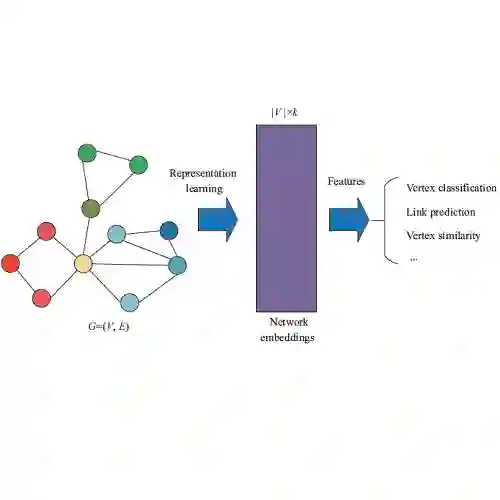
最新综述!基于图神经网络的关系抽取技术进展


GDPNet

论文标题:
GDPNet: Refining Latent Multi-View Graph for Relation Extraction
AAAI 2021
https://www.aaai.org/AAAI21Papers/AAAI-3290.XueF.pdf
https://github.com/XueFuzhao/GDPNet
1.1 论文工作
由于基于 BERT 等序列模型与基于图模型算法是关系抽取任务的研究前沿,这篇文献构造了利用潜在的多视图来捕获 token 之间各种可能的关系,随之对这个图进行精炼以选择重要的词进行关系预测,最后将改进的图表示和基于 BERT 模型的表示连接起来进行关系抽取。

1.2.2 Graph Module
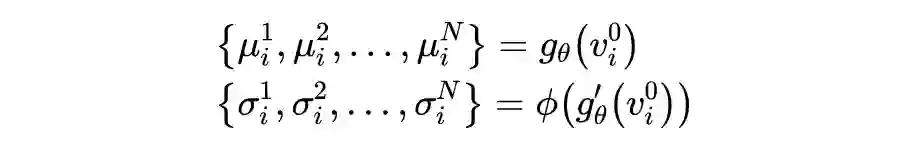

1.2.2.2 Multi-view Graph Convolution
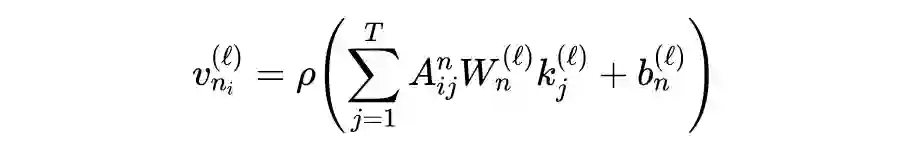
1.2.2.3 Dynamic Time Warping Pooling

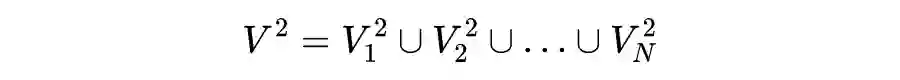
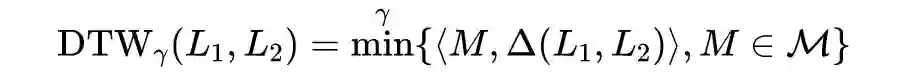

使用 SoftDTM 损失,DTWPool 可以在不丢失大量上下文信息的情况下细化图。
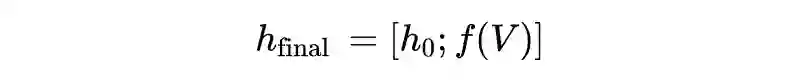
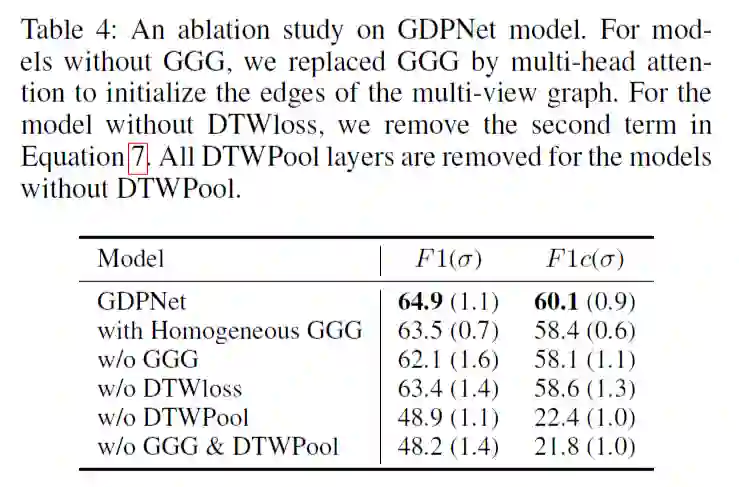
1.3 实验



SOLS

论文标题:
Speaker-Oriented Latent Structures for Dialogue-Based Relation Extraction
EMNLP 2021
https://arxiv.org/abs/2109.05182
2.1 论文工作
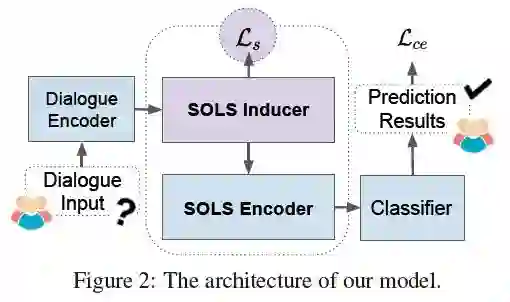
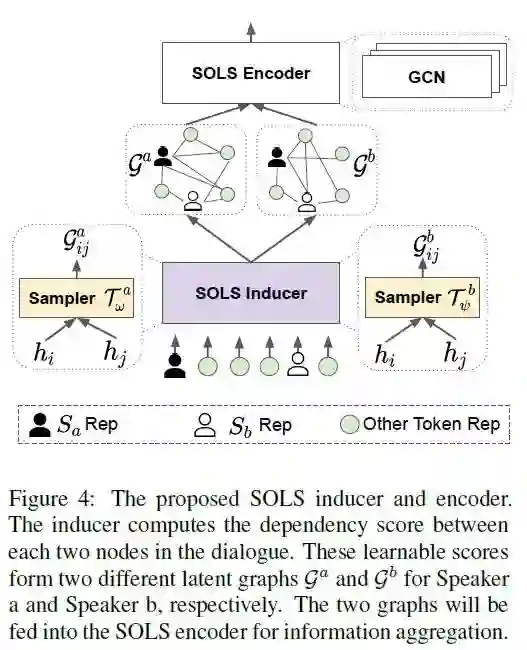
该模型旨在通过探索面向说话者的潜在结构来获得更好的 DiaRE。论文提出的模型有四个模块:
1. 对话编码器(Dialogue Encoder)使用对话作为输入,输出是语境的相关表示。
2. 上下文化的表示将被输入到 SOLS 诱导器(SOLS Inducer)中,以自动生成两个面向说话者的潜在结构和一个新的正则化项,旨在缓解纠缠的逻辑和数据稀疏问题。
3. 然后将潜在结构馈给 SOLS 编码器(SOLS Encoder),该编码器是一个图卷积网络(GCN),主要用于信息聚合。
2.2.2.1 Sampling a Gate

取样器主要有四个模块,主要包括 MLP 模块、分布生成器、Stretcher & Rectifier 和门生成器。
由于 BC 的随机条件,是由之前步骤生成的,因此定义为(0,1)开区间,值 0 和 1 不能被采样到。因此,作者依靠 Hard Concrete(HC)分布将采样从开区间拓展到闭区间。
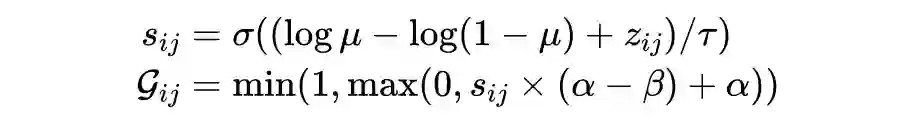
2.2.3 Speaker-Oriented Structures
2.2.3.1 Latent Structure

2.2.3.2 Controlled Sparsity

2.2.4 SOLS Encoder
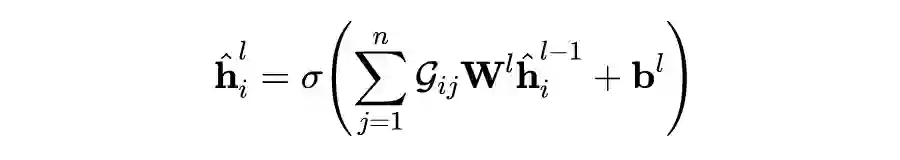
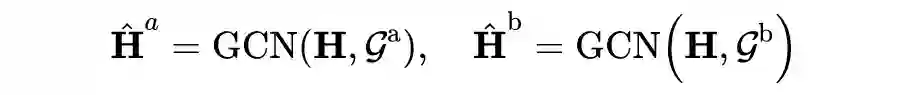

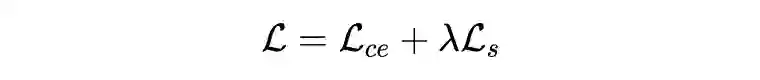
1. dialogue - English version,为第一个来自美国著名喜剧《老友记》的人类注释对话级别 RE 数据集;
2. DialogRE Chinese version,翻译自 DialogRE-EN;
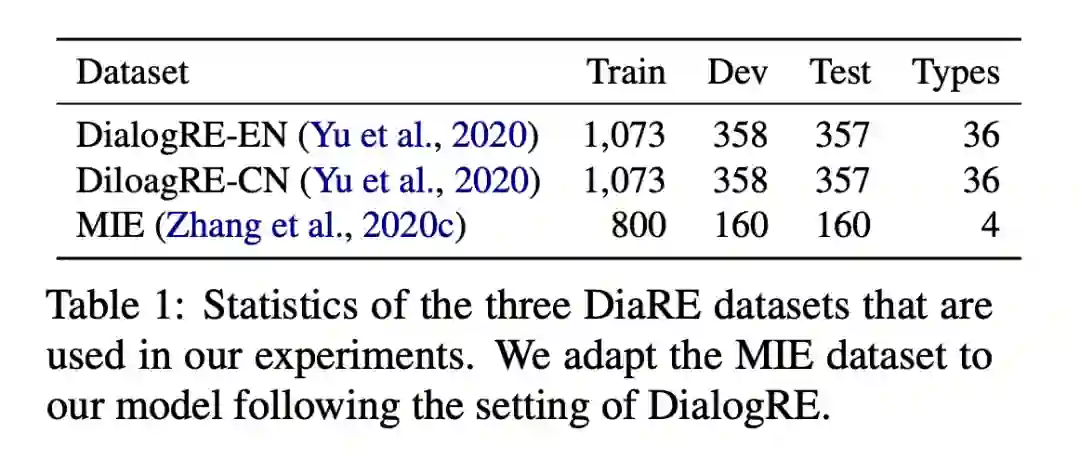
2.3.2 Main Results
论文将提出的 SOLS 方法与如下所述的各种基线进行比较,主要有以下四种方法:
-
Sequence-based Models
-
Rule-based Graph Models
-
Latent Graph Models
-
BERT-based Models


论文标题:
Dialogue Relation Extraction with Document-Level Heterogeneous Graph Attention Networks
https://arxiv.org/pdf/2009.05092.pdf
https://github.com/declare-lab/dialog-HGAT
3.1 论文工作
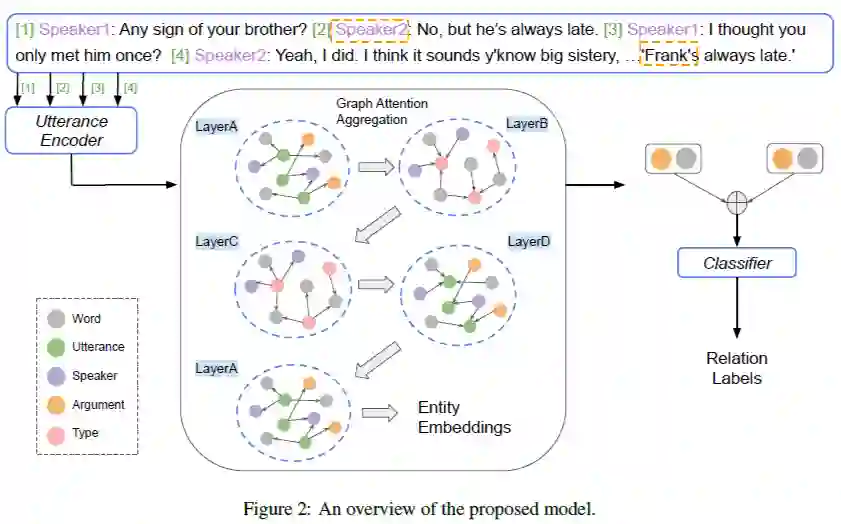
在这项工作中,论文引入了一个基于注意的图网络来解决每个对话都被表示为异构图的问题。
1. 首先利用一个由两个双向长短期记忆网络组成的语音编码器对会话信息进行编码。这些话语编码,连同单词嵌入、说话者嵌入、论点嵌入和类型嵌入,在逻辑上连接起来,形成一个异构。
2. 该图通过五个图注意层,这些注意层聚合了来自邻近节点的信息。
3.2.1 Utterance Encoder
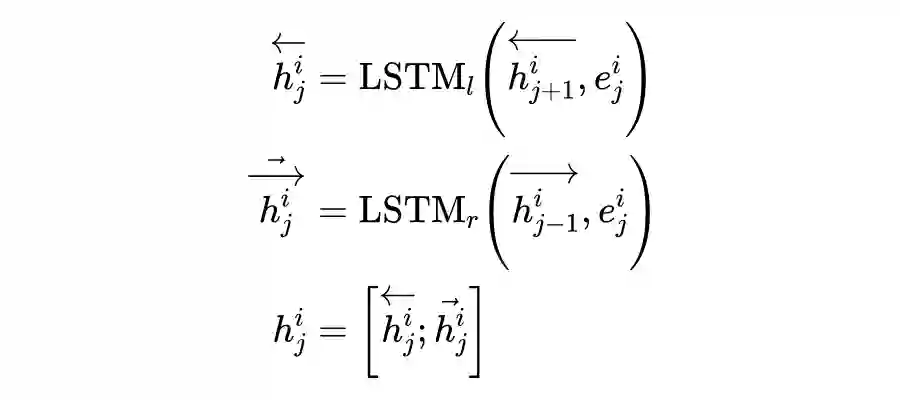
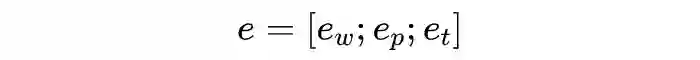
3.2.2 Graph Construction
论文设计了一个包含五种节点的异构图网络:话语节点(utterance nodes)、类型节点(type nodes)、词节点(word nodes)、说话者节点(speaker nodes)和参数节点(argument nodes)。每种类型的节点用于在对话框中编码一种类型的信息。在该任务中,只有词节点、说话者节点和论点节点可能会参与最终的分类过程。
话语节点是由 Utterance Encoder得到的话语嵌入初始化的,与构成话语的基本节点相连。类型节点表示话语中单词的实体类型,其中包括各种命名实体和数字实体,由于在一个对话中可能有不同的类型,类型节点可以促进信息集成。
单词节点表示会话的词汇表。每个单词节点都与包含单词的话语相连接,它也与单词在对话中可能存在的所有类型相连接,论文使用 GloVe 初始化单词节点的状态。
说话人节点表示对话中每个唯一的说话人。每个说话人节点都与说话人自己发出的话语相连接。这种类型的节点是用一些特定的嵌入进行初始化的,可以从不同的说话者那里收集信息。
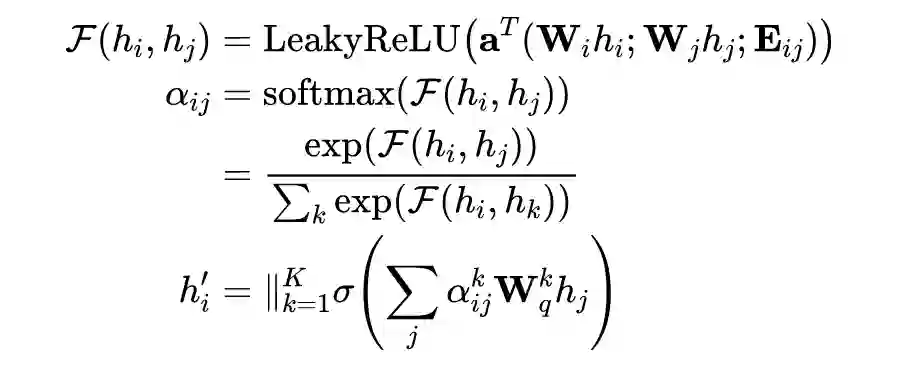
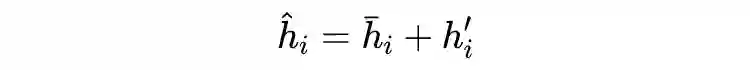
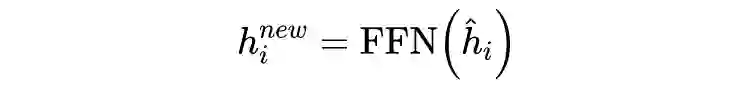

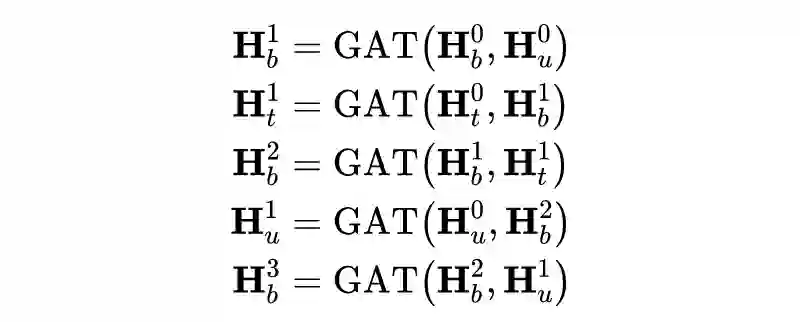
3.2.3 Relation Classifier
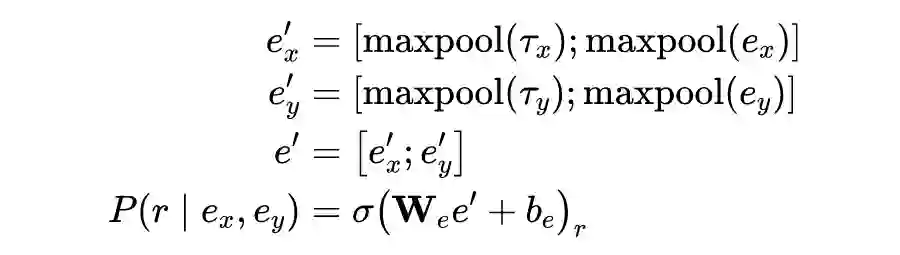
3.3.1 Dataset
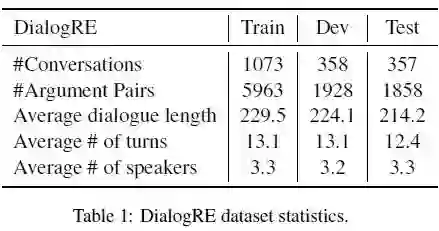
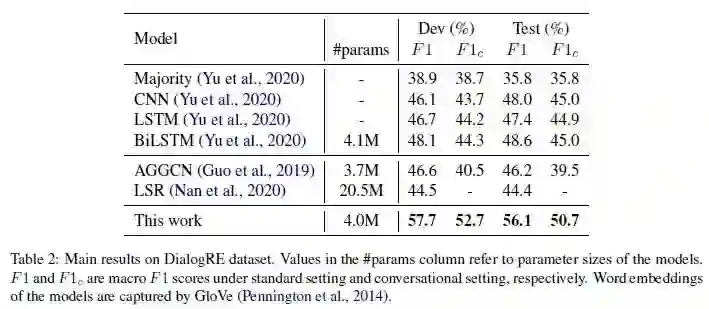
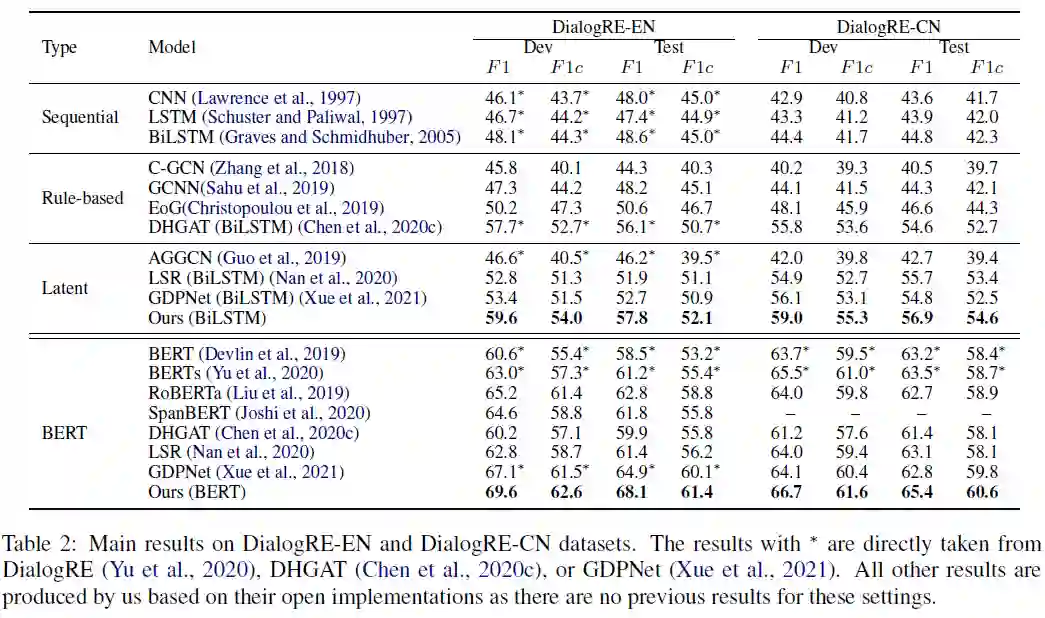
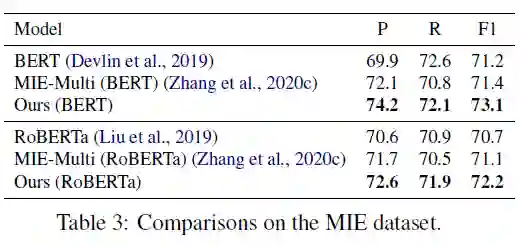
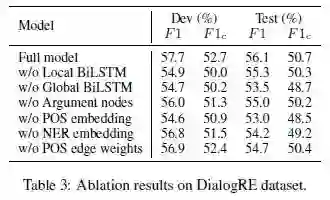
为了理解模型组件的影响,论文使用模型在 DialogRE 数据集上执行 ablation study,结果见表 3。
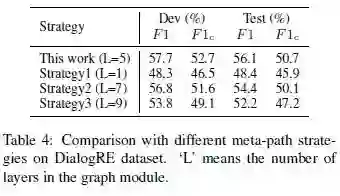
论文还通过更改元路径策略来测试消息传播策略的性能,
Strategy1:作者只建立了一个 LayerA,其中基本节点由初始化的话语节点更新一次。
Strategy2:层的顺序是 A-B-C-D-A-D-A。

总结
特别鸣谢
感谢 TCCI 天桥脑科学研究院对于 PaperWeekly 的支持。TCCI 关注大脑探知、大脑功能和大脑健康。
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧