PointRend:用经典渲染技术实现最先进的图像分割
【导读】本文介绍一种新型高效的高分辨率图像分割方法PointRend,其灵感来自计算机图形渲染中使用的经典自适应采样技术。与以前的最新方法相比,它可以对对象和场景进行更清晰,更准确的分割。
现代图像分割方法基于卷积神经网络,该算法在输入图像上平均分配计算量。通常,为了降低计算的复杂性,这些方法都使用更粗糙的分辨率。这些方法将大部分计算量花费在图像的明确区域(如狗的躯干或背景)上,而会对物体更具挑战性的部分进行欠采样,从而丢失了诸如狗爪子或物体边缘之类的细粒度细节。

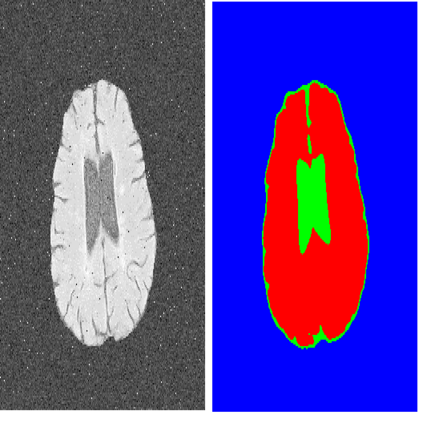
使用标准Mask R-CNN分割(左)和PointRend(右)进行实例分割。 定性地,PointRend在先前方法过度平滑的区域中输出清晰的对象边界。
收到计算机图形渲染的经典自适应细分技术的启发,PointRend模块在自适应选择的位置执行基于点的分段预测。它有效地产生了像素级精度的分割,这是使用以前的最佳细分方法(例如Mask R-CNN或语义FPN)无法实现的。
PointRend在实例和语义分割任务这两个主要的任务上获得了可观的提升。通过PointRend分割头增强的Mask R-CNN可以生成比标准Mask R-CNN模型输出高8倍的掩码,将平均精度提高多达2.8%。
工作原理
PointRend方法建立在现有图像分割方法(例如Mask R-CNN,语义FPN和Deeplab)的基础上,首先有效地产生粗略预测。从粗略的全局预测开始,PointRend逐步放大并完善了预测,仅需几个步骤即可达到输入图像的分辨率。
在每个步骤中,PointRend都会在需要改进的预测中选择位置子集。对于这些位置中的每个位置,新模型都使用来自基础卷积神经网络的中间特征独立地更新其预测。
总体而言,该方法允许研究人员获得高分辨率的分割,同时仅对输入图像中总像素的一小部分进行实际预测。PointRend避免在粗略预测可以完美预测的区域上使用过多的计算。同时,它优化了对位于对象或场景具有挑战性区域中的像素的预测。
与现有方法相比,PointRend的效率可实现在内存或计算方面不可行的输出分辨率。借助更少的内存和计算约束,我们可以将图像分割模型部署到较小的设备和资源不足的区域。完美的像素分割还可以增强以前受限的各种AR / VR体验,例如无缝转换背景或在场景中插入更精确,逼真的对象。

代码实现:
https://github.com/facebookresearch/detectron2/tree/master/projects/PointRend
训练
cd /path/to/detectron2/projects/PointRendpython train_net.py --config-file configs/InstanceSegmentation/pointrend_rcnn_R_50_FPN_1x_coco.yaml --num-gpus 8
评估
cd /path/to/detectron2/projects/PointRendpython train_net.py --config-file configs/InstanceSegmentation/pointrend_rcnn_R_50_FPN_1x_coco.yaml --eval-only MODEL.WEIGHTS /path/to/model_checkpoint
论文:
https://research.fb.com/publications/pointrend-image-segmentation-as-rendering/
原文链接:
https://ai.facebook.com/blog/using-a-classical-rendering-technique-to-push-state-of-the-art-for-image-segmentation/