7 Papers | 李飞飞新论文;深度学习代码搜索综述;Adobe用GAN生成动画
机器之心整理
本周有李飞飞、朱玉可等的图像因果推理和吴恩达等的 NGBoost 新论文,同时还有第一个深度学习代码搜索综述论文、Adobe 用 GAN 生成角色的动画、Facebook 和 HuggingFace 推出的新代码库等。
目录:
SummAE: Zero-Shot Abstractive Text Summarization using Length-Agnostic Auto-Encoders
Causal Induction from Visual Observations for Goal Directed Tasks
When Deep Learning Met Code Search
Neural Puppet: Generative Layered Cartoon Characters
TorchBeast: A PyTorch Platform for Distributed RL
NGBoost: Natural Gradient Boosting for Probabilistic Prediction
Transformers: State-of-the-art Natural Language Processing
论文 1:SummAE: Zero-Shot Abstractive Text Summarization using Length-Agnostic Auto-Encoders
作者:Peter J. Liu、Yu-An Chung、Jie Ren
论文地址:https://arxiv.org/pdf/1910.00998.pdf
摘要:传统的序列到序列自编码器无法生成效果好的摘要,也无法描述特定的架构选择和预训练如何显著提升性能以及是否优于提取基线(extractive baseline)。在本篇论文中,谷歌大脑和 MIT 计算机科学与人工智能实验室的研究者提出一种用于段落零样本抽象文本摘要生成的端到到神经模型,并介绍了一项基准测试任务 ROCSumm,它基于包含人类摘要的子集 ROCStories。在 ROCSumm 任务上,由五个句子组成的故事(段落)被总结成一个句子,并且只使用人类摘要进行评估。研究者展示了提取和人类基线的结果,显示在抽象摘要生成方面存在很大的性能差异。他们提出的模型 SummAE 包含一个去噪自编码器,它在公共空间中嵌入句子和段落,从而这些句子和段落可以进行解码。通过从段落表征中解码句子,段落的摘要得以生成。

根据给定段落(a),人类(b)、抽取式方法(c)和论文方法(d)抽取出的摘要对比。
推荐:使用抽取式和生成式方法进行文本摘要的算法很多,而本文是一个较为少见的零样本端到端神经网络模型。同时,本文提出了一种评价文本摘要质量的方法,是一种量化评价摘要质量的标准。
论文 2:Causal Induction from Visual Observations for Goal Directed Tasks
作者:Suraj Nair、Yuke Zhu、Silvio Savarese、Li Fei-Fei
论文地址:https://arxiv.org/abs/1910.01751
摘要:在人类和其他聪明的动物与物质世界进行交互的过程中,因果推理能力一直不可或缺。在本篇论文中,李飞飞、朱玉可等研究者提出赋予人工智能体因果推理能力,以完成特定的任务。他们利用基于学习的方法来生成有向无圈图格式的因果知识,这些知识可以用于将学习到的目标条件策略(goal-conditional strategy)置于语境中,从而在具有潜在因果结构的新环境中执行任务。研究者在他们的因果判断模型和目标条件策略中利用到了注意力机制,从而可以逐渐从智能体的目视观察(visual observation)中生成越来越多的因果图,并在行动决策中有选择性地使用这些生成的因果图。实验结果表明,这种基于学习的方法可以有效地在具有未知因果结构的新环境中完成新任务。

进行因果推理过程的图示。

迭代式因果推理网络图示。
推荐:让机器从输入中获得因果信息是一个近来兴起的研究领域,而通过图像信息获取因果关系的研究较为少见。本文作者是斯坦福大学的李飞飞和朱玉可等,是一篇探索图像数据和因果推理的新论文。
论文 3:When Deep Learning Met Code Search
作者:Jose Cambronero、Hongyu Li、Seohyun Kim、Koushik Sen、Satish Chandra
论文地址:https://arxiv.org/pdf/1905.03813v3.pdf
摘要:近来,关于使用深度神经网络来进行自然语言代码搜索出现了很多建议,其中共同的观点是将代码和自然语言查询嵌入到实向量中,然后使用向量距来近似代码和查询之间的语义关联。学习这些嵌入的方法有很多,其中包括仅依赖代码实例语料库的无监督方法以及使用成对代码和自然语言描述对齐语料库的监督方法。在本篇论文中,MIT 计算机科学与人工智能实验室、Facebook 和加州大学伯克利分校电气工程与计算机科学系的研究者对这些无监督和监督方法进行了评估,结果如下:将监督方法融合现有无监督方法中可以提升性能,尽管必要性不大;代码搜索中,简单的监督网络较基于序列的更复杂网络更加有效;虽然使用文档字符串进行监督是常见的做法,但文档字符串与更适合查询的监督语料库的有效性存在巨大差异。

使用神经网络进行代码搜索的流程图示。
推荐:自然语言代码搜索是近来 NLP 研究中的一个重点领域,尽管已有很多工作取得了进展,但目前仍没有能够全面总结这一领域工作的综述。据本文作者称,这是第一篇对这一任务下的工作进行总结的论文,值得感兴趣的读者朋友阅读。
论文 4:Neural Puppet: Generative Layered Cartoon Characters
作者:Omid Poursaeed、Vladimir G. Kim、Eli Shechtman、Jun Saito、Serge Belongie
论文地址:https://arxiv.org/ftp/arxiv/papers/1910/1910.02060.pdf
摘要:近日,Adobe 和康奈尔大学的研究人员提出一种基于学习的方法,该方法可基于卡通角色的少量图像样本生成新动画。传统动画的每一帧都由艺术家绘制完成,因而输入图像缺乏共同结构、配准或标签。研究人员将动画角色的姿势变化演绎为一个层级 2.5D 模板网格的变形,并设计了一种新型架构,来学习预测能够匹配模板和目标图像的网格变形。这使得研究人员可从多样化的角色姿势集合中抽象出一种共同的低维结构。研究者将可微渲染和网格感知(mesh-aware)模型的近期进展结合起来,成功地对齐通用模板,即使训练期间只有少量卡通角色图像也能实现。除了粗糙的姿势,卡通角色的外观也会因为阴影、离面运动(out-of-plane motion)和图片艺术效果而呈现细微的差异。研究人员使用图像平移网络(image translation network)捕捉这些细微变化,以改进网格渲染结果,为生成高质量卡通角色新动画提供了一个端到端的模型。该研究提出的生成模型可用于合成中间帧,创建数据驱动的变形。其模板拟合(template fitting)步骤在检测图像配准方面的效果明显优于当前的最优通用技术。

训练网络用于生成角色动画的流程。
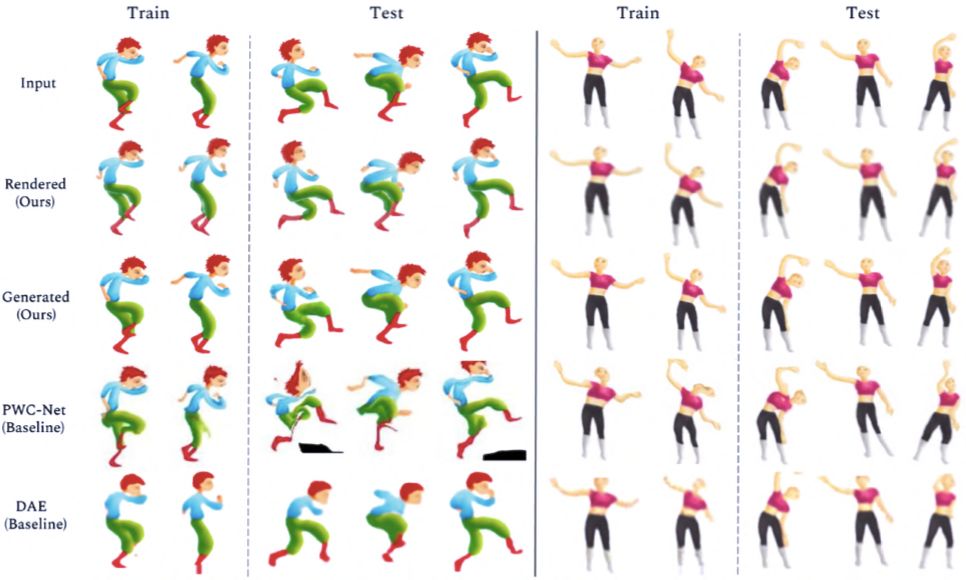

使用模型对角色图片进行处理后,生成动画的效果展示。
推荐:动画工作者的福音?本文是康奈尔大学和 Adobe 的一项工作,只需几张图片就可以生成角色的动画。从效果来看可以帮助动画原画师省去一些工作。
论文 5:TorchBeast: A PyTorch Platform for Distributed RL
作者:Heinrich Küttler、Nantas Nardelli、Thibaut Lavril、Marco Selvatici、Viswanath Sivakumar 等
论文地址:https://arxiv.org/abs/1910.03552
项目地址:https://github.com/facebookresearch/torchbeast
摘要:TorchBeast 是 PyTorch 上用于强化学习的平台。通过实现流行的 Impala 算法(其中一个版本),TorchBeast 可以对强化学习智能体进行快速、异步和并行训练。此外,TorchBeast 将朴素简洁作为自身明确的设计目标:提供纯 Python 实现版本(MonoBeast)和多机高性能版本(PolyBeast)。就 PolyBeast 版本而言,部分实现由 C++语言编写,但所有与机器学习相关的部分则通过 PyTorch 保存在简单的 Python 中,并且环境通过 OpenAI Gym 界面提供。这使得研究者无需 Python 和 PyTorch 之外的任何编程知识,即可使用 TorchBeast 进行可扩展的强化学习研究。在本篇论文中,研究者描述了 TorchBeast 平台的设计原理和实现,表明该平台的性能在 Atari 上与 Impala 持平。
推荐:本文作者来自 facebook,提出了一个新的强化学习平台,使用与 PyTorch,且可以进行快速、异步和并行训练。对强化学习感兴趣的读者朋友可以尝试下。
论文 6:NGBoost: Natural Gradient Boosting for Probabilistic Prediction
作者:Tony Duan、Anand Avati、 Daisy Yi Ding、Sanjay Basu、Andrew Y. Ng、Alejandro Schuler
论文地址:https://arxiv.org/pdf/1910.03225v1.pdf
摘要:研究者提出一种名为自然梯度提升机(NGBoost)。这是一种通用式的、将概率预测带入梯度提升中的方法。对不确定性进行预测在许多领域中都十分重要,如医学和天气预报。而概率预测——使用模型对整个输出空间进行概率分布的输出,是一种自然的量化这些不确定性的方法。梯度提升机在对许多结构化数据进行预测上取得了成功,但是一个简单的对真值输出进行概率预测的提升策略至今没有成功。NGBoost 则是一种使用自然梯度的方法,可以解决通用概率预测和现有梯度提升方法不兼容的问题。研究者提出的方法是组成式的,根据选择的基本学习器、概率分布和打分规则决定。研究者在多个回归数据集上进行了实验,说明 NGBoost 在对不确定性进行估计和传统评估计算上有着很好的预测表现。

NGBoost 的主要架构。

NGBoost 算法伪代码。
推荐:本文作者为吴恩达等,对于梯度提升机进行了进一步改进,使其可以对不确定性进行估计,这是一种新颖的算法结合的方法。
论文 7:Transformers: State-of-the-art Natural Language Processing
作者:HuggingFace Inc.
论文地址:https://arxiv.org/pdf/1910.03771.pdf
项目地址:https: //huggingface.co/transformers/
摘要:近来,基于 Transformer 架构的预训练语言模型在自然语言处理任务上取得了很好的效果。然而,这些模型对于研究者来说使用非常困难,需要针对每个模型的开源代码进行重新开发,使其能够被用于实际的工作中。本文提出了一个名为 Transformer 的项目,这是一个有着自然原因处理 SOTA 预训练模型的代码库,使用同一的 API,能够和 TensorFlow2.0 和 Pytorch 无缝结合使用。
推荐:还在为各种各样的开源预训练语言模型的代码发愁?HuggingFace 公司提出了一个统一的 Transformer 代码库,开发者可以根据需要选择语言模型进行微调。这一代码库还可以无缝和 TensorFlow、PyTorch 结合使用。




