本文转载自公众号:PaperWeekly。作者:王文博,哈尔滨工程大学硕士生,研究方向为知识图谱、表示学习。
![]()
动机
在本篇文章之前,跨语言知识图谱对齐研究仅依赖于从单语知识图谱结构信息中获得的实体嵌入向量。并且大多数研究将实体映射到低维空间中,用低维向量对多语言知识图谱中的实体进行编码。并学习相似得分函数,根据实体映射后的低维向量表示对其进行匹配。但是又由于一些实体在不同的语言中具有不同的三元组事实,实体嵌入中编码的信息可能在不同的语言中是不同的,这使得基于传统思想的方法很可能无法完成这类实体的匹配任务。
除此之外,传统方法也没有将实体的表面结构信息编码到嵌入向量中,使得具有少量邻居的实体由于缺乏足够的结构化信息而无法匹配。
故
本文提出一种新颖的图匹配方法
,通过两次运用图卷积神经网络(GCN)分别解决构建主题实体图时相邻实体间信息传递的问题,与构建全图表示向量时局部信息的传递问题,十分出色地完成了知识图谱中实体对齐的问题。
主题实体图
由于知识图谱中实体的上下文信息对于知识图谱对齐任务十分重要,在本文模型中引入主题实体图的结构,用来表示知识图谱中给定实体(话题实体)与它的邻居之间的关系。图二为主题图的样例。为了构建主题图,先建立与主题实体一跳相邻的邻居实体集合,用![]() 表示。
然后从这个集合中任意选取两个实体对
表示。
然后从这个集合中任意选取两个实体对![]() ,若这
个实体对在知识图谱中存在关系使其直接相连,则在主题实体图中为这个实体对保留直接相连的有向边。
注:在主题实体图中只保留边的方向,不包含边对应的关系的具体信息。
只有这样才可以使得模型具有较高的效率和较好的表现结果。
,若这
个实体对在知识图谱中存在关系使其直接相连,则在主题实体图中为这个实体对保留直接相连的有向边。
注:在主题实体图中只保留边的方向,不包含边对应的关系的具体信息。
只有这样才可以使得模型具有较高的效率和较好的表现结果。
图匹配模型
图 2 给出了本文模型在对齐英文知识图谱与中文知识图谱中实体 LebronJames 的大体过程。首先分别构建出在两个知识图谱中的主题实体图分别为 G1 和 C2。然后用提出的图匹配模型去评估两个主题实体图是在描述同一个主题实体的可能性。匹配模型具体包含以下三层:
输入表示层:这层的目的是通过 GCN 学习出现在主题实体图中的实体嵌入向量。
以生成实体 v 的嵌入向量为例,具体步骤如下:
1. 首先用一个基于单词的 LSTM 将图中所有实体从名字转化成向量,进行初始化。并用符号![]() 表示实体 v 的初始化嵌入向量。
表示实体 v 的初始化嵌入向量。
2. 对实体 v 的邻居实体进行分类,若该邻居实体通过指向实体 v 的边与 v 相连,则该实体属于集合![]() ,若该实体通过指向自己的边与实体 v 相连,则该实体属于集合
,若该实体通过指向自己的边与实体 v 相连,则该实体属于集合![]() 。
。
3. 通过运用一个聚合器,将指向实体 v 的所有邻居节点的表示![]() 转化成一个单独的向量
转化成一个单独的向量![]() ,其中 k 是迭代值。该聚合器将与节点 v 直接相邻的所有节点的向量表示,作为一个全连接层神经网络的输入,并运用一个均值池化操作来捕捉邻居集合中的不同方面特征,得到向量
,其中 k 是迭代值。该聚合器将与节点 v 直接相邻的所有节点的向量表示,作为一个全连接层神经网络的输入,并运用一个均值池化操作来捕捉邻居集合中的不同方面特征,得到向量![]() 。
。
4. 将 k-1 轮得到的指向实体 v 的邻居集合的表示![]() 与新产生的
与新产生的![]() 进行连接,并将连接后的向量放入全连接网络去更新指向实体 v 的邻居集合的表示,得到
进行连接,并将连接后的向量放入全连接网络去更新指向实体 v 的邻居集合的表示,得到![]() 。
。
5. 用与步骤(3)步骤(4)相同的方法在由实体 v 指出的邻居集合中更新由实体 v 指出的邻居集合的表示![]() 。
。
6. 重复步骤(3)-步骤(5)K 次,将最终的指向实体 v 的邻居集合的表示与由实体 v 指出的邻居集合的表示进行连接,作为单个实体的嵌入向量。最终得到两组实体的嵌入向量的集合分别为![]() 和
和![]() 。
。
在本层中,如图(2)所示,作者运用一个注意匹配方法将一个主题实体图的每个实体嵌入向量与另一个主题实体图的所有实体嵌入向量分别按照从 G1 到 G2 的顺序与从 G2 到 G1 的顺序进行比较。首先计算 G1
中实体![]() 与 G2 中所有实体
与 G2 中所有实体![]() 的 cosine 相似值。
的 cosine 相似值。
![]()
然后,我们用这些相似点作为权重并通过对 G2 中所有实体嵌入向量加权求和的方式来计算整个图的关注向量。
![]()
通过对每一步匹配运用多角度 cosine 匹配函数![]() 计算 G1 与 G2 中所有实体的匹配向量。
计算 G1 与 G2 中所有实体的匹配向量。
![]()
其中匹配函数![]() 具体如下:
具体如下:
![]() 是一个用于比较两个向量的多角度 cosine 匹配函数:
是一个用于比较两个向量的多角度 cosine 匹配函数:
![]()
其中,v1 与 v2 表示两个维度为 d 的向量,![]() 是一个可训练参数,l 是角度的数量,返回的 m 值是一个 l 维向量 m=
是一个可训练参数,l 是角度的数量,返回的 m 值是一个 l 维向量 m=![]() 。元素
。元素![]() 是从第 k 个角度得到的匹配值。这个匹配值是通过计算两个权重向量的 cosine 相似得到的。
是从第 k 个角度得到的匹配值。这个匹配值是通过计算两个权重向量的 cosine 相似得到的。

符号 ° 表示对应元素相乘,Wk
表示矩阵 W 的第 k 行。Wk 控制着第 k 个角度,并为 d 维空间中不同的维度分配不同的权重。
图(全局)匹配层:这些匹配向量捕获了 G1 (G2) 中的每个实体如何被另一种语言的主题图匹配。
但是这种匹配只处于局部匹配阶段,不足以对图进行全局相似性计算。例如,有的实体在 G1 与 G2 中均几乎没有邻居实体。对于这种情况,仅进行局部信息的匹配很可能会将这两个本应对齐的实体判定为两个不同的实体。
为了解决上述问题,运用另一个 GCNs 使得局部信息可以在图中进行传播。直观地说,如果每个节点都表示为自己的匹配状态,那么通过在图上设计一个具有足够大的跳数的 GCN,就能够在整个图的对之间编码全局匹配状态。将上述所得的局部匹配结果向量输入到一个全连接神经网络中,并用 max pooling 或 mean pooling 生成一个合适长度的图匹配表示。
将图匹配表示作为一个双层前馈神经网络的输入,并在其输出层运用 softmax 函数。
为了训练模型,作者运用启发式方法对每个正确对齐的实体对![]() 随机构建 20 个错误案例。也就是说首先通过对每个实体表面形式中预先训练的词的嵌入向量加和粗略生成 G1 和 G2 的实体嵌入向量。然后再粗略的在其嵌入空间中选取 10 个与实体
随机构建 20 个错误案例。也就是说首先通过对每个实体表面形式中预先训练的词的嵌入向量加和粗略生成 G1 和 G2 的实体嵌入向量。然后再粗略的在其嵌入空间中选取 10 个与实体![]() 最近的实体,10 个与实体
最近的实体,10 个与实体![]() 最近的实体构建错误案例实体对。在测试过程中,当给定一个
G1
中的实体时,根据本文模型评估出的匹配可能性对
G2
中的所有实体进行可能性值的计算,并按降序对计算结果进行排序。
最近的实体构建错误案例实体对。在测试过程中,当给定一个
G1
中的实体时,根据本文模型评估出的匹配可能性对
G2
中的所有实体进行可能性值的计算,并按降序对计算结果进行排序。
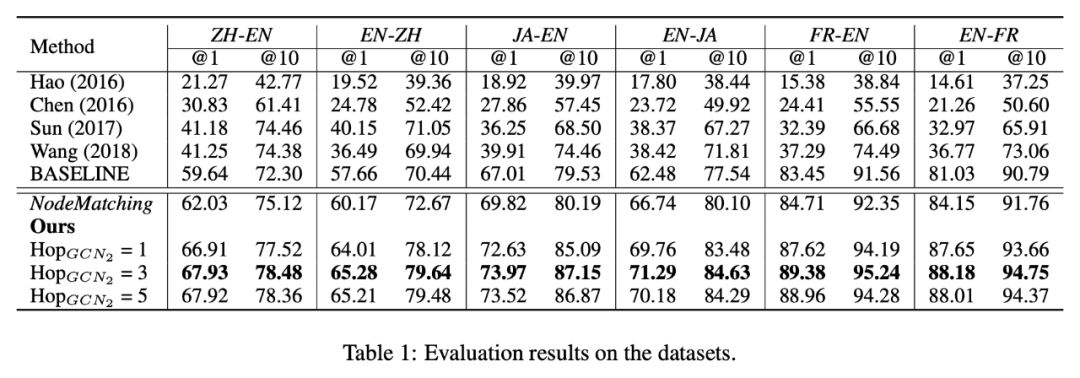
实验
在数据集 DBP15K 上对模型进行评估。这些数据集是通过将汉语、日语以及法语版本的 DBpedia 中的实体与英语版本的 DBpedia 中的实体进行连接得到的。每个数据集包含 1500 个内部语言连接,即在两种不同语言的知识图谱中对等实体的连接。
本实验中采用 Adam 优化器更新参数,最小批尺寸设置为 32。学习率设置为 0.001。GCN1 与 GCN2 最大跳数 K 分别设置为 2 和 3。非线性函数 σ 设置为 ReLU。聚合器的参数是通过随机初始化得到的。由于用不同的语言来表征指示图谱,本文首先用 fastText 嵌入方法对单一语言的知识图谱进行嵌入处理,并运用交叉语言词汇嵌入方法将这些嵌入向量在同一个向量空间进行对齐。用这些对齐后的向量作为 GCN1 第一层输入的初始化单词表示向量。
![]()
本文中运用指标 Hits@1 与 Hits@10 对模型评估,其中 Hits@k 表示与某一实体正确对齐的实体排在前 k 个的比重。在跨语言嵌入空间中选择 k 个最接近给定 G1 实体的 G2 实体,并令其中实体嵌入是单词在其表面形式中的嵌入向量之和,以此作为本实验中的 BASELINE。NodeMatching 则是将通过 GCN1
得到的两个话题实体的嵌入向量不经过匹配层直接传入预测层。
从表 1 可以看出,即使不考虑知识图谱中具有的结构化信息,BASELINE 的结果仍然超过了之前从结构化的知识图谱中主要学习了实体嵌入向量的方法得到的结果。因此可以表明在知识图谱对齐任务中,表面形式是一个重要特征。NodeMatching 又通过使用 GCN1 将知识图谱中的结构化信息编码到实体嵌入向量中,得到了比 BASELINE 更好的结果。最后 GraphMatching 又通过将话题实体的全局上下文信息考虑其中,使其超过了所有方法。
本文还分析了 GCN2 的跳数对模型的影响。从表中结果可以看出,模型会随着 GCN2 的跳数增大而获得更好的结果,直到跳数达到某个阈值 λ,在实验中作者发现当 λ=3 时模型效果最好。
为了更好地理解由于引入了图匹配层,本文的模型可以更好地处理哪种类型的实体,进而分析了本文模型正确预测而 NodeMatching 没有正确预测的实体。经过分析作者发现,图匹配层加强了模型处理在两个知识图谱中最近邻居不同的实体的匹配能力。对于这种实体来说,尽管更多的局部信息表明这两个实体不相关,但是图匹配层可以通过传播图中最相关的局部信息来缓解这种问题。
本文中提出的主题实体图只保留了关系方向,而忽略了关系标签。在实验中,作者发现将关系标签合并为不同的节点会将实体节点连接到主题图中,这不仅会影响模型的性能,还会降低模型的效率。作者认为出现上述情况可能是由于以下两点原因造成的:
总结
本文通过引入图卷积神经网络,极大地提高了跨语言知识图谱中实体对齐的准确性。本文的亮点之处主要体现在以下三点:
本文提出了主题实体图的构建,实现了相邻实体间的信息传递,使得由此方法得到的每个节点向量包含了其多跳邻居的信息,最大可能地保留了知识图谱的结构化信息。并成功地将实体对齐问题转化为图匹配问题。
本文运用图卷积神经网络构建图匹配模型,在图匹配层运用多角度余弦匹配函数计算相似性,并通过实验论证了图匹配层在本文模型中的重要性,也说明了不仅上下文的局部信息对实体对齐效果有巨大影响,全局信息对实体对齐任务同样十分重要。
本文验证了对知识图谱中关系信息的处理仅保留其方向而忽略其标签具体内容有助于提高模型的效率与准确性的结论。
![]()
OpenKG
开放知识图谱(简称 OpenKG)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。
![]()
点击阅读原文,进入 OpenKG 博客。

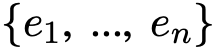 表示。
然后从这个集合中任意选取两个实体对
表示。
然后从这个集合中任意选取两个实体对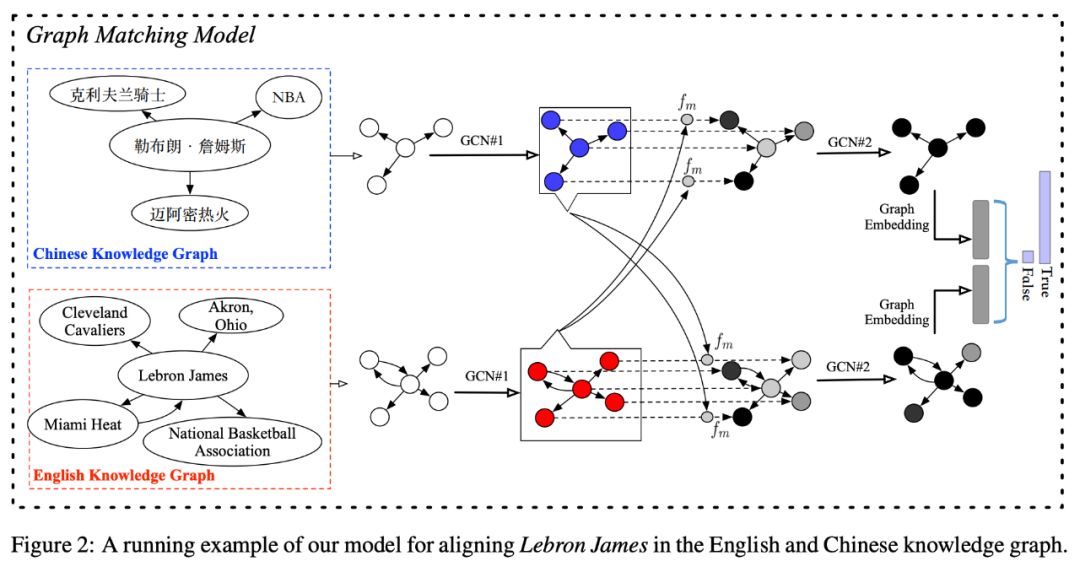
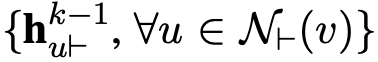
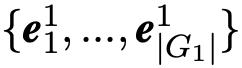
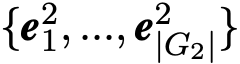
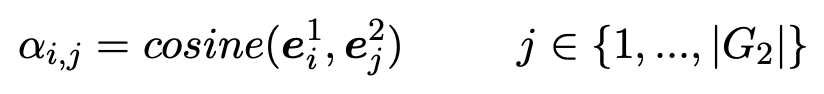
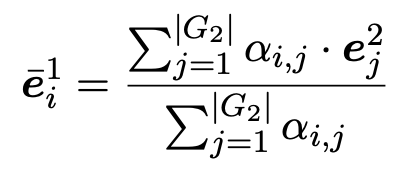
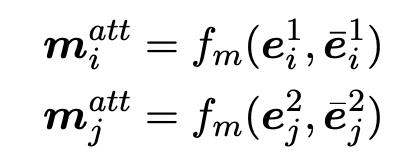
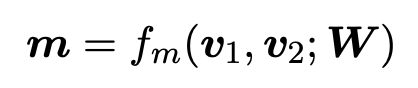
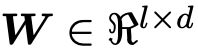
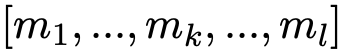
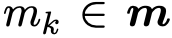
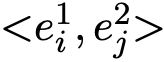 随机构建 20 个错误案例。也就是说首先通过对每个实体表面形式中预先训练的词的嵌入向量加和粗略生成 G1 和 G2 的实体嵌入向量。然后再粗略的在其嵌入空间中选取 10 个与实体
随机构建 20 个错误案例。也就是说首先通过对每个实体表面形式中预先训练的词的嵌入向量加和粗略生成 G1 和 G2 的实体嵌入向量。然后再粗略的在其嵌入空间中选取 10 个与实体