【泡泡图灵智库】基于语义分割图像的长期视觉定位(ICRA)
泡泡图灵智库,带你精读机器人顶级会议文章
标题:Long-term Visual Localization using Semantically Segmented Images
作者:Erik Stenborg Carl Toft Lars Hammarstrand Chalmers University of Technology
来源:ICRA 2018
编译:张珊珊
欢迎个人转发朋友圈;其他机构或自媒体如需转载,后台留言申请授权

摘要

大家好,今天为大家带来的文章是——Long-term Visual Localization using Semantically Segmented Images,该文章发表于ICRA 2018。
鲁棒的跨季节定位是自动驾驶长期视觉导航的重要挑战之一。在本文中,我们利用图像语义分割(每个像素被赋予一个它所属物体类别的标签)的最新进展来解决长期视觉定位问题。我们表明,在无需使用具体的特征描述子(SIFT、SURF等)的情况下,语义标记的三维环境地图以及语义分割的图像可以有效地用于车辆定位。因此,我们不依赖手工制作的特征描述子,而是依赖于图像分割器的训练。本文方法生成的地图与基于传统描述子的方法相比节省了大量的存储空间。基于粒子滤波的语义定位方案与基于SIFT特征的定位方案相比,即使在一年中季节性变化较大的情况下,我们也能与更大、更具描述性的SIFT特征相媲美,并且大多数情况下能够在低于1 m的误差下进行定位。
主要贡献
1.本文提出一种基于语义类别作为地图点描述子的定位方案, 在解决长时间跨季节定位时相比于传统描述子具有更高的精度。
算法流程
本文解决的问题是在已有的3D地图上进行定位,传统方法是基于特征匹配进行的,但是在自动驾驶的应用场景下,当前检测的特征和保存的地图特征一般具有很大的时间跨度,而普通的特征不具有鲁棒性,所以本文提出了一种依赖于语义标签和3D位置的定位算法。
本文对基于SIFT特征和基于语义特征定义了统一的观测模型:
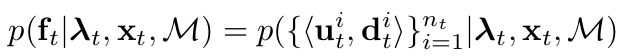
ft表示当前图像,xt表示相机的位姿,M表示已知的地图,公式中将图像ft 表示为(ut,dt)的集合,即图像是由图像中所有的特征点及其描述子构成的,对于SIFT来说,就是图像中所有的SIFT特征点及计算出来的描述子,对于语义特征来说,特征是图像中所有的像素,描述子是每个像素对应的语义标签(因为语义分割可以获取图像中所有像素的语义标签),所以语义特征的图像是稠密的。
λ t 表示图像上的特征点和地图中的地图点之间的数据关联,下面公式表示当前图像第i个特征点对应地图中的第j个地图点,如果j>0表示地图中存在一个地图点和该特征点对应,如果j=0表示当前特征点没有对应的的地图点:
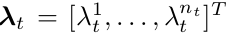
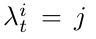
数据关联的获取对于SIFT特征和语义特征有差别。对于SIFT来说,首先获取地图M中位于当前相机位姿xt视角下的局部地图Ms,将局部地图中的点和图像特征进行匹配,包括使用RANSAC方法得到更准确的匹配关系作为数据关联;对于语义特征来说,同样获取当前相机视角下的一个局部地图Ms,将Ms中的每个点都投影到当前图像上,因为当前图像是稠密的,每一个像素都是特征点,所以可以直接建立数据关联,即地图点和投影点之间的对应。需要注意的是:有的图像像素没有对应的地图点,即 λ t =0的情况。
本文假设ut和dt相互独立,所以将观测模型的概率分为两项的乘积:
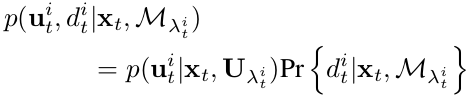
上式第一项的意义为在像素i位置检测到特征点的概率,由于语义图像上每一个像素点都是特征,所以该项是一个常数。可以将概率化简为:
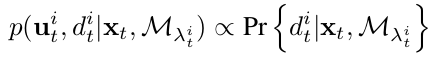
这里存在两种情况:λit = 0,特征点没有对应的地图点,λit > 0 特征点有对应的地图点。
对于第一种情况,我们无法从地图中得到关于该特征点类别的信息,所以将特征点类别的分布假设为在所有类别上的边缘分布:
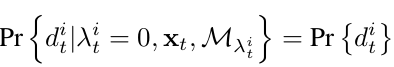
对于第二种情况, 特征点有对应的地图点,所以写成在已知对应的地图点类别的条件下特征点的类别概率分布。但是该地图点可能被遮挡,所以引入一个检测概率:δ=1,未遮挡;δ=0,遮挡。将分布概率改写成下面形式:
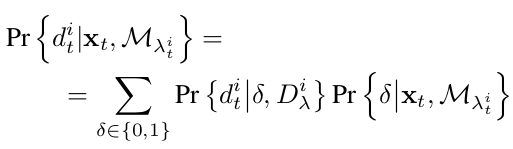
上述公式中,第一项表示对应地图点可见或者被遮挡下的特征点的类别概率,第二项表示对应的地图点可见或被遮挡的概率,公式不列出了。
语义的观测模型的意义在于通过位姿的调整使得图像中像素点类别和对应的地图点类别尽可能多的一致。在定义了运动模型和观测模型后,利用粒子滤波实现定位。

图一,基于语义类别的定位算法流程
主要结果
1、基于语义的描述子与基于传统SIFT描述子相比节省了大量的存储空间。无论是哪种描述子, 都需要描述地图点的位置和观测次数。
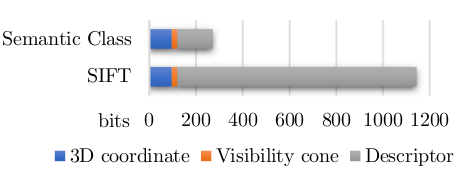
图二,两种描述子描述每个地图点所需的存储空间对比
2、本文提出的语义定位方法具有更高的长期定位精度。如下图所示, 柱状图中的每根柱子表示对应时间下11次运行的误差。越高的柱子意味着更多的样本在标注的误差范围内被成功地定位,因此定位效果更好。
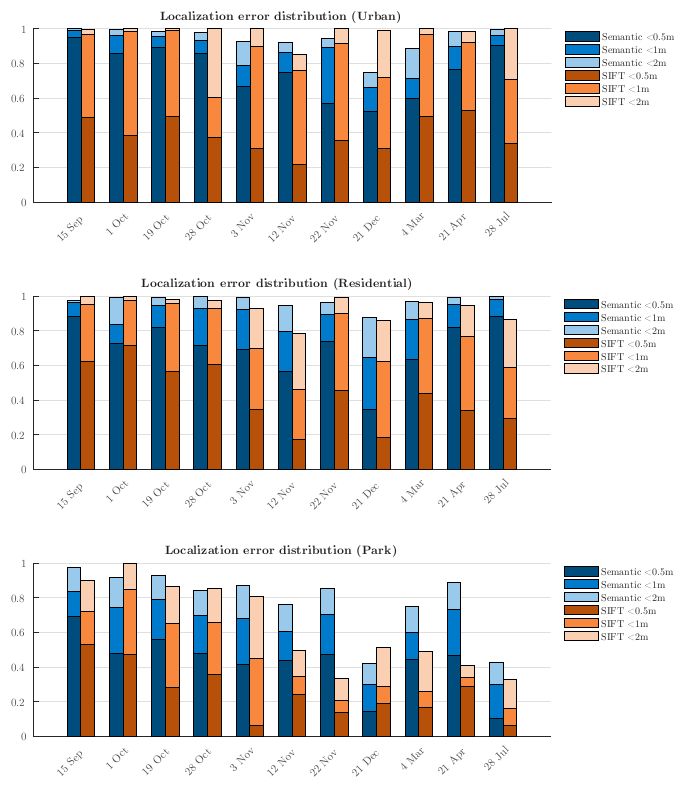
图三,三种环境类型下的定位误差
另外, 本文分析了两种描述子产生定位误差的可能原因。语义描述子产生误差的第一个原因是3D点和图像中对应像素类别不一致, 可能因为3D点和图像像素别误分类导致。如图四所示, 道路旁边的地形通常被错误地分类为道路或植被,当地面被雪覆盖时这种情况更常见,如12月的序列。

图四,语义定位失败的场景的语义分割图像
语义描述子产生误差的第二个原因是场景的单一性。在一些路边只有单一类别的道路上,例如高墙或高大的森林,分割的图像看起来非常相似,无论图像是沿着道路在哪里拍摄的。
SIFT描述子产生误差的原因是在RANSAC步骤中无法找到足够的图像和地图之间的匹配。这主要出现在“公园”区域,图像中的所有东西实际上都是植被,随着时间的推移,植被的外观会发生巨大的变化导致找不到匹配关系。

Abstract
Robust cross-seasonal localization is one of the major challenges in long-term visual navigation of autonomous vehicles. In this paper, we exploit recent advances in semantic segmentation of images, i.e., where each pixel is assigned a label related to the type of object it represents, to attack the problem of long-term visual localization. We show that semantically labeled 3D point maps of the environment, together with semantically segmented images, can be efficiently used for vehicle localization without the need for detailed feature descriptors (SIFT, SURF, etc.). Thus, instead of depending on hand-crafted feature descriptors, we rely on the training of an image segmenter. The resulting map takes up much less storage space compared to a traditional descriptor based map. A particle filter based semantic localization solution is compared to one based on SIFT-features, and even with large seasonal variations over the year we perform on par with the larger and more descriptive SIFT-features, and are able to localize with an error below 1 m most of the time.
如果你对本文感兴趣,想要下载完整文章进行阅读,可以关注【泡泡机器人SLAM】公众号。
点击阅读原文,即可获取本文下载链接。
欢迎来到泡泡论坛,这里有大牛为你解答关于SLAM的任何疑惑。
有想问的问题,或者想刷帖回答问题,泡泡论坛欢迎你!
泡泡网站:www.paopaorobot.org
泡泡论坛:http://paopaorobot.org/bbs/


泡泡机器人SLAM的原创内容均由泡泡机器人的成员花费大量心血制作而成,希望大家珍惜我们的劳动成果,转载请务必注明出自【泡泡机器人SLAM】微信公众号,否则侵权必究!同时,我们也欢迎各位转载到自己的朋友圈,让更多的人能进入到SLAM这个领域中,让我们共同为推进中国的SLAM事业而努力!
商业合作及转载请联系liufuqiang_robot@hotmail.com



