使用基于字符的tokenization。
GitHub地址:
https://github.com/google-research/bert/blob/master/multilingual.md
【加入社群】
新智元 AI 技术 + 产业社群招募中,欢迎对 AI 技术 + 产业落地感兴趣的同学,加小助手微信号:aiera2015_3 入群;通过审核后我们将邀请进群,加入社群后务必修改群备注(姓名 - 公司 - 职位;专业群审核较严,敬请谅解)。





