超英伟达A100,IBM宣布全球首个7nm训练推理节能芯片,登上顶会ISSCC 2021

来源:机器之心
在AI计算机训练与推理领域,存在着这样一种理念:如果计算需求很大,那么为其提供动力所需的能量也将很大。这种理念也被该领域广泛接受。那么有没有可能开发出一种既可以显著提升计算能力又无需消耗过多能量的方法呢?IBM在顶会ISSCC上介绍了一种7nm训练推理节能芯片。
自动驾驶汽车、文本转语音和送货无人机,这些都是人工智能的典型应用。为了不断推动 AI 淘金热,人们一直致力于改善 AI 硬件技术的核心,即赋能深度学习的数字 AI 内核,它是人工智能的关键推动力。

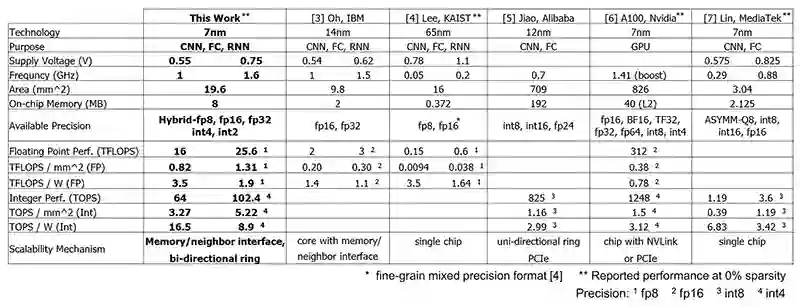
图 2:该研究与其他工作的数据对比。
点击阅读原文,查看更多精彩!
登录查看更多
相关内容

专知会员服务
21+阅读 · 2020年4月30日
专知会员服务
61+阅读 · 2019年12月29日




相关VIP内容
专知会员服务
21+阅读 · 2020年4月30日
专知会员服务
61+阅读 · 2019年12月29日
相关资讯
相关论文