码农们的福音:一个专门开发高性能大数据代码的系统「开源了」(附论文)
赖斯大学的科研团队将在本周的SIGMOD数据管理国际大会上推介PlinyCompute。
每个精疲力竭的程序员都竭力在Spark之类的‘大数据’平台上实现复杂的对象和工作流程,心里想‘有没有一种更好的方法?’美国国防高级研究计划局(DARPA)资助的赖斯大学Pliny项目的计算机科学家们认为,他们现已有了解决之道,有望为程序员们带来福音。

PlinyCompute的logo
赖斯大学的PlinyCompute将于周四在2018年ACM SIGMOD大会上公布。该团队在同行评审的大会论文(https://dl.acm.org/citation.cfm?id=3196933)中介绍PlinyCompute是“一种专门用于开发高性能大数据代码的系统”。














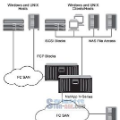
赖斯大学领导开发该平台的计算机科学教授克里斯•杰梅恩(Chris Jermaine)表示,与Spark一样,PlinyCompute力求易于使用、用途广泛。与Spark不一样,PlinyCompute旨在支持以前只有超级计算机或高性能计算机(HPC)才能实现的强大计算。
杰梅恩说:“借助机器学习,尤其是借助深度学习,人们看到了复杂的分析算法应用于大数据时可以做些什么。从《财富》500强企业高管到神经科学研究人员,每个人都在渴求越来越复杂的算法,而如今系统程序员满足这个要求的办法基本上差强人意。虽然HPC能提供这种性能,但要花好几年才能学会为HPC编写代码;也许更糟糕的是,可能要花好几天才能用Spark创建的工具或库可能需要好几个月才能在HPC上编程。”
他说:“Spark是为大数据构建的,它支持HPC无法支持的特性,比如简易的负载均衡、容错和资源分配,这对于数据密集型任务来说绝对必不可少。由于这个,又由于开发时间比HPC短得多,人们在构建可以在Spark上运行的新工具,用于处理机器学习和图形分析等复杂任务。”
邹佳(Jia Zou)是赖斯大学的研究科学家兼描述PlinyCompute的ACM SIGMOD论文的第一作者,她表示,由于Spark在设计当初并未考虑到复杂计算,所以它的计算性能只能提升到目前这个地步。
邹佳在2015年进入赖斯大学之前已在IBM研究中国院研究了六年的大规模分析和数据管理系统,她说:“Spark建立在Java虚拟机即JVM的基础上,JVM负责管理运行时环境,并将关于内存管理的大部分细节抽取出来。Spark依赖JVM,因此其性能受到了影响,尤其是像训练深度神经网络搞深度学习这些任务对计算的需求上升后,更是如此。”

赖斯大学的计算机科学家克里斯•杰梅恩领导PlinyCompute项目
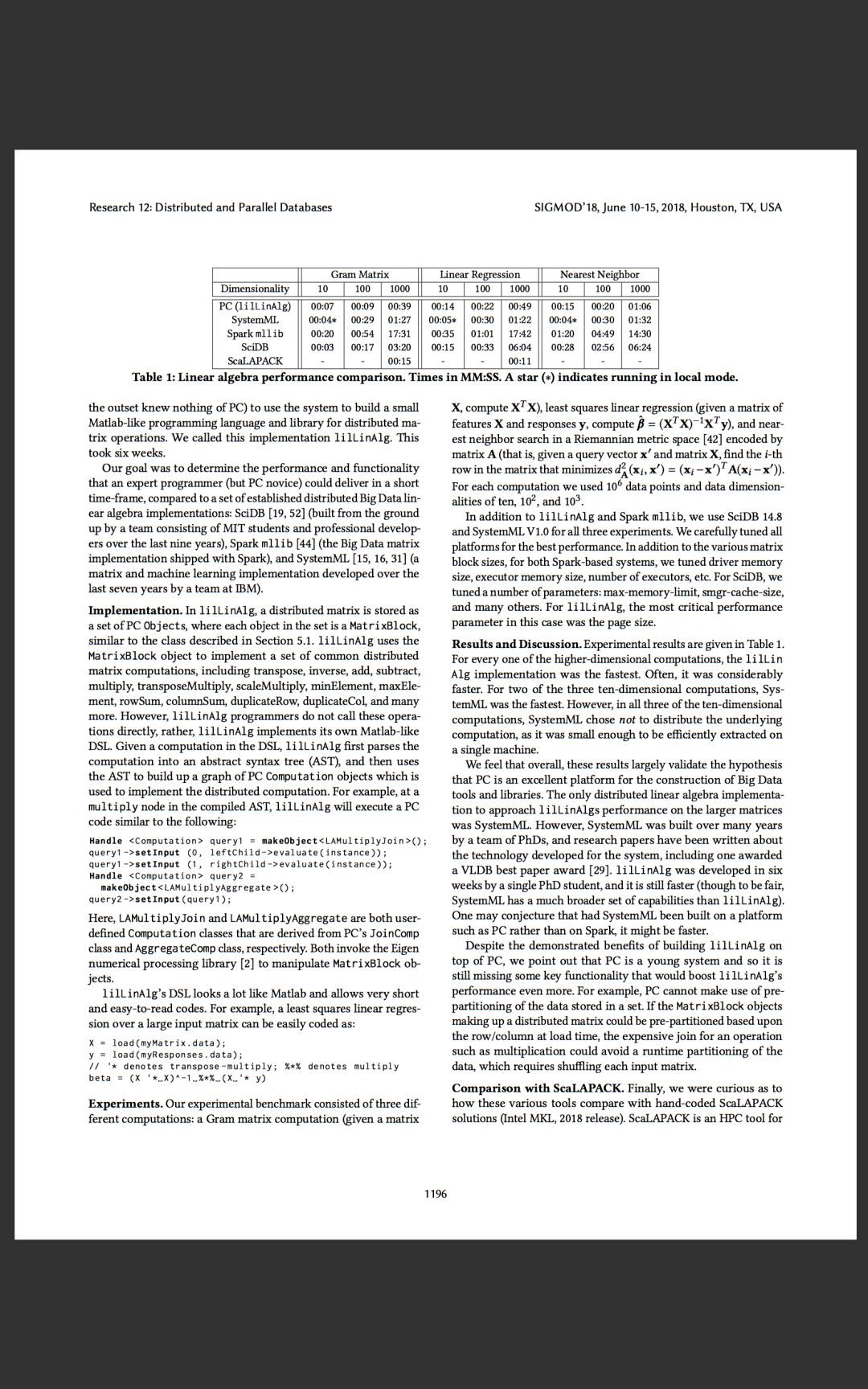
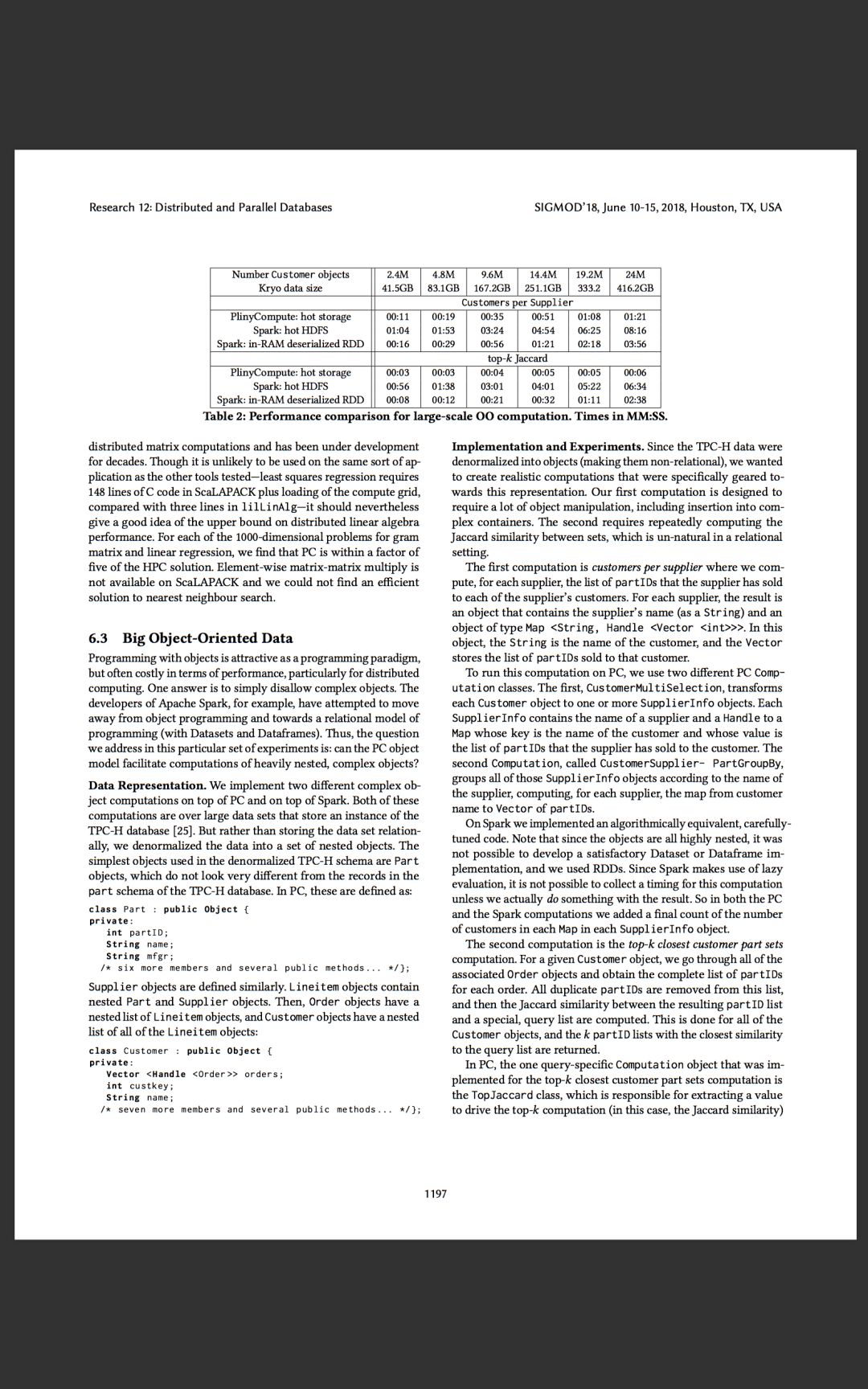
邹说:“PlinyCompute不一样,因为它完全是为高性能而设计的。我们在基准测试中发现,PlinyCompute的速度至少是Spark的两倍;在一些情况下,实现复杂对象处理和库式计算的速度比Spark快50倍。”
她表示,测试已表明,PlinyCompute在构建高性能工具和库方面比同类工具更胜一筹。
杰梅恩表示,不是所有的程序员都会觉得为PlinyCompute编写代码很容易。与Spark所需的基于Java的编码不同,PlinyCompute库和模型必须用C ++编写。
杰梅恩说:“PlinyCompute具有更大的灵活性。对于C ++方面经验和知识相对缺乏的人来说,这可能是一个挑战,但我们还对完成各种实现所需的代码行数进行了一番横向比较。结果发现,在大多数情况下,PlinyCompute和Spark之间没有显著差异。”

赖斯大学的研究科学家邹佳是介绍PlinyCompute的同行评审的新论文的第一作者
Pliny项目于2014年启动,这个DARPA资助的项目拿到了1100万美元款项,致力于开发先进的编程工具,从而能够为程序员们“自动完成代码”和“自动纠正代码”,就像软件在Web浏览器和智能手机上完成搜索查询、纠正拼写那样。Pliny使用机器学习来读取数十亿行的开源计算机程序,并从中学习;杰梅恩表示,PlinyCompute脱胎于这个项目。
他说:“这是一种计算复杂的机器学习应用,实际上没有一个好的工具来构建它。我们一开始就认识到,PlinyCompute这种工具可以用来解决远比我们用Pliny项目来解决的问题广泛得多的问题。”
想了解安装及部署信息、API、FAQ和教程等更多信息,请访问plinycompute.rice.edu。
这项研究还得到了国家科学基金会(NSF)的支持。
PlinyCompute SIGMOD论文的其他作者包括:Matthew Barnett、Tania Lorido-Botran、Shangyu Luo、Carlos Monroy、Sourav Sikdar、Kia Teymourian和Binhang Yuan,他们都来自赖斯大学。

赖斯大学的PlinyCompute团队包括(从左往右):Shangyu Luo、Sourav Sikdar、Jia Zou、 Tania Lorido、Binhang Yuan、Jessica Yu、Chris Jermaine、Carlos Monroy、Dimitrije Jankov和Matt Barnett。