DensePose:将2D图像像素映射到人体3D表面以实现高效姿态估计
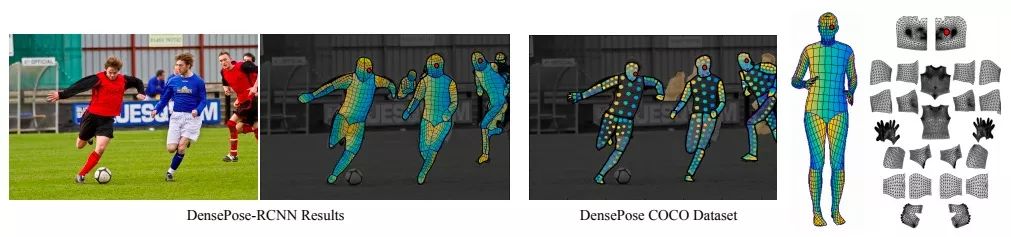
编者按:近日,FAIR研究员Natalia Neverova、Iasonas Kokkinos和法国INRIA的Rıza Alp Guler发表了一项令人惊艳的CV成果:DensePose: Dense Human Pose Estimation In The Wild,即用深度学习把2D RPG图像坐标映射到3D人体表面上,再加上以每秒多帧的速度处理密集坐标,最后实现动态人物的精确定位和姿态估计。
在论文中,研究人员称这项工作需要在人体3D模型和2D图像之间构建密集的映射,它能帮助人们进一步理解二维三维关系,可以被看作是集对象检测、姿态估计、目标部分/实例分割(part and instance segmentation)等多种计算机视觉任务于一身的一个综合问题。通过解决这个问题,我们有望将这类技术应用于AR、VR、人机交互等一系列现实场景,并抛砖引玉,开启一条理解3D物理模型的新道路。
这项成果可分为两部分,一是DensePose COCO数据集,二是DensePose-RCNN。其中前者是一个包含了超过5万张图像的数据集,它的图像来自COCO,并经工作人员手动标记;而后者是何凯明Mask-RCNN的一个变体,它沿用了Mask-RCNN的分割掩码和ROI层实现像素对齐,在RoiAlign上引入一个全卷积网络,对像素进行分类。此外,研究人员还介绍了团队在“修复”被遮挡部位的一些实验,通过引入一个“教师”网络,DensePose-RCNN能无视服装等遮挡物,成功实现姿态估计和相关动作捕捉。
DensePose COCO数据集
优秀的项目始于合格的数据集,研究人员收集了5万张人类图像,并手动在上面构建了超过500万个对应关系。由于要建立的是二维RGB图像到三维立体模型的密集对应,一种传统做法是找到图像上的一个点,然后旋转图像和立体模型来实现精确坐标定位,但这样做效率太过低下。因此他们把标记工作分成两个阶段:先进行宏观的部位分割,再进行具体的对应注释。
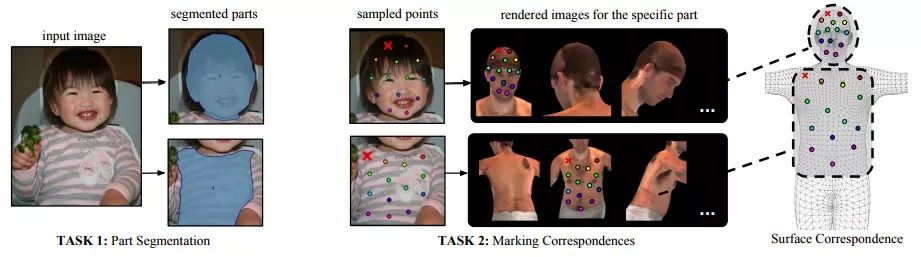
如上图所示,在标记工作的第一个阶段,标记者根据语义定义把人体分成各个部位,如头、躯干、上肢、下肢、手、脚等。为了简化UV坐标参数设置,他们把人体的上下肢和躯干的前后部分类比飞机模型,因此即便目标穿了一条大裙子,它也不会在后期出现复杂注释。
在第二阶段,标记者用了一组大致等距的点对每个部分区域进行采样,并严格对应到3D模型上。同样的,为了简化操作,他们用6个不同角度的二维图像代替旋转,允许标记者选择任意一个图放置对应点。
这样做的优势是当他们在渲染后的图上任意选择一点后,它的表面坐标也能同时用于显示其在全图中的具体位置,也就是说能反映图像的全局。而由于这些点是以水平/垂直序列呈现的,当转成3D时,它们也不会出现自我交叉的问题,这有助于研究人员更高效地收集复杂特征。

标记可视化:图像(左)、U坐标(中)、V坐标(右)
DensePose-RCNN
有了数据集,之后就是建立一个可以预测密集像素之间对应关系的深层神经网络。研究人员在这里结合了DenseReg的方法与Mask-RCNN的架构,一方面继续以全卷积的方式估计对应关系,另一方面通过卷积的像素对齐来使用掩码提取空间结构。
DensePose-RCNN与DenseReg类似,通过划分表面来查找密集对应的策略。对于每个像素,它会确定以下两点:
它属于哪块表面;
它对应部分的二维校正。
下图是这一过程的具体图解。
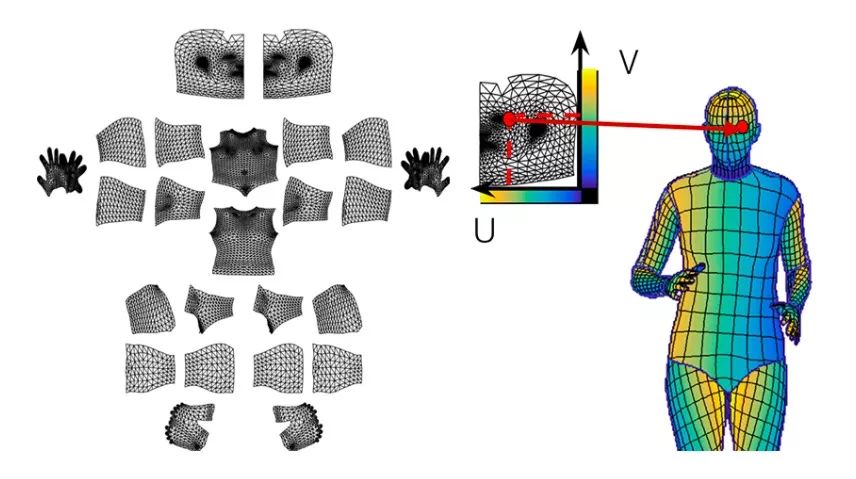
具体来说,就是他们使用了完全卷积网络(FCN),并像DenseReg一样在这个基础上结合了分类和回归任务。首先,神经网络系统会将像素全部归类为背景,或者几个身体部位中的一个,提供表面坐标的粗略估计。这相当于使用标准交叉熵loss进行训练的标签任务。其次,网络中的回归系统会显示部位中所包含像素的真实坐标。由于人体结构复杂,他们将其分解成多个独立的表面,并用局部的二维坐标系对每个表面进行参数化,以此识别该区域上各个节点的位置。
虽然FCN十分容易训练,但因为涉及密集像素,如果系统要同时做到确定坐标和分割对象,并保证结果不变形,这不太现实。因此研究人员受Mask-RCNN启发,希望能用ROI为特定目标提取特征。
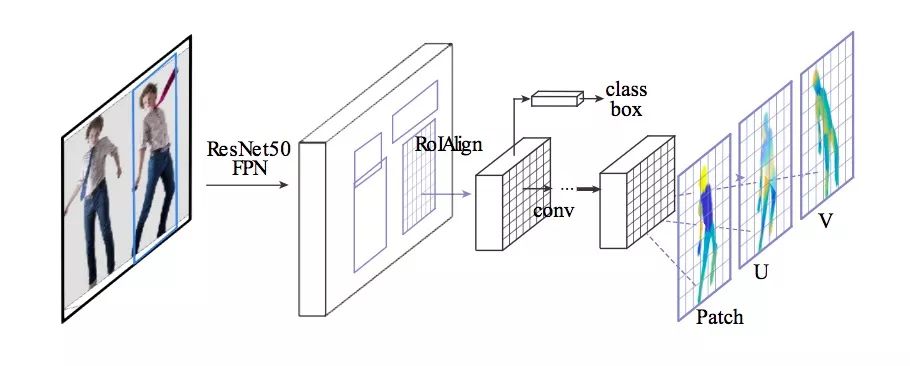
如上图所示,本身Mask-RCNN的RoiAlign前就有一个FCN,研究人员把它换成了我们之前介绍的那个类DenseReg网络,用来提供分类信息,即通过分类回归确定身体部位分类和预测坐标所属部位。可以发现,FCN以下的架构则和Mask-RCNN完全一致。
在用GTX1080做inference过程中,如果DensePose-RCNN处理的是320x240的图像,它的帧数可以达到25fps;如果是800x1100的图像,帧数也有4—5fps。
一些实验
最后,既然要实现姿态估计,遮挡是一个不得不面对的问题。DensePose-RCNN可以直接用标记的点进行监督学习,但是研究人员通过对原本未标记的信号做了一些“修补”处理后,发现新的方法可以取得更好的效果。
他们的做法很简单,就是采用了一种基于学习的方法,建立一个“教师”网络:一个基于原尺寸和身体部位分割蒙版重建对象真值的完全卷积神经网络(如下图所示)。
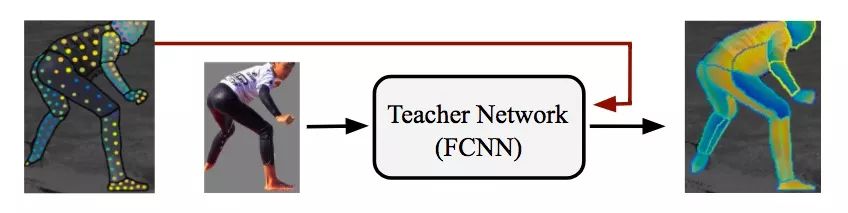
他们用级联策略进一步提高了系统的性能。Mask-RCNN架构允许利用相关任务的信息,如关键点估计和实例分割,再加上级联,这就意味着他么能实现任务协同和多种监督来源的互补。

论文地址:arxiv.org/pdf/1802.00434.pdf
数据集(即将开源)地址:densepose.org/



